Questões de Concurso Público IPEA 2024 para Técnico de Planejamento e Pesquisa -Ciência de Dados
Foram encontradas 4 questões
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383240
Algoritmos e Estrutura de Dados
Considere um conjunto de dados estruturados composto
por colunas, que refletem as características desses dados, e por linhas, que combinam essas características.
No tratamento desses dados, o processo de enriquecimento consiste em
No tratamento desses dados, o processo de enriquecimento consiste em
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383274
Algoritmos e Estrutura de Dados
No gráfico XY, são apresentados pontos que representam duas propriedades de elementos de duas classes, R e S. Os
pontos da classe R, representados como círculos, são [(3,5),(3,4),(2,3)], enquanto os pontos da classe S, representados
como quadrados, são [(4,3),(4,2),(4,1),(3,1),(2,2)]. É necessário classificar pontos novos, de acordo com o algoritmo K-NN,
com K=3, considerando a distância euclidiana.
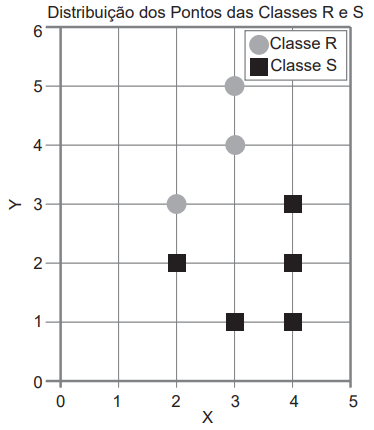
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383285
Algoritmos e Estrutura de Dados
As árvores de decisão são um modelo de aprendizado de máquina que opera por meio da construção de uma estrutura
em forma de árvore para tomar decisões e que oferece uma compreensão clara da lógica de decisão e da hierarquia de
características que contribuem para as predições finais. Elas são versáteis e podem ser usadas tanto para tarefas de
classificação quanto para as de regressão.
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
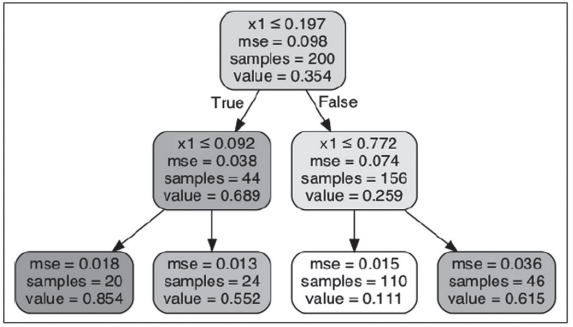
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383286
Algoritmos e Estrutura de Dados
A biblioteca Scikit-Learn emprega o algoritmo Classification And Regression Tree (CART) para treinar Árvores de Decisão.
O algoritmo CART baseia-se na recursividade e na estratégia de divisão binária para construir uma árvore de decisão.
Inicialmente, a árvore é representada por um único nó, que contém todos os dados de treinamento. A cada passo, o
algoritmo busca a melhor maneira de dividir o conjunto de dados. A recursividade continua até que uma condição de
parada seja atendida, como atingir uma profundidade máxima da árvore. Uma vez construída a árvore, a fase de predição
ocorre ao percorrer a estrutura da árvore de acordo com as condições estabelecidas nos nós, levando a uma predição
(inferência) para uma determinada entrada.
Considerando-se que n corresponde ao número de features e m ao número de instâncias, qual é a complexidade computacional assintótica de predição para árvores de decisão treinadas com o algoritmo CART?
Considerando-se que n corresponde ao número de features e m ao número de instâncias, qual é a complexidade computacional assintótica de predição para árvores de decisão treinadas com o algoritmo CART?