Questões de Concurso
Foram encontradas 144.615 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Julgue o item a seguir, relativo a dados e bancos de dados.
Os metadados provêm uma descrição concisa dos dados e
desempenham um papel na gestão dos dados; a partir dos
metadados, as informações são processadas, atualizadas e
consultadas.
Julgue o item seguinte, em relação a ataques cibernéticos e a ataques a rede definida por software (SDN).
O ataque de DNS cache snooping é um tipo de ataque em
que o servidor DNS precisa ser configurado para resolver
nomes recursivamente para terceiros e que os registros de
cache estejam apagados.
Julgue o item seguinte, em relação a ataques cibernéticos e a ataques a rede definida por software (SDN).
O ataque de manipulação de rede em SDN caracteriza-se por
um ataque crítico no plano de dados, caso em que um
invasor produz dados de rede falsos e inicia outros ataques
no plano de aplicação.
Julgue o item seguinte, em relação a ataques cibernéticos e a ataques a rede definida por software (SDN).
Ataques de inundação HTTP são um tipo de ataque DDoS da
camada 7 no modelo de referência OSI.
Julgue o item seguinte, em relação a ataques cibernéticos e a ataques a rede definida por software (SDN).
O ataque de desvio de tráfego em SDN caracteriza-se por
comprometer um elemento da rede no plano de dados, para
redirecionar os fluxos de tráfego, o que permite a realização
de escuta clandestina.
Acerca de algoritmos simétricos e assimétricos em criptografia, julgue o item a seguir.
Consoante o que o algoritmo RSA preconiza, n é usado
como valor para chave pública, tal que n = p ∙ q, em que p e
q representam números primos grandes.
Acerca de algoritmos simétricos e assimétricos em criptografia, julgue o item a seguir.
O algoritmo AES usa o princípio conhecido como rede de
substituição-permutação, o que o faz ser eficiente em
software, mas não em hardware.
No que diz respeito à computação em nuvem e à computação na borda, julgue o item subsecutivo.
No modelo plataforma como serviço (PaaS), são
disponibilizados recursos para o desenvolvimento de
aplicativos, incluídas as atualizações do sistema operacional
hospedeiro e a manutenção de hardware.
No que diz respeito à computação em nuvem e à computação na borda, julgue o item subsecutivo.
A computação de borda dispõe de um mecanismo para
aproximar o armazenamento de informações e o
correspondente processamento dos dispositivos que
produzem essas informações.
Em relação à Indústria 4.0 e a metaverso, julgue o próximo item.
A Internet das Coisas e a computação em nuvem são
elementos que compõem os fundamentos da Indústria 4.0.
Em relação à Indústria 4.0 e a metaverso, julgue o próximo item.
O metaverso busca reproduzir a realidade em um ambiente
virtual, mediante tecnologias como realidade virtual,
realidade aumentada e Internet.
I. Nas CPUs, o conceito de pipelining promove o paralelismo no nível de processador.
II. O objetivo fundamental da memória cache é reduzir a latência computacional na tarefa de acesso aos dados.
III. Em uma memória primária, todas as células contêm o mesmo número de bits. Se uma célula consistir em k bits, ela pode conter quaisquer das 2k diferentes combinações de bits.
Considere um banco de dados de uma transportadora desenvolvido em MySQL. A tabela
da Frota é exibida na figura abaixo, na qual o sistema da empresa registra a atualização da
quilometragem no campo Km a cada retorno de uma atividade de transporte. A empresa deseja
implementar um controle de manutenção preventiva de acordo com a quilometragem
percorrida a partir da implantação do controle. Para isso, foram criadas duas tabelas adicionais
e um Trigger que também são exibidos abaixo. A tabela de Controle define o padrão de
manutenção preventiva por tipo de veículo, usando como base as quilometragens percorridas
por cada veículo para agendar as manutenções de forma automatizada para cada veículo. A tabela ManAgenda mantém os agendamentos de manutenção cadastrados. Assim, na
implementação do controle, a tabela ManAgenda está vazia. A análise do Trigger é condição
suficiente para verificar como os campos das tabelas são utilizados. As siglas PK (Primary Key)
e FK (Foreign Key) destacadas como legenda em cada tabela, referem-se às chaves primárias e
às chaves estrangeiras das tabelas.
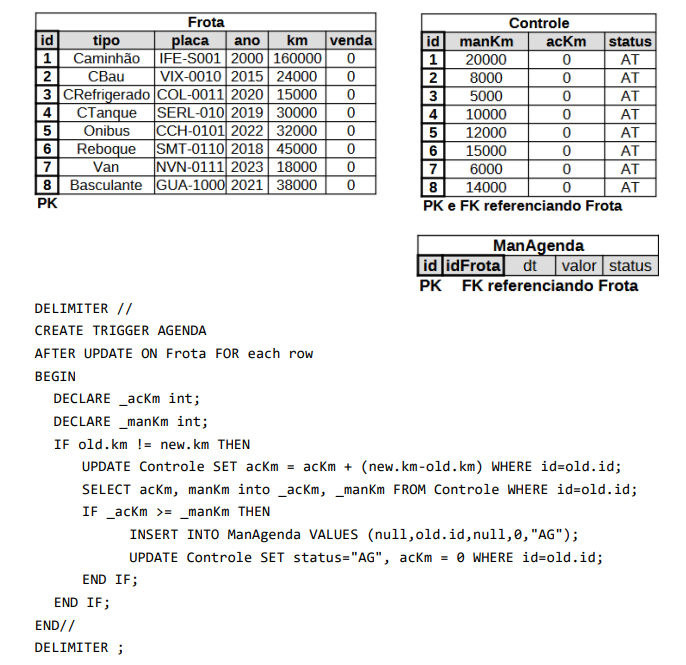
Suponha que após a implantação dos controles, cada veículo da Frota realizou 1 transporte de 3000km em agosto, 1 transporte de 4000km em setembro e 1 transporte de 2000km em outubro. Após essas 3 ações de transporte, qual alternativa corresponde ao que estará armazenado na tabela ManAgenda e na Tabela de Controle, com base no Trigger e nos dados iniciais apresentados das tabelas.
Obs: para evitar condição de corrida, admita que cada veículo teve sua quilometragem
atualizada após cada um dos transportes seguindo a mesma ordenação da tabela Frota.
Acerca do fluxo de Big Data, julgue o item que se segue.
Na etapa de captura de Big Data, grandes volumes de dados
são armazenados em bancos de dados NoSQL, devido à sua
escalabilidade e à sua flexibilidade.
Acerca do fluxo de Big Data, julgue o item que se segue.
As funções do MapReduce transformam um volume grande
de dados em grupamentos segmentados, mantendo na saída
a mesma quantidade de dados da entrada.
Acerca do fluxo de Big Data, julgue o item que se segue.
O serviço ElasticSearch utiliza índices divididos em
fragmentos, de maneira que cada nó armazena diversos
fragmentos e atua na coordenação das operações nos vários
fragmentos.
Acerca do fluxo de Big Data, julgue o item que se segue.
Streaming processing é uma tecnologia de Big Data
exclusiva para atender processamentos de serviços de
streaming de áudio e vídeo.
Acerca do fluxo de Big Data, julgue o item que se segue.
Na apresentação de dados, a extração de subcoleções e a
consulta de parâmetros permitem a navegação em diversos
cenários da visualização.
A respeito de Big Data, julgue o próximo item.
No processamento ROLAP, bancos de dados relacionais são
utilizados como local de armazenamento para agregação,
enquanto, nos processamentos MOLAP e HOLAP,
utilizam-se bancos de dados multidimensionais.
A respeito de Big Data, julgue o próximo item.
O processo de ELT, devido às suas etapas, exige maior definição
de regras, estruturas e relações do que a abordagem ETL.