Questões de Algoritmos e Estrutura de Dados - Estrutura de Dados para Concurso
Foram encontradas 1.370 questões
Acerca das estruturas homogêneas de dados vetor e matriz e dos conceitos de pilhas, filas e árvores binárias, julgue o item.
Os vetores são declarados, geralmente, por meio de
colchetes, os quais são usados também para identificar
um elemento específico do vetor.
Considere o seguinte algoritmo

Qual o resultado do conteúdo do vetor “vetor”, após a execução do algoritmo?
O pseudocódigo a seguir descreve um algoritmo que pode ser utilizado para ordenar um vetor V[1..n], em ordem crescente.

Como é conhecido esse algoritmo?
Considere as seguintes estruturas de dados com as propriedades definidas a seguir:
I - Inserção e remoção de elementos acontecem apenas na “cabeça” da estrutura.
II - Inserção de um nó no meio da estrutura pode ser realizada com custo computacional constante.
III - Respeito à política FIFO: o primeiro elemento que entra é o primeiro a sair.
As descrições acima se referem às seguintes estruturas, respectivamente,
Considere a representação de uma lista duplamente encadeada que armazena os times de futebol participantes de um torneio.
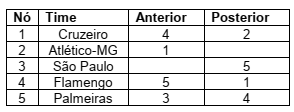
Para armazenar os dados a serem utilizados por um sistema, o desenvolvedor pode fazer uso de uma, entre várias estruturas de dados existentes, em que cada uma é adequada a determinados contextos. Sobre as estruturas de dados, marque a alternativa CORRETA.
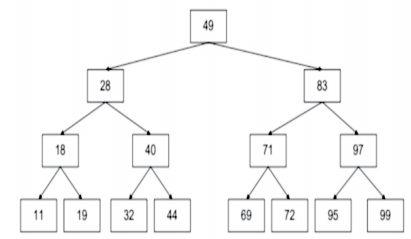
Indique o percurso dos nós em ordem simétrica da árvore binária abaixo:
Considere a estrutura de dados árvore binária de busca e que cada um de seus elementos possua três campos.
➢ left: um ponteiro para o elemento à sua esquerda;
➢ value: informação armazenada pelo elemento; e
➢ right: um ponteiro para o elemento à sua direita.
Considere ainda uma árvore binária de busca preexistente armazenada na variável root “e uma função newNode que cria um novo elemento de árvore com o valor dentro (seus ponteiros são inicializados como nulos)”.

Analisando-se o trecho de pseudocódigo apresentado, qual é a
tarefa realizada por ele?
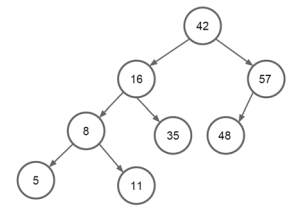
Considere a árvore binária apresentada.
Percorrer essa árvore utilizando o algoritmo de pre-oder
resultará na seguinte sequência:
A pilha é uma estrutura de dados que permite a inserção e a remoção desses dados sempre por meio de regras predefinidas. Para que essas operações sejam realizadas, são utilizadas duas funções: push e pop. Com base nessa informação, considere que um programa possua uma pilha p, inicialmente vazia, e que as seguintes operações foram realizadas: PUSH(p, 10); PUSH(p, 5); PUSH(p, 3); PUSH(p, 50); POP(p); PUSH(p, 11); PUSH(p, 9); PUSH(p, 20); POP(p); POP(p).
Ao fim da execução desses comandos, quais serão o topo da pilha e o somatório dos elementos ainda dentro da pilha, respectivamente?
Determinada estrutura de dados foi projetada para minimizar o número de acessos à memória secundária. Como o número de acessos à memória secundária depende diretamente da altura da estrutura, esta foi concebida para ter uma altura inferior às estruturas hierarquizadas similares, para um dado número de registros. Para manter o número de registros armazenados e, ao mesmo tempo, diminuir a altura, uma solução é aumentar o grau de ramificação da estrutura (o número máximo de filhos que um nó pode ter). Assim, esta estrutura possui um grau de ramificação geralmente muito maior que 2. Além disso, a cada nó são associados mais de um registro de dados: se o grau de ramificação de um nó for g, este pode armazenar até g-1 registros.
Esta estrutura de dados é utilizada em banco de dados e sistema de arquivos, sendo denominada
O Round-Robin é um tipo de escalonamento preemptivo mais simples e consiste em repartir uniformemente o tempo da CPU entre todos os processos prontos para a execução. Os processos são organizados em uma estrutura de dados, alocando-se a cada um uma fatia de tempo da CPU, igual a um número de quanta. Caso um processo não termine dentro de sua fatia de tempo, retorna para o fim da estrutura e uma nova fatia de tempo é alocada para o processo que está no começo da estrutura e que dela sai para receber o tempo de CPU.
A estrutura de dados utilizada nesse tipo de escalonamento é: