Questões de Concurso Comentadas sobre banco de dados
Foram encontradas 13.042 questões
Ano: 2022
Banca:
FCC
Órgão:
DETRAN-AP
Prova:
FCC - 2022 - DETRAN-AP - Analista de Tecnologia da Informação |
Q2093036
Banco de Dados
Um analista modelou a entidade Motorista com os seguintes atributos:
CPF (identificador)
Endereco1
Endereco2
...
EnderecoN
Categoria
DataDeNascimento
Considerando que cada motorista pode ter vários endereços, a entidade Motorista
Q2091429
Banco de Dados
Considerando o modelo de Banco de Dados Relacional (BDR), é correto afirmar que
Q2091415
Banco de Dados
Sobre as operações de conjunto ANSI SQL, assinale
V (verdadeiro) ou F (falso) em cada afirmativa a
seguir.
( ) A operação union remove duplicatas automaticamente.
( ) O número de cópias duplicadas de uma tupla no resultado da operação except all é igual ao número de cópias duplicadas da tupla no primeiro conjunto menos o número de cópias duplicadas da tupla no segundo conjunto, desde que essa diferença entre o número de cópias seja positiva.
( ) Se o número de cópias duplicadas de uma tupla no primeiro conjunto é d1 e no segundo conjunto é d2, o número de tuplas duplicadas no resultado da operação intersect all é igual ao valor máximo entre d1 e d2.
A sequência correta é
( ) A operação union remove duplicatas automaticamente.
( ) O número de cópias duplicadas de uma tupla no resultado da operação except all é igual ao número de cópias duplicadas da tupla no primeiro conjunto menos o número de cópias duplicadas da tupla no segundo conjunto, desde que essa diferença entre o número de cópias seja positiva.
( ) Se o número de cópias duplicadas de uma tupla no primeiro conjunto é d1 e no segundo conjunto é d2, o número de tuplas duplicadas no resultado da operação intersect all é igual ao valor máximo entre d1 e d2.
A sequência correta é
Ano: 2022
Banca:
Quadrix
Órgão:
SEDF
Prova:
Quadrix - 2022 - SEDF - Gestor - Tecnologia da Informação |
Q2089312
Banco de Dados
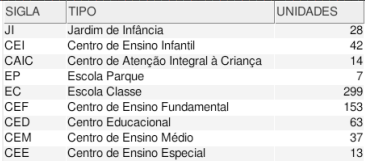
Considerando a imagem acima, que representa o conteúdo da tabela ESCOLA, implementada em um banco de dados relacional, julgue o item.
O comando apresentado a seguir, caso seja executado, removerá todos os dados da tabela ESCOLA.

Ano: 2022
Banca:
Quadrix
Órgão:
SEDF
Prova:
Quadrix - 2022 - SEDF - Gestor - Tecnologia da Informação |
Q2089311
Banco de Dados
Considerando a imagem acima, que representa o conteúdo da tabela ESCOLA, implementada em um banco de dados relacional, julgue o item.
Para alterar a quantidade de unidades da Escola Classe para 300, deve-se executar o comando apresentado a seguir.

Ano: 2021
Banca:
Avança SP
Órgão:
Câmara de Ribeirão Pires - SP
Prova:
Avança SP - 2021 - Câmara de Ribeirão Pires - SP - Assessor Técnico em Informática |
Q2088250
Banco de Dados
No que se refere aos comandos SQL, analise
os itens a seguir e, ao final, assinale a
alternativa correta:
I – Tornaram-se um padrão, os comandos funcionarão na maioria dos bancos de dados relacionais. II – Fornecem uma linguagem simples para manipulação de dados em um SGBD. III – Funcionam somente com bancos de dados orientados ao objeto.
I – Tornaram-se um padrão, os comandos funcionarão na maioria dos bancos de dados relacionais. II – Fornecem uma linguagem simples para manipulação de dados em um SGBD. III – Funcionam somente com bancos de dados orientados ao objeto.
Ano: 2023
Banca:
Instituto Consulplan
Órgão:
SEGEP-RO
Prova:
Instituto Consulplan - 2023 - SEGEP - RO - Técnico em Informática |
Q2087709
Banco de Dados
A implementação de Banco de Dados requer a criação de diversos objetos, seja pelo Administrador do Banco de Dados
(DBA) ou de um outro usuário que detenha privilégios para
realizar tal procedimento. São exemplos de objetos criados
por ocasião da implementação do banco de dados:
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085612
Banco de Dados
Analise as afirmativas abaixo sobre as funções de
tabela em PL/SQL.
1. São usadas para retornar coleções PL/SQL que
simulam ou se comportam como tabelas.
2. Podem ser consultadas como uma tabela
regular, utilizando o operador de tablela
TABLE da cláusula FROM.
3. Funções de tabela regulares requerem que
coleções sejam totalmente populadas antes
que sejam retornadas.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085611
Banco de Dados
Analise as afirmativas abaixo:
1. Uma restrição de integridade de entidade é
aquela que postula que nenhuma chave primária pode ser nula em uma relação.
2. Uma restrição de integridade referencial é
aquela que é especificada entre duas relações,
necessariamente, de modo a manter a consistência entre os atributos nas duas relações.
3. Todas as restrições de integridade devem ser
especificadas no esquema relacional do banco
de dados, como parte da sua definição, via DDL.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085610
Banco de Dados
No contexto das restrições em bancos de dados
relacionais, no âmbito do modelo de dados relacionais,
identifique restrições baseadas em esquema (schema-based) válidas:
1. Restrições de chave.
2. Restrições de domínio.
3. Restrições sobre valores nulos.
4. Restrições de gatilhos.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085606
Banco de Dados
Analise as afirmativas abaixo sobre data
Warehouse.
1. Tabelas de dimensão tendem a ter, por definição, menos registros que as tabelas fato.
2. Cada dimensão é definida por uma única
chave primária, que é base para a integridade referencial com quaisquer tabelas fato
correspondentes.
3. Atributos de dimensões e dimensões, por
definição, devem ser alfanuméricos e não
passíveis de agregação.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085604
Banco de Dados
Analise as afirmativas abaixo:
1. Quando os dados são carregados em um
cubo OLAP, eles são armazenados e indexados
empregando formatos e técnicas projetadas
para dados dimensionais.
2. Agregações de performance ou tabelas
resumo ou de sumário (summary tables) pré-calculadas podem ser criadas e gerenciadas
pelo motor (engine) do cubo OLAP.
3. Um esquema em estrela em um banco de
dados relacional não deve ser utilizado e não
é uma boa fundação para a construção de
cubos OLAP.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085603
Banco de Dados
Qual acrônimo de atributos caracteriza os requisitos de uma transação no contexto de bancos de dados relacionais de modo a estabelecer os requisitos e a terminologia que busca implementar as vantagens de se trabalhar com transações no contexto de sistemas gerenciadores de bancos de dados?
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085598
Banco de Dados
Analise as afirmativas abaixo sobre sistemas
gerenciadores de bancos de dados relacionais e
bancos de dados relacionais, no que diz respeito ao
modelo de dados relacional.
1. No modelo formal, um domínio é um conjunto de valores atômicos; isto é, cada valor
no domínio é indivisível no que diz respeito
ao modelo relacional formal.
2. O grau (degree ou arity) de uma relação é o
número de atributos n do seu esquema de
relação.
3. Um esquema de relação R, denotado por
R(A1,A2,…,An), é composto por uma relação
R e uma lista de atributos A1,A2,…,An; cada
qual pertencente a um domínio D.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Sistemas de Informação |
Q2085597
Banco de Dados
Qual o operador de atribuição em PL/SQL, a partir
do qual podem-se atribuir valores a variáveis?
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Inteligência de Dados |
Q2085408
Banco de Dados
Analise as afirmativas abaixo sobre MongoDB.
1. Não é possível de armazenar strings sem conformidade com UTF-8 em mongoDB.
2. É possível armazenar código Javascript em
documentos mongoDB.
3. MongoDB queries podem utilizar expressões
regulares utilizando a sintaxe de expressões
regulares padrão do Javascript.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Inteligência de Dados |
Q2085404
Banco de Dados
Analise as afirmativas abaixo sobre MongoDB.
1. Um documento é a unidade básica de dados
e é mais ou menos equivalente a um registro;
é um banco de dados relacional, porém mais
expressivo.
2. Uma coleção contém similaridades com e
remete a uma tabela no modelo relacional.
3. Cada instância do MongoDB pode conter um
único banco de dados que por sua vez pode
conter múltiplas coleções.
Assinale a alternativa que indica todas as afirmativas
corretas.
Ano: 2023
Banca:
FEPESE
Órgão:
Prefeitura de Balneário Camboriú - SC
Prova:
FEPESE - 2023 - Prefeitura de Balneário Camboriú - SC - Especialista em Inteligência de Dados |
Q2085392
Banco de Dados
Com relação às formas normais em bancos de
dados relacionais, assinale a alternativa correta no que
diz respeito à forma normal de Boyce/Codd, com relação à sua posição na hierarquia das formas normais.
Ano: 2023
Banca:
Instituto Consulplan
Órgão:
SEGER-ES
Prova:
Instituto Consulplan - 2023 - SEGER-ES - Analista do Executivo - Tecnologia da Informação |
Q2085017
Banco de Dados
Arquiteturas de Big Data são responsáveis por lidar com ingestão, processamento e análise de dados grandes ou complexos
demais para sistemas de banco de dados tradicionais. Em relação aos componentes das arquiteturas de Big Data, assinale
a afirmativa INCORRETA.
Ano: 2023
Banca:
Instituto Consulplan
Órgão:
SEGER-ES
Prova:
Instituto Consulplan - 2023 - SEGER-ES - Analista do Executivo - Tecnologia da Informação |
Q2085002
Banco de Dados
Os processos ELT (Extract, Load, Transform) e ETL (Extract,
Transform, Load) lidam com tratamento de dados através da
integração de dados de diversas fontes. Sobre os processos ELT
e ETL, assinale a afirmativa correta.