Questões de Banco de Dados para Concurso
Foram encontradas 15.577 questões
I. Na criação de uma VIEW pode-se utilizar UNION e ORDER BY. II. Uma VIEW provê mais segurança, pois permite esconder parte dos dados da tabela real. III. Os dados que compõem a VIEW são armazenados separadamente da tabela real. IV. Uma linha inserida na VIEW, com todas as colunas, será inserida na tabela real. V. Se contiver as cláusulas JOIN e GROUP BY, uma VIEW só poderá ser usada para SELECT.
É correto o que consta APENAS em
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
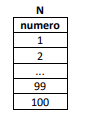
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
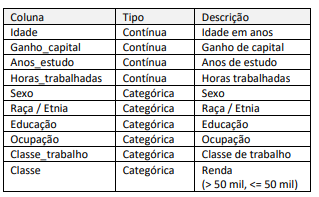
O conjunto de dados PESSOA será usado para a tarefa de aprendizagem supervisionada de classificação com a finalidade de prever se a renda (Classe) de uma pessoa excede 50 mil por ano.
Para isso, a operação de pré-processamento de dados que deve ser executada no conjunto de dados PESSOA é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
• TIPO_EMPRESA ="MEI", RENDA _ANO= "NIVEL A",> QUANTIDADE_SOCIOS=1, SITUACAO_FISCAL="INADIMPLENTE" (suporte = 50%, confiança = 70%)
• TIPO_EMPRESA="Simples", RENDA_ANO="NIVEL B"-> QUANTIDADE_SOCIOS= 2, SITUACAO_FISCAL="REGULAR" (suporte 30%, confiança = 80%)
A técnica de Mineração de dados que Renan aplicou para descobrir elementos que ocorrem em comum dentro de um determinado conjunto de dados foi:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
• DW_Tributos, banco de dados analítico do tipo Data Warehouse que integra dados sobre os tributos arrecadados do Município do Rio de Janeiro.
• TP_EMPRESA, Caractere, 1, atributo que descreve o tipo da empresa contendo os seguintes valores: M - MEI ou S - Simples Nacional, e faz parte da tabela TB _EMPRESA.
• RL_Sit_Fiscal, relatório sobre a situação fiscal das empresas do Município do Rio de Janeiro.
O componente do ambiente de Data Warehousing, utilizado por Inácio, que foi desenvolvido para apoiar consultas sobre a descrição de cada artefato de dado, é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Este é a resultado produzido por um determinado script SQL que utiliza a tabela N, anteriormente descrita.
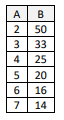
Abaixo, são apresentadas três versões para o referido script, não necessariamente corretas.

Sobre essas afirmativas, é correto afirmar que:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Analise o comando SQL a seguir, que faz referência à tabela N descrita anteriormente.
select n1.numero* n2.numero
from N n1, N n2
where n1.numero <> n2.numero
O número de linhas do resultado produzido pela execução desse comando, sem contar a linha de títulos, é:
I. Regra 1 − Todas as informações em um banco de dados relacional são representadas de forma explícita no nível lógico e exatamente em apenas uma forma − por valores em tabelas.
II. Regra 2 − Cada um e qualquer valor atômico (datum) em um banco de dados relacional possui a garantia de ser logicamente acessado pela combinação do nome da tabela, do valor da chave primária e do nome da coluna.
III. Regra 3 − Valores nulos devem ser suportados de forma sistemática e independente do tipo de dado para representar informações inexistentes e informações inaplicáveis.
IV. Regra 4 − A descrição do banco de dados é representada no nível lógico da mesma forma que os dados ordinários, permitindo que usuários autorizados utilizem a mesma linguagem relacional aplicada aos dados regulares.
Considerando as 12 regras referentes ao modelo relacional de dados, estabelecidas originalmente por Codd, está correto o que consta em
I. Cada Zona Eleitoral é identificada por um número seqüencial de 1 até "n";
II. Uma Seção Eleitoral é identificada por um número seqüencial de 1 até "n" dentro de cada Zona Eleitoral (portanto dependente de Zona Eleitoral).
O analista elaborou o seguinte diagrama:
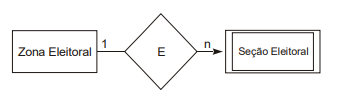
O diagrama
I. DELETE II. DROP TABLE III. CREATE INDEX IV. UPDATE V. INSERT INTO VI. ALTER TABLE
Classificando-se as expressões acima em Linguagem de Definição de Dados − DDL e Linguagem de Manipulação de Dados − DML, está correto o que consta em:
I. Os cursores implícitos são declarados e nomeados pelo programador, apenas para instruções PL/SQL SELECT, incluindo consultas que podem retornar uma ou mais linhas.
II. Os cursores explícitos são utilizados apenas para consultas que retornam mais de uma linha.
III. Os cursores implícitos são gerados dinamicamente para todas as instruções DML e PL/SQL SELECT, incluindo consultas que retornam somente uma linha.
É correto o que se afirma APENAS em