Questões de Concurso Sobre banco de dados
Foram encontradas 16.257 questões
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF-RS
Prova:
FUNDATEC - 2023 - IF-RS - Professor - Informática: Programação, Estrutura de Dados e Análise de Algoritimos |
Q2355264
Banco de Dados
Em SQL, uma condição especifica uma combinação de uma ou mais expressões e
operadores lógicos (booleanos) e retorna um valor: TRUE, FALSE ou UNKNOWN. São comandos de
condição:
I. Between.
II. Equals path.
III. Calculated_measure.
IV. CASE.
Quais estão corretos?
I. Between.
II. Equals path.
III. Calculated_measure.
IV. CASE.
Quais estão corretos?
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF-RS
Prova:
FUNDATEC - 2023 - IF-RS - Professor - Informática: Programação, Estrutura de Dados e Análise de Algoritimos |
Q2355263
Banco de Dados
Uma função SQL é um comando que manipula itens de dados e retorna um único
valor. Analise as assertivas abaixo em relação às funções SQL:
I. Aggregate_function são funções agregadas, retornam uma única linha de resultado com base em grupos de linhas ao invés de linhas únicas.
II. As funções SQL são integradas ao Oracle Database e estão disponíveis em diversas instruções SQL apropriadas.
III. Ao chamar uma função SQL com argumento de um tipo de dados diferente do tipo esperado pela função, o Oracle tentará converter o argumento no tipo de dados esperado antes de executar a função.
Quais estão corretas?
I. Aggregate_function são funções agregadas, retornam uma única linha de resultado com base em grupos de linhas ao invés de linhas únicas.
II. As funções SQL são integradas ao Oracle Database e estão disponíveis em diversas instruções SQL apropriadas.
III. Ao chamar uma função SQL com argumento de um tipo de dados diferente do tipo esperado pela função, o Oracle tentará converter o argumento no tipo de dados esperado antes de executar a função.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF-RS
Prova:
FUNDATEC - 2023 - IF-RS - Professor - Informática: Programação, Estrutura de Dados e Análise de Algoritimos |
Q2355262
Banco de Dados
Define(m) para o sistema como cada dado deverá ser manipulado; cada dado, de
acordo com suas características, recebe um tratamento diferenciado pelo processador. Um exemplo
utilizado em código é VAR X:=INTEGER; VAR X:=REAL. A descrição refere-se a que tipo de conceito?
Ano: 2023
Banca:
IBFC
Órgão:
EBSERH
Prova:
IBFC - 2023 - EBSERH - Analista de Tecnologia da Informação |
Q2348444
Banco de Dados
Num projeto de um banco de dados bem estruturado a normalização dos dados nas tabelas é fundamental. Dentro dos níveis de normalização a que contempla a ausência de dependências de junção é a forma normal de número:
Q2348257
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
Na fase de recuperação, de acordo com o modelo de ciclo de vida dos dados (CVD), há o acesso efetivo aos dados pelos profissionais e pesquisadores, ocorrendo, assim, as atividades de consulta e visualização dos dados.
Na fase de recuperação, de acordo com o modelo de ciclo de vida dos dados (CVD), há o acesso efetivo aos dados pelos profissionais e pesquisadores, ocorrendo, assim, as atividades de consulta e visualização dos dados.
Q2348256
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
De acordo com o modelo de ciclo de vida dos dados (CVD), na fase de coleta, ocorre o planejamento inicial dos dados, bem como sua descrição por meio de metadados, sua avaliação e sua seleção.
De acordo com o modelo de ciclo de vida dos dados (CVD), na fase de coleta, ocorre o planejamento inicial dos dados, bem como sua descrição por meio de metadados, sua avaliação e sua seleção.
Q2348255
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
A capacidade de aprender, adaptar, raciocinar, resolver problemas e aplicar conhecimento de forma eficaz em contextos variados é definida como informação.
A capacidade de aprender, adaptar, raciocinar, resolver problemas e aplicar conhecimento de forma eficaz em contextos variados é definida como informação.
Q2348254
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
Conhecimento pode ser definido como uma representação simbólica ou descritiva de fatos, conceitos ou instruções em vários formatos, como, por exemplo, números, palavras, imagens ou símbolos.
Conhecimento pode ser definido como uma representação simbólica ou descritiva de fatos, conceitos ou instruções em vários formatos, como, por exemplo, números, palavras, imagens ou símbolos.
Q2348253
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados
e na análise de dados e informações, julgue o item.
No tratamento de dados, a discretização pode ser definida como sendo um método que visa agrupar valores contínuos de uma variável em intervalos ou categorias distintas, simplificando a análise e o entendimento dos dados.
No tratamento de dados, a discretização pode ser definida como sendo um método que visa agrupar valores contínuos de uma variável em intervalos ou categorias distintas, simplificando a análise e o entendimento dos dados.
Q2348252
Banco de Dados
Acerca da modelagem de dados para DataWarehouse e do Data Lake, julgue o item.
A operação do Data Lake que tem como finalidade permitir importar qualquer quantidade de dados em tempo real de múltiplas fontes é denominada exploração/visualização.
A operação do Data Lake que tem como finalidade permitir importar qualquer quantidade de dados em tempo real de múltiplas fontes é denominada exploração/visualização.
Q2348251
Banco de Dados
Acerca da modelagem de dados para DataWarehouse e do Data Lake, julgue o item.
Com a finalidade de manter organizado o repositório, o Data Lake exige que o usuário defina, no mínimo, dois esquemas (schema) para os dados, sendo um para armazenar os metadados e o outro para os dados.
Com a finalidade de manter organizado o repositório, o Data Lake exige que o usuário defina, no mínimo, dois esquemas (schema) para os dados, sendo um para armazenar os metadados e o outro para os dados.
Q2348250
Banco de Dados
Acerca da modelagem de dados para DataWarehouse e do Data Lake, julgue o item.
Um Data Lake é um repositório de dados que pode armazenar dados em seu formato nativo, seja estruturado, semiestruturado ou não estruturado.
Um Data Lake é um repositório de dados que pode armazenar dados em seu formato nativo, seja estruturado, semiestruturado ou não estruturado.
Q2348249
Banco de Dados
Acerca da modelagem de dados para DataWarehouse e do Data Lake, julgue o item.
Na modelagem de dados para DataWarehouse, as tabelas fato contêm métricas e valores, enquanto as tabelas dimensionais contêm atributos das métricas carregadas nas tabelas fato.
Na modelagem de dados para DataWarehouse, as tabelas fato contêm métricas e valores, enquanto as tabelas dimensionais contêm atributos das métricas carregadas nas tabelas fato.
Q2348248
Banco de Dados
Acerca da modelagem de dados para DataWarehouse e do Data Lake, julgue o item.
Uma das abordagens utilizadas na modelagem
de dados para DataWarehouse é a abordagem de
Kimball, a qual envolve uma abordagem top‑down,
isto é, a construção de vários data marts ao mesmo
tempo, otimizando o processo de construção do
DataWarehouse.
Q2348247
Banco de Dados
Em relação ao ITIL 2011, às ferramentas ETL e ao sistema de gerenciamento de banco de dados Oracle, julgue o item.
O tablespace TEMP é utilizado, geralmente, pelo Oracle, para armazenar objetos transitórios durante as classificações e os agrupamentos de dados durante a execução de uma SQL.
O tablespace TEMP é utilizado, geralmente, pelo Oracle, para armazenar objetos transitórios durante as classificações e os agrupamentos de dados durante a execução de uma SQL.
Q2348242
Banco de Dados
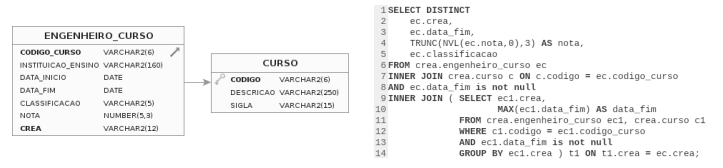
Com base no modelo de dados e no código SQL acima apresentados, julgue o item.
A função DISTINCT, utilizada na linha 1, tem a finalidade de determinar o número de itens com, pelo menos, um valor não nulo, que, nesse caso, é a quantidade de engenheiros que não tiraram nota zero nos cursos realizados.
A função DISTINCT, utilizada na linha 1, tem a finalidade de determinar o número de itens com, pelo menos, um valor não nulo, que, nesse caso, é a quantidade de engenheiros que não tiraram nota zero nos cursos realizados.
Q2348241
Banco de Dados
Com base no modelo de dados e no código SQL acima apresentados, julgue o item.
A consulta SQL tem como finalidade retornar somente os dados do engenheiro que tirou a nota mais alta em todos os cursos.
A consulta SQL tem como finalidade retornar somente os dados do engenheiro que tirou a nota mais alta em todos os cursos.
Q2348240
Banco de Dados
Com base no modelo de dados e no código SQL acima apresentados, julgue o item.
Para que os dados sejam agrupados pelo crea (linha 14), a função MAX deve ser utilizada em um campo numérico, e não em um campo do tipo DATE.
Para que os dados sejam agrupados pelo crea (linha 14), a função MAX deve ser utilizada em um campo numérico, e não em um campo do tipo DATE.
Q2348239
Banco de Dados
Com base no modelo de dados e no código SQL acima apresentados, julgue o item.
A instrução SQL não será executada, pois há um erro de sintaxe na linha 4, já que a função NVL não pode ser utilizada com a função TRUNC.
A instrução SQL não será executada, pois há um erro de sintaxe na linha 4, já que a função NVL não pode ser utilizada com a função TRUNC.
Q2348238
Banco de Dados
Com base no modelo de dados e no código SQL acima apresentados, julgue o item.
Na linha 4, a função TRUNC tem como objetivo remover o número especificado de dígitos dos valores numéricos.
Na linha 4, a função TRUNC tem como objetivo remover o número especificado de dígitos dos valores numéricos.