Questões de Concurso Sobre banco de dados
Foram encontradas 16.258 questões
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324346
Banco de Dados
Numa instalação de bancos de dados Oracle, as tabelas do tipo
Index-Organized permitem
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324345
Banco de Dados
No contexto de uma instalação do MS SQL Server, a configuração
inicial do server collation (Agrupamento do servidor, em
português), analise as afirmativas a seguir.
I. Não é possível criar bancos de dados com um valor do parâmetro Agrupamento diferente daquele adotado na instalação do SQL Server.
II. A escolha do Agrupamento pode ter impacto nas comparações entre strings em comandos SQL.
III. A escolha do Agrupamento não tem impacto na ordenação (order by) em comandos SQL.
Está correto o que se afirma em
I. Não é possível criar bancos de dados com um valor do parâmetro Agrupamento diferente daquele adotado na instalação do SQL Server.
II. A escolha do Agrupamento pode ter impacto nas comparações entre strings em comandos SQL.
III. A escolha do Agrupamento não tem impacto na ordenação (order by) em comandos SQL.
Está correto o que se afirma em
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324319
Banco de Dados
GraphQL (Graph Query Language) é uma linguagem muito útil
para busca de dados.
Sobre a sintaxe da linguagem GraphQL, assinale a afirmativa correta.
Sobre a sintaxe da linguagem GraphQL, assinale a afirmativa correta.
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324313
Banco de Dados
A sigla ETL, originária do inglês, denota, no contexto da análise e
exploração de dados, o processo de
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324312
Banco de Dados
No contexto de bancos de dados NoSQL, sobre o uso de índices
analise as afirmativas a seguir.
I. O suporte a índices secundários é frequente nas implementações NoSQL mais amplamente usadas, como, por exemplo, MongoBD.
II. Índices implementados em tabelas hash em bancos dados NoSQL permitem consultas por intervalos (range) com complexidade O(1).
III. Em contraste aos bancos relacionais, árvores B constituem o tipo de índice mais utilizado em bancos NoSQL.
Está correto o que se afirma em
I. O suporte a índices secundários é frequente nas implementações NoSQL mais amplamente usadas, como, por exemplo, MongoBD.
II. Índices implementados em tabelas hash em bancos dados NoSQL permitem consultas por intervalos (range) com complexidade O(1).
III. Em contraste aos bancos relacionais, árvores B constituem o tipo de índice mais utilizado em bancos NoSQL.
Está correto o que se afirma em
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324307
Banco de Dados
Texto associado
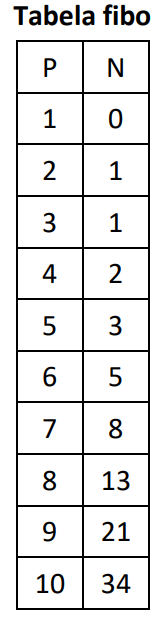


Atenção: o enunciado a seguir refere-se a próxima questão.
Quando mencionada, considere a tabela relacional intitulada fibo,
com duas colunas, cuja instância, não necessariamente nessa
ordem, é exibida a seguir.
A coluna da esquerda enumera as linhas, continuamente, e a
coluna da direita armazena os dez primeiros elementos da
sequência de Fibonacci, na qual os dois primeiros termos são
0 e 1, por definição, e cada termo subsequente é a soma dos dois
termos anteriores.
----------------------------------------------------------------
Suponha que a tabela fibo, apresentada anteriormente, tenha
sido danificada, e sua instância corrente seja a que segue.
Considere a instância da tabela fibo, anteriormente apresentada,
depois de um conjunto de alterações errôneas.
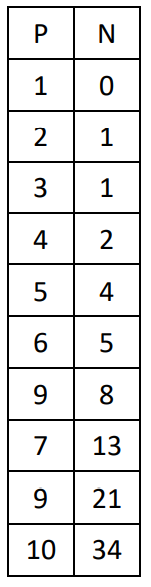
Considere ainda o comando SQL a seguir.

Assinale o número de linhas removidas da tabela fibo pela execução do comando acima com a presente instância.
Considere ainda o comando SQL a seguir.
Assinale o número de linhas removidas da tabela fibo pela execução do comando acima com a presente instância.
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Informática Legislativa - Tarde |
Q2324305
Banco de Dados
Texto associado
Atenção: o enunciado a seguir refere-se a próxima questão.
Quando mencionada, considere a tabela relacional intitulada fibo,
com duas colunas, cuja instância, não necessariamente nessa
ordem, é exibida a seguir.
A coluna da esquerda enumera as linhas, continuamente, e a
coluna da direita armazena os dez primeiros elementos da
sequência de Fibonacci, na qual os dois primeiros termos são
0 e 1, por definição, e cada termo subsequente é a soma dos dois
termos anteriores.
----------------------------------------------------------------
Suponha que a tabela fibo, apresentada anteriormente, tenha
sido danificada, e sua instância corrente seja a que segue.
À luz das características de funcionamento do SQL, o número
mínimo de vezes que esse comando deve ser acionado para
restaurar a instância original, é
Ano: 2023
Banca:
FGV
Órgão:
Câmara dos Deputados
Prova:
FGV - 2023 - Câmara dos Deputados - Analista Legislativo - Técnica Legislativa (Manhã) |
Q2322881
Banco de Dados
Uma escola está planejando um sistema de acompanhamento
temporal de seus alunos, de modo a classificá-los em relação
ao desempenho em português e em matemática ao longo de
cada ano.
Na escola há uma base de dados históricos que anualmente armazena, para cada aluno, em cada série, a nota final de cada uma dessas duas disciplinas. Essa nota é um valor decimal, entre 0 e 10. Note-se que essa escola, como em outras, há professores que aplicam diferentes graus de exigência nas suas avaliações, uns sendo mais “generosos” e outros, mais “rigorosos”.
Três estratégias de transformação de dados foram discutidas, à luz das ideias da Ciência de Dados, como descritas a seguir.
I. Agrupar os alunos a partir de intervalos de notas finais, do tipo “0 até 2,0”, “2,1 até 4,0”, ..., “8,1 até 10”.
II. Rotular grupos de desempenho, “Aprovado” e “Reprovado” e agrupar os alunos de acordo com os critérios de aprovação vigentes em cada situação.
III. Rotular grupos de desempenho, do tipo “Grupo A”, “Grupo B”, ..., “Grupo E”, e agrupar separadamente os alunos de cada conjunto ano/série/disciplina/professor de acordo com a distribuição relativa das notas em cada conjunto.
À luz da ciência de dados e do exposto acima, assinale a afirmativa correta.
Na escola há uma base de dados históricos que anualmente armazena, para cada aluno, em cada série, a nota final de cada uma dessas duas disciplinas. Essa nota é um valor decimal, entre 0 e 10. Note-se que essa escola, como em outras, há professores que aplicam diferentes graus de exigência nas suas avaliações, uns sendo mais “generosos” e outros, mais “rigorosos”.
Três estratégias de transformação de dados foram discutidas, à luz das ideias da Ciência de Dados, como descritas a seguir.
I. Agrupar os alunos a partir de intervalos de notas finais, do tipo “0 até 2,0”, “2,1 até 4,0”, ..., “8,1 até 10”.
II. Rotular grupos de desempenho, “Aprovado” e “Reprovado” e agrupar os alunos de acordo com os critérios de aprovação vigentes em cada situação.
III. Rotular grupos de desempenho, do tipo “Grupo A”, “Grupo B”, ..., “Grupo E”, e agrupar separadamente os alunos de cada conjunto ano/série/disciplina/professor de acordo com a distribuição relativa das notas em cada conjunto.
À luz da ciência de dados e do exposto acima, assinale a afirmativa correta.
Q2322056
Banco de Dados
No Data Warehouse do TCE SP, chamado DWContas, está
implementada a dimensão DIM_PESSOA contendo o atributo
CEP. Quando uma pessoa muda de endereço e altera seu CEP no
cadastro do sistema transacional do ambiente operacional, a
tabela DIM_PESSOA precisa ser atualizada. No DWContas, é
necessário preservar o valor anterior do CEP e armazenar o valor
atualizado em uma nova coluna da DIM _PESSOA.
Para atender ao requisito do DWContas, deve-se implementar a técnica de modelagem multidimentional Slowly Change Dimension (SCD) do tipo:
Para atender ao requisito do DWContas, deve-se implementar a técnica de modelagem multidimentional Slowly Change Dimension (SCD) do tipo:
Q2322055
Banco de Dados
O TCE SP está implementando um Data Warehouse utilizando
uma abordagem incremental, ou seja, constrói um Data Mart
para um setor e depois para outro setor, compartilhando
Dimensões.
A ferramenta de projeto, que representa as áreas do negócio e as dimensões associadas, utilizada para apoiar a implementação de modelos dimensionais de áreas de negócio distintos compartilhando dimensões padronizadas em um Data Warehouse Corporativo é o(a):
A ferramenta de projeto, que representa as áreas do negócio e as dimensões associadas, utilizada para apoiar a implementação de modelos dimensionais de áreas de negócio distintos compartilhando dimensões padronizadas em um Data Warehouse Corporativo é o(a):
Q2322054
Banco de Dados
João precisa criar um modelo interpretável de previsão de
cancelamento de serviços com base em dados de cliente,
demográficos e de tipo de serviço. Para tanto, João deve
considerar que o problema é tabular, com vários atributos e
regras de escolha complexas.
No contexto de técnicas de classificação, o tipo de algoritmo que João deverá utilizar é:
No contexto de técnicas de classificação, o tipo de algoritmo que João deverá utilizar é:
Q2322052
Banco de Dados
No contexto de Descoberta do Conhecimento em Bancos de
Dados - Knowledge Discovery in Database (KDD), o analista de
dados João deverá analisar um conjunto de dados preparado e
consolidado com dados financeiros sobre transações, saldos de
contas e históricos de crédito de clientes ao longo dos últimos
anos. O objetivo é identificar possíveis anomalias ou atividades
suspeitas que possam indicar fraudes.
Para isso, a fase do processo KDD que João deverá utilizar é:
Para isso, a fase do processo KDD que João deverá utilizar é:
Q2322051
Banco de Dados
O agente de fiscalização João está analisando um conjunto de
dados que representa o salário mensal de funcionários de uma
empresa. João utilizará o Diagrama de Boxplot para identificar a
presença de outliers nos dados. As estatísticas resumidas para os
dados são as seguintes:
Valor mínimo: R$ 1.200,00 Primeiro quartil (Q1): R$ 2.500,00 Mediana (Q2): R$ 3.200,00 Terceiro quartil (Q3): R$ 4.800,00 Valor máximo: R$ 10.000,00
Em relação à identificação de outliers usando o Diagrama de Boxplot, pode-se afirmar que serão considerados outliers:
Valor mínimo: R$ 1.200,00 Primeiro quartil (Q1): R$ 2.500,00 Mediana (Q2): R$ 3.200,00 Terceiro quartil (Q3): R$ 4.800,00 Valor máximo: R$ 10.000,00
Em relação à identificação de outliers usando o Diagrama de Boxplot, pode-se afirmar que serão considerados outliers:
Q2322050
Banco de Dados
O TCE SP contratou a empresa DataAnalysis para analisar as
características dos candidatos que estão participando do seu
concurso. Para realizar o pré-processamento dos dados, a
DataAnalysis coletou e classificou as seguintes informações das
variáveis relacionadas aos candidatos:
• Profissão do candidato
• Nome completo do candidato
• Número de anos de experiência profissional
• Idade do candidato, considerando ano e meses
• Nível de escolaridade (Ensino Médio, Graduação, Pós-Graduação)
A variável classificada como qualitativa ordinal pela empresa DataAnalysis foi:
• Profissão do candidato
• Nome completo do candidato
• Número de anos de experiência profissional
• Idade do candidato, considerando ano e meses
• Nível de escolaridade (Ensino Médio, Graduação, Pós-Graduação)
A variável classificada como qualitativa ordinal pela empresa DataAnalysis foi:
Q2322049
Banco de Dados
Considere o conjunto de dados da entidade PACIENTE que possui
o atributo do tipo contínuo TEMPERATURA com os valores {38.0,
39.5, 36.0, 35.5}. Para alimentar uma tarefa de Mineração de
Dados, é necessário transformar os dados do atributo
TEMPERATURA em um número finito de intervalos, como: {35-37,
38-40}.
A tarefa de preparação de dados utilizada no atributo TEMPERATURA é:
A tarefa de preparação de dados utilizada no atributo TEMPERATURA é:
Q2322038
Banco de Dados
Observe a seguinte consulta SQL, feita no SQLite:
SELECT imagem, avg(imagem) OVER (PARTITION BY grau) AS media_grau FROM historico_bijecao;
O SQLite dispõe de vários tipos de função. Na consulta acima, a função avg foi usada como uma função do tipo:
SELECT imagem, avg(imagem) OVER (PARTITION BY grau) AS media_grau FROM historico_bijecao;
O SQLite dispõe de vários tipos de função. Na consulta acima, a função avg foi usada como uma função do tipo:
Q2322020
Banco de Dados
João foi contratado para implantar uma arquitetura de zero Trust
no Tribunal de Contas do Estado de São Paulo (TCE SP). Ele
subdividiu as atividades em um mecanismo de política e um
algoritmo Trust. Esse algoritmo é o processo usado pelo
mecanismo de política para conceder ou negar acesso a um
recurso. As entradas para o algoritmo Trust foram divididas em
categorias com base no que fornecem ao algoritmo. João está
identificando quem solicita acesso a um recurso e se essa
solicitação pode ser feita por um conjunto de sujeitos (humanos
ou processos) da empresa ou colaboradores. A informação desse
conjunto de sujeitos será parte da política de acesso aos recursos.
Todas essas informações compõem a entrada ao algoritmo de zero Trust implantado por João, que pertence à categoria:
Todas essas informações compõem a entrada ao algoritmo de zero Trust implantado por João, que pertence à categoria:
Q2322019
Banco de Dados
Com relação às propriedades ACID, fundamentais na
implementação de bancos de dados relacionais, a durabilidade
das transações é obtida por meio:
Q2322018
Banco de Dados
Views, em bancos de dados relacionais, configuram um
importante mecanismo para flexibilizar o acesso aos dados
armazenados. Em alguns casos, são ditas atualizáveis, pois podem
ser utilizadas como alvo de comandos SQL como insert, update,
delete.
Uma característica que não impede uma view de ser atualizável é:
Uma característica que não impede uma view de ser atualizável é:
Q2322017
Banco de Dados
Tabelas Hash (e assemelhadas) são utilizadas frequentemente em
implementações de bancos NoSQL do tipo “Key-value”, enquanto
B-trees são preferencialmente utilizadas em bancos de dados
relacionais.
Nesse contexto, analise as afirmativas a seguir.
I. Algoritmos de busca a partir de chaves em tabelas Hash têm complexidade O(N/2), enquanto em B-trees têm complexidade O(log N).
II. B-trees suportam buscas por intervalo de chaves.
III. Tabelas Hash admitem e gerenciam múltiplas chaves para o mesmo objeto indexado sem redundância.
Está correto somente o que se afirma em:
Nesse contexto, analise as afirmativas a seguir.
I. Algoritmos de busca a partir de chaves em tabelas Hash têm complexidade O(N/2), enquanto em B-trees têm complexidade O(log N).
II. B-trees suportam buscas por intervalo de chaves.
III. Tabelas Hash admitem e gerenciam múltiplas chaves para o mesmo objeto indexado sem redundância.
Está correto somente o que se afirma em: