Questões de Banco de Dados para Concurso
Foram encontradas 15.577 questões
Considere as seguintes tabelas em um banco de dados para responder à questão.
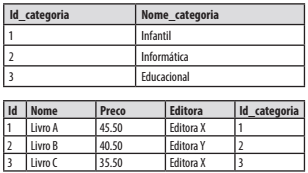
Considerando as tabelas do Caso 1, analise o comando SQL abaixo:
SELECT Produto.Nome, Produto.Preco,
Categoria.Nome_Categoria
FROM Produto
INNER JOIN Categoria ON Produto.ID_
Categoria = Categoria.ID WHERE Categoria.
ID=1;
Assinale a alternativa que apresenta corretamente o
resultado da execução desse comando SQL.
Uma transação em um banco de dados relacional deve possuir as seguintes propriedades:
1. Persistência
2. Atomicidade
3. Durabilidade
4. Isolamento
5. Preservação da Consistência
Assinale a alternativa que indica todas as afirmativas
corretas.
Uma tabela está na Segunda Forma Normal 2FN se:
1. O nível Interno possui um esquema (schema) interno, que descreve a estrutura de armazenamento física do banco de dados.
2. O nível intermediário, também denominado de nível de aplicação, abstrae os detalhes do armazenamento físico e concentra-se na descrição das entidades, tipos de dados, relacionamentos e restrições.
3. O nível externo ou nível de visualização inclui esquemas (schemas) externos ou visões / views de usuário. Cada esquema externo descreve a parte do banco de dados que um dado grupo de usuários necessita.
Assinale a alternativa que indica todas as afirmativas corretas.
id - int (Primary Key) nome - varchar (70) cidade - varchar (40) estado - varchar (40)
Em condições ideais, para exibir os dados de todos os clientes, cujo nome da cidade não seja igual ao nome do estado, utiliza-se a instrução SQL: SELECT * FROM cliente WHERE
CREATE DEFINER="root"e"localhost” FUNCTION “Apoio” (ent VARCHAR (255)) RETURNS varchar (255) CHARSET
utf8mb4 DETERMINISTIC
BEGIN DECLARE len INT; DECLARE i INT; SET len = CHAR LENGTH(ent); SET i =õoO; WHILE (i < len) DO IF (MID(ent,i,1) ="! " OR i = 0) THEN IF (i < len) THEN SET ent = CONCAT( LEFT (ent,i), UPPER (MID(ent,i + 1,1)), RIGHT (ent,len - i - 1)
) ; END IF;
END IF; SET i - i + I; END WHILE; RETURN ent; END
Esta função foi executada pelo comando abaixo.
SELECT Apoio (cargo) from usuarios;
Espera-se, como resultado, uma lista com os conteúdos do campo cargo
<dependency> <groupId>org.springframework .boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency > <dependency> <groupId>org.postgresql</groupld> <artifactId>postgresql</artifactId> </dependency >
Tais configurações foram inseridas corretamente no arquivo
String driver, url, usuario, senha, sql; Connection conecta; PreparedStatement st; driver = "com.mysql.cj.jdbc.Driver"; url = "jdbc:mysql://localhost:3306/bd" ; usuario = "root"; senha sql "aB12c56DY" ; = "SELECT * FROM users WHERE usuario=? AND senha=?"; Class.forName (driver) ; conecta = DriverManager.getConnection (url, usuario, senha) ; st = conecta.prepareStatement (sql); st.setString(1, txtUsuario.getText ()); st.setString(2, pswSenha.getText ());
Para executar o comando SQL SELECT na tabela users do banco de dados bd e armazenar o retorno em rs deve-se utilizar, na próxima linha do bloco de código, o comando
I. Um backup incremental de transações inclui todos os registros de log dos quais não foi feito backup de dados anteriores.
II. Um backup de logs registra apenas as extensões de dados que foram alteradas nos grupos de arquivos desde o último backup, conhecido como base para o backup diferencial.
III. Os backups de banco de dados completos representam todo o banco de dados quando o backup foi concluído.
Está correto o que se afirma em
Os componentes analisadores de texto são denominados
No contexto do PostgreSQL, analise o comando a seguir.
CREATE TABLE TESTE (
C0 SERIAL PRIMARY KEY,
C1 TEXT NOT NULL,
C2 CHAR(50),
C3 REAL
);
Assinale a forma de preenchimento automático da coluna C0.
create sequence xpto;
select xpto.nextval from dual d1, dual d2, dual d3;
select xpto.currval from dual;
Assinale o valor exibido pelo último comando.
I. delete from X where A = 20;
II. delete from Y where A = 20;
delete from X where A = 20;
III. delete from X where A = 20;
delete from Y where A = 20;
Assinale o(s) script(s) que removeria(m), sem erros, as linhas de ambas as tabelas que contêm o valor 20 na coluna A.