Questões de Concurso Sobre banco de dados
Foram encontradas 16.029 questões
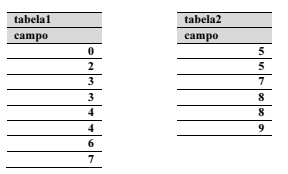
Considerando as tabela1 e tabela2 apresentadas, julgue o item que se segue, referentes a banco de dados.
Considere que o comando a seguir seja executado sem erro.
select campo from tabela2
where exists
(select campo from tabela1)
Nesse caso, o resultado será a tabela seguinte.

Julgue o item a seguir, a respeito de otimização.
O índice secundário é empregado quando se utiliza um campo de indexação que não seja a chave primária da tabela.
COMANDO 1: select * from tb_valores where 1=2 COMANDO 2: select * from tb_valores where 1=1
Analise as assertivas abaixo e assinale a alternativa correta.
I. COMANDO 1 retorna NULL. II. COMANDO 2 retorna NULL. III. As saídas de ambos os comandos são idênticas. IV. Somente o COMANDO 2 retorna tuplas.
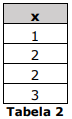
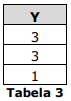
Nesse banco de dados, foi executado o seguinte comando SQL:
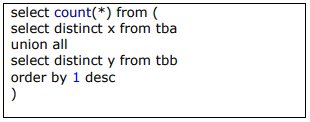
Qual o resultado esperado após a execução desse comando?
Coluna 1 1. WHERE. 2. HAVING.
Coluna 2 ( ) Aplica restrição sobre conjuntos de tuplas. ( ) Suporta o uso de funções de agregação na condição. ( ) Pode ser usada em outros comandos DML. ( ) Pode ser usada antes de uma eventual cláusula GROUP BY.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:

Tabela 1 – Conteúdo da tabela tb_comandos_sql
Para responder à questão, utilize a Tabela 1, que mostra o resultado da execução do comando SQL “SELECT * FROM tb_comandos_sql” em um banco de dados relacional que implementa ANSI SQL-92.
Considere o seguinte comando SQL:
SELECT SUM(id-6)
FROM tb_comandos_sql
WHERE nome LIKE '%ATE'
Que alternativa corresponde ao resultado esperado após a execução do comando SQL acima?
Tabela 1 – Conteúdo da tabela tb_comandos_sql
Para responder à questão, utilize a Tabela 1, que mostra o resultado da execução do comando SQL “SELECT * FROM tb_comandos_sql” em um banco de dados relacional que implementa ANSI SQL-92.
Caso o campo “tipo” fosse preenchido corretamente com os valores DML, DDL, DCL, DTL e DQL, para Linguagem de Manipulação de Dados (DML), Linguagem de Definição de Dados (DDL), Linguagem de Controle de Dados (DCL), Linguagem de Transação de Dados (DTL) e Consulta de Dados (DQL), respectivamente, de acordo com o subconjunto apropriado da linguagem SQL para cada comando, qual seria o resultado da execução do seguinte comando SQL?
SELECT COUNT(*), tipo
FROM tb_comandos_sql
GROUP BY tipo
ORDER BY 1 DESC, 2
Considere uma tabela denominada alunos em um SGBD (Sistema Gerenciador de Banco de Dados) MySQL com a seguinte estrutura:
id_aluno: inteiro, chave primária, autoincremento;
nome_aluno: string;
disciplina: string;
nota: inteiro.
Assinale a alternativa que representa a consulta SQL (Structured Query Language) que retorna o nome
da disciplina, a média das notas dos alunos e a quantidade de alunos para cada disciplina.
Para responder à questão, considere a situação descrita a seguir. Um técnico precisa importar o arquivo CSV (Comma-Separated Values) do Quadro 1 abaixo, em um banco de dados relacional. A primeira linha do arquivo contém o cabeçalho que define os atributos C1, C2, C3 e C4, enquanto as demais linhas são os valores assumidos por esses atributos em diferentes situações. O técnico deve executar a análise observando apenas o conteúdo disponível, sem levar em consideração quaisquer informações sobre a semântica dos atributos.

Considere o diagrama Entidade-Relacionamento (ER) da Figura 1 abaixo, construído no software brModelo versão 3.31:
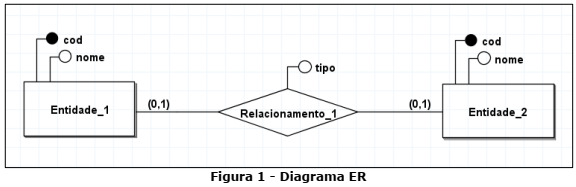
Agora, considere as implementações abaixo:
Implementação 1:
Entidade_1 (cod1, nome, cod2, tipo)
cod2 referencia Entidade_2
Entidade_2 (cod2, nome)
Implementação 2:
Entidade_1 (cod1, nome)
Entidade_2 (cod2, nome, cod1, tipo)
Cod1 referencia Entidade_1
Implementação 3:
Entidade_1 (cod1, nome)
Entidade_2 (cod2, nome)
Entidade_3 (cod1, cod2, tipo)
cod1 referencia Entidade_1
cod2 referencia Entidade_2
Quais implementações representam corretamente o diagrama ER da Figura 1?
Analise as assertivas abaixo sobre Modelagem Dimensional:
I. Modelagem dimensional utiliza o modelo relacional.
II. Um diagrama ER geralmente pode ser representado por múltiplos diagramas dimensionais.
III. É difícil prever as estratégias de otimização de consultas em modelos dimensionais, porque suas estruturas são muito variáveis.
Quais estão INCORRETAS?
No projeto lógico de um banco de dados relacional, após a tradução das entidades para tabelas, a tradução dos relacionamentos binários é feita de três formas básicas. Quais sejam:
I. Criação de tabela própria para o relacionamento.
II. Adição de colunas em uma tabela de entidade.
III. Adição de registros em uma tabela de entidade.
IV. Fusão de tabelas de relacionamentos.
V. Fusão de tabelas de entidades.
Quais estão corretas?
O projeto lógico de banco de dados relacional é o nome dado à transformação de um _________________________ para um _________________. A transformação inversa é chamada de _________________.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Uma Progressão Geométrica (PG) é uma sequência de valores em que, a partir do segundo valor da sequência, a divisão de um termo pelo termo imediatamente anterior é constante ao longo de toda sequência. A essa divisão dá-se o nome de razão da PG. Considere que a tabela abaixo, chamada “tb_sequencia”, está disponível em um banco de dados MySQL Community 5.
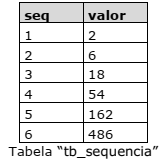
Solicitou-se que fosse criada uma consulta em linguagem SQL que indique se a sequência de todos os
valores da tabela “tb_sequencia” é uma Progressão Geométrica (PG) ou não. Caso seja, é solicitado
que também seja informada a sua razão. Qual alternativa contém uma consulta que atende ao que
foi solicitado?
O MySQL Workbench é uma ferramenta gráfica para trabalhar com os bancos de dados MySQL. Ela oferece diversas funcionalidades, entre elas pode-se citar a de __________________ que transforma __________________ em __________________.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Observe o comando SQL abaixo:
select 1,2,3 from dual;
Em um SGBD Oracle Database Express Edition 11g, ele retorna uma linha com 3 colunas, com os valores 1, 2 e 3 para cada coluna. Agora, observe os comandos abaixo:
I. select 1,2,3 from dual;
II. select 1,2,3;
III. select 1,2,3 from dummy;
Para obter o mesmo resultado em um SGBD MySQL Community 5, é possível utilizar o que consta em quais itens acima?