Questões de Concurso Sobre banco de dados
Foram encontradas 16.281 questões
Acerca de fundamentos dos bancos de dados relacionais, normalização, diagrama entidade-relacionamento e linguagem SQL, julgue o item a seguir.
Por serem uma evolução dos modelos de bancos de dados
hierárquicos e em redes, os bancos de dados relacionais
dispõem de caminhos predefinidos por ligações e nós para
viabilizar o acesso aos dados de forma sistemática e
ordenada.
Acerca de fundamentos dos bancos de dados relacionais, normalização, diagrama entidade-relacionamento e linguagem SQL, julgue o item a seguir.
Em uma consulta SQL, a cláusula FROM corresponde à
seleção do predicado que envolve atributos da relação
determinada pela cláusula SELECT.
Acerca de fundamentos dos bancos de dados relacionais, normalização, diagrama entidade-relacionamento e linguagem SQL, julgue o item a seguir.
Nos diagramas de entidades e relacionamentos, o
particionamento de entidades se dá por especialização
quando uma entidade de nível mais alto de abstração é
desmembrada em duas ou mais entidades de nível mais
baixo.
Julgue o item que se segue acerca de observabilidade.
A observabilidade é o processo usado para identificar a rota
percorrida por um conjunto de dados pela rede até a chegada
em seu banco de dados destino.
Para isso, Elizabeth deve utilizar uma ferramenta de:
Dessa forma, o tipo de banco de dados utilizado para armazenar grafos, documentos e chave-valor é:
( ) No relacionamento do tipo um-para-muitos, várias instâncias de uma entidade estão associadas a múltiplas instâncias de outra entidade. Isso é geralmente implementado por meio de uma terceira tabela, denominada tabela de associação ou tabela de junção.
( ) Entidades são características ou propriedades que descrevem um atributo. Por exemplo, um Livro pode ter entidades como Título, Autor, ISBN, Ano de Publicação, etc.
( ) Pode-se afirmar que uma entidade estará na Primeira Forma Normal (1NF) somente se todos os seus atributos não chave dependerem diretamente apenas da chave primária, sem apresentar dependências transitivas.
Julgue o item a seguir, a respeito de conceitos e fundamentos de dados.
Dados estruturados são aqueles que se encaixam
perfeitamente nas tabelas de dados e incluem tipos de dados
discretos, como números, textos curtos e datas.
Julgue o item a seguir, a respeito de conceitos e fundamentos de dados.
ETL (extract, transform, load) envolve a extração de dados
de múltiplas fontes de dados, inclusive fontes de dados
orçamentários.
Em relação a banco de dados relacionais, julgue o seguinte item.
A chave estrangeira é definida como um conjunto de um ou
mais campos para definir, univocamente, um único registro.
Em relação a banco de dados relacionais, julgue o seguinte item.
A normalização de dados em um banco de dados é uma
técnica que organiza os dados desse banco em uma escala
específica, como valores entre 0 e 1.
Em relação a banco de dados relacionais, julgue o seguinte item.
Triggers são procedimentos armazenados que são ativados
automaticamente em resposta a eventos específicos em
tabelas ou views.
Acerca de Power BI, exploração de dados e pareamento de dados (record linkage), julgue o próximo item.
Por meio da ferramenta Power Query, é possível definir
configurações de segurança para relatórios gerados.
FUNCIONÁRIOS (idFunc; idAtividade; Nome; DescricaoAtiv; Data; Tempo), na qual tanto idFunc quanto idAtividade são utilizadas como chave primária.
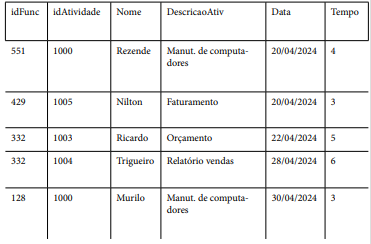
Levando-se em conta a definição da primeira, segunda e terceira formas normais, a tabela acima NÃO se encontra na
CREATE TABLE tb_users ( id INT NOT NULL AUTO_INCREMENT, nome VARCHAR(100) NOT NULL, email VARCHAR(50) NOT NULL, idade INT NOT NULL, PRIMARY KEY (id) );
Em seguida, foram executados os seguintes comandos:
INSERT INTO tb_users( nome, email, idade) VALUES ( ‘Ana’, [email protected]’,18); INSERT INTO tb_users( nome, email, idade) VALUES ( ‘Beatriz’, ‘[email protected]’,24); INSERT INTO tb_users( nome, email, idade) VALUES ( ‘Carol’, ‘[email protected]’,18); INSERT INTO tb_users( nome, email, idade) VALUES (‘Diana’, ‘[email protected]’,19); INSERT INTO tb_users( nome, email, idade) VALUES (‘Elsa’, ‘[email protected]’,30); INSERT INTO tb_users( nome, email, idade) VALUES (‘Fernanda’, ‘[email protected]’,23);
E, por último, a seguinte consulta:
SELECT nome FROM tb_users WHERE idade > 22 ORDER BY DESC
De acordo com os comandos executados, o primeiro nome a aparecer no resultado da consulta será:
Os nomes dessas duas funções são
As demais propriedades do teorema CAP são