Questões de Concurso Público BNDES 2024 para Analista - Ciência de Dados (Manhã)
Foram encontradas 7 questões
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048112
Engenharia de Software
Uma equipe de cientistas de dados está desenvolvendo um modelo preditivo e deseja otimizar seus hiperparâmetros para
maximizar a performance do modelo.
Considerando-se as técnicas de otimização de hiperparâmetros, para encontrar a configuração de hiperparâmetros, essa equipe de cientistas deverá
Considerando-se as técnicas de otimização de hiperparâmetros, para encontrar a configuração de hiperparâmetros, essa equipe de cientistas deverá
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048113
Engenharia de Software
Como parte do processo de desenvolvimento de uma aplicação para analisar grandes volumes de textos, diversas tarefas
de Processamento de Linguagem Natural (NLP, sigla em inglês) estão sendo implementadas para melhorar a eficácia e a
precisão dessa aplicação.
Diante disso, para a aplicação dessas tarefas, é necessário
Diante disso, para a aplicação dessas tarefas, é necessário
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048116
Engenharia de Software
Ao avaliar a performance de diversos modelos preditivos para um problema de regressão e outro de classificação, várias
métricas podem ser utilizadas para determinar qual modelo oferece o melhor desempenho. Considere as métricas para
regressão e classificação, bem como as técnicas de detecção de overfitting e underfitting.
Nesse contexto, quais métricas devem ser utilizadas para determinar qual modelo oferece o melhor desempenho?
Nesse contexto, quais métricas devem ser utilizadas para determinar qual modelo oferece o melhor desempenho?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048120
Engenharia de Software
Uma equipe de desenvolvimento de Inteligência Artificial
(IA) em uma empresa de tecnologia está implementando
um sistema de recomendação baseado em aprendizado
de máquina. Durante o processo de implementação, a
equipe precisa estar atenta aos potenciais riscos e vulnerabilidades associados ao uso da IA. O sistema utiliza
grandes volumes de dados históricos de clientes para treinar seus modelos. Há uma preocupação com a possibilidade de invasores manipularem a entrada de dados para
enganar o modelo e gerar saídas indesejadas ou incorretas. A equipe deve também garantir que o modelo não
exponha dados sensíveis dos clientes.
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048121
Engenharia de Software
Um programador estava trabalhando no branch
solvebugio e acabou o serviço. Após fazer o commit
final nesse branch, ele deseja passar todas as mudanças
feitas no branch solvebugio para o branch main, fazendo a
integração correta de mudanças.
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048122
Engenharia de Software
Um pesquisador de ciência de dados foi encarregado de
analisar a capacidade de um modelo de aprendizado de
máquina em prever se um cliente é bom pagador. Para
isso, possuía um conjunto de dados de testes rotulado,
sobre o qual aplicou o modelo e obteve a matriz de confusão a seguir:
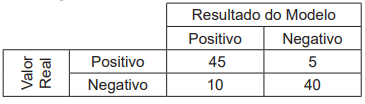
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048126
Engenharia de Software
Em aplicações modernas de Processamento de Linguagem Natural, usando Grandes Modelos de Linguagem
(Large Language Models – LLM) é comum a necessidade de usar informações relevantes que estão em documentos novos e privados, que não foram usados no pré-treinamento dos modelos de LLM. Considerando que esses documentos podem ser longos e em grande quantidade, que o tamanho do contexto usado na chamada à
Application Programming Interface (API) da LLM é limitado, e ainda pensando que os custos de processar
são muitas vezes calculados por quantidade de tokens, foi desenvolvida a técnica conhecida como Retrieval
Augmented Generation (RAG).
Considerando-se esse contexto, qual é a característica da técnica RAG?
Considerando-se esse contexto, qual é a característica da técnica RAG?