Questões de Concurso Público BNDES 2024 para Analista - Ciência de Dados (Manhã)
Foram encontradas 70 questões
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048117
Banco de Dados
Uma empresa está desenvolvendo um dashboard interativo para monitorar o desempenho das vendas em tempo real. O
objetivo é fornecer uma visão clara e acessível para diferentes níveis de usuários, desde gerentes executivos até analistas
de dados. Foram definidos os seguintes requisitos:
1. Os dados de vendas precisam ser visualizados por região, produto e período de tempo.
2. O dashboard deve permitir aos usuários explorar dados específicos por meio de interações como filtros e drill-downs.
3. A organização dos elementos visuais deve ser intuitiva, priorizando informações críticas e mantendo um layout claro e acessível.
Com base nas boas práticas de design de dashboards, qual abordagem deve ser adotada para garantir que o dashboard seja eficaz e acessível para todos os usuários?
1. Os dados de vendas precisam ser visualizados por região, produto e período de tempo.
2. O dashboard deve permitir aos usuários explorar dados específicos por meio de interações como filtros e drill-downs.
3. A organização dos elementos visuais deve ser intuitiva, priorizando informações críticas e mantendo um layout claro e acessível.
Com base nas boas práticas de design de dashboards, qual abordagem deve ser adotada para garantir que o dashboard seja eficaz e acessível para todos os usuários?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048118
Programação
Considere o seguinte trecho de código Python:

Esse código pretende contar a frequência de cada item na lista data, processando os dados em paralelo e serializando os resultados em um arquivo JSON. O resultado esperado é { " apple " : 3 , " banana " : 2 , " orange " : 1 }.
É necessário que algo seja alterado para que o código funcione corretamente e produza o resultado esperado?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048119
Comunicação Social
Uma narrativa visual apresentada durante uma comunicação corporativa pode utilizar várias estratégias para assegurar
que o storytelling seja eficaz.
Como funciona a prática conhecida como ‘lógica horizontal’?
Como funciona a prática conhecida como ‘lógica horizontal’?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048120
Engenharia de Software
Uma equipe de desenvolvimento de Inteligência Artificial
(IA) em uma empresa de tecnologia está implementando
um sistema de recomendação baseado em aprendizado
de máquina. Durante o processo de implementação, a
equipe precisa estar atenta aos potenciais riscos e vulnerabilidades associados ao uso da IA. O sistema utiliza
grandes volumes de dados históricos de clientes para treinar seus modelos. Há uma preocupação com a possibilidade de invasores manipularem a entrada de dados para
enganar o modelo e gerar saídas indesejadas ou incorretas. A equipe deve também garantir que o modelo não
exponha dados sensíveis dos clientes.
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048121
Engenharia de Software
Um programador estava trabalhando no branch
solvebugio e acabou o serviço. Após fazer o commit
final nesse branch, ele deseja passar todas as mudanças
feitas no branch solvebugio para o branch main, fazendo a
integração correta de mudanças.
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048122
Engenharia de Software
Um pesquisador de ciência de dados foi encarregado de
analisar a capacidade de um modelo de aprendizado de
máquina em prever se um cliente é bom pagador. Para
isso, possuía um conjunto de dados de testes rotulado,
sobre o qual aplicou o modelo e obteve a matriz de confusão a seguir:
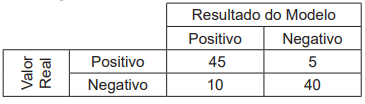
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048123
Estatística
Um cientista de dados está utilizando SHapley Additive
exPlanations (SHAP) para entender a importância das variáveis em um modelo de aprendizado de máquina que
prevê a probabilidade de um cliente deixar de ser assinante de um serviço (churn). Considere o seguinte conjunto
de dados simplificado com três características para um
cliente específico:
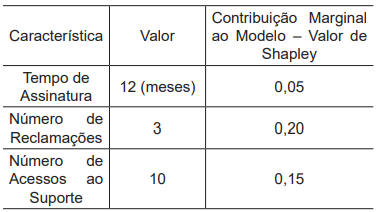
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048124
Programação
Um desenvolvedor está criando uma rede neural de 3 camadas, usando PyTorch para classificar amostras descritas por
um vetor com 10 elementos. Ele já definiu parte da rede, conforme o extrato de código abaixo, e pretende definir a camada
oculta como sendo composta de 5 nós, utilizando a função de ativação ReLU.

Considerando-se esse contexto, qual das linhas de código a seguir deve ocupar o comentário “#AQUI CRIAR CAMADA OCULTA COM 5 NOS E RELU” para definir corretamente a camada oculta?
Considerando-se esse contexto, qual das linhas de código a seguir deve ocupar o comentário “#AQUI CRIAR CAMADA OCULTA COM 5 NOS E RELU” para definir corretamente a camada oculta?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048125
Programação
Um analista financeiro está trabalhando com um conjunto de dados de clientes de um banco, armazenados em um
DataFrame Pandas chamado  Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda
e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico.
Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda
e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico.
Considerando-se esse contexto, qual das seguintes linhas de código em Python com Pandas seleciona corretamente as colunas Nome e Dívida do DataFrame e também filtra apenas as linhas em que a dívida dos clientes seja
superior a R$ 10.000,00?
e também filtra apenas as linhas em que a dívida dos clientes seja
superior a R$ 10.000,00?
Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda
e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico.
Considerando-se esse contexto, qual das seguintes linhas de código em Python com Pandas seleciona corretamente as colunas Nome e Dívida do DataFrame
e também filtra apenas as linhas em que a dívida dos clientes seja
superior a R$ 10.000,00?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048126
Engenharia de Software
Em aplicações modernas de Processamento de Linguagem Natural, usando Grandes Modelos de Linguagem
(Large Language Models – LLM) é comum a necessidade de usar informações relevantes que estão em documentos novos e privados, que não foram usados no pré-treinamento dos modelos de LLM. Considerando que esses documentos podem ser longos e em grande quantidade, que o tamanho do contexto usado na chamada à
Application Programming Interface (API) da LLM é limitado, e ainda pensando que os custos de processar
são muitas vezes calculados por quantidade de tokens, foi desenvolvida a técnica conhecida como Retrieval
Augmented Generation (RAG).
Considerando-se esse contexto, qual é a característica da técnica RAG?
Considerando-se esse contexto, qual é a característica da técnica RAG?