Questões de Concurso Público IPEA 2024 para Técnico de Planejamento e Pesquisa - Políticas Públicas e Avaliação
Foram encontradas 27 questões
Independentemente da forma como se meça, de qual indicador ou nível de agregação se utilize ou ainda, a qual país se compare, a produtividade brasileira teve um desempenho muito fraco nas últimas décadas. Desde o final dos anos 1970, a produtividade brasileira não cresce de forma substantiva e sustentada. Nos anos 2000, foi possível perceber uma tendência de crescimento da produtividade até 2008, especialmente na produtividade total dos fatores. Todavia, esse crescimento foi muito tênue se observado o cenário de longo prazo, pois não foi suficiente para reverter a forte queda dos anos 1980. Se levarmos em conta, ainda, o aumento de capital humano observado nos últimos vinte anos, percebe-se que quase todo o ganho de produtividade se deveu a esse fator.
NEGRI, F.; CAVALCANTE, L. Os dilemas e desafios da produtividade no Brasil. In: _________ (org.). Produtividade no Brasil: desempenho e determinantes. Brasília, DF: Ipea, 2014, p. 47. Adaptado.
Responsável pelo ganho de produtividade da economia brasileira contemporânea, o fator capital humano é medido diretamente por meio de
Escuridão favorece o fator surpresa da ação criminosa e dificulta a identificação de sua autoria
Se a escuridão favorece o fator surpresa da ação criminosa e dificulta a identificação de sua autoria, a principal hipótese é que o aumento da visibilidade permitido pela iluminação pública acabaria com essas vantagens, diminuindo os riscos de se cometer um crime.
Um experimento realizado em parceria com a polícia metropolitana de Nova York apontou para uma redução de 36% nos crimes ocorridos durante a noite em ruas que receberam iluminação pública extra por um período de seis meses, entre março e agosto de 2016.
Disponível em: https://www.otempo.com.br/brasil/ruas-com-iluminacao-publica-diminuem-o-risco-de-crimes-segundo-experimento-1.2209834. Acesso em: 2 jan. 2024. Adaptado.
Com base nessa experiência, o prefeito de uma determinada cidade resolveu implementar um programa de expansão do número de postes em uma localidade rural da cidade, com problemas de iluminação pública, que é considerada um bem público. A prefeitura também conseguiu inferir, a partir de uma pesquisa, a média do benefício marginal da instalação de postes de iluminação para 3 grupos de moradores com o mesmo tamanho (predisposição a pagar), conforme a Tabela seguinte:
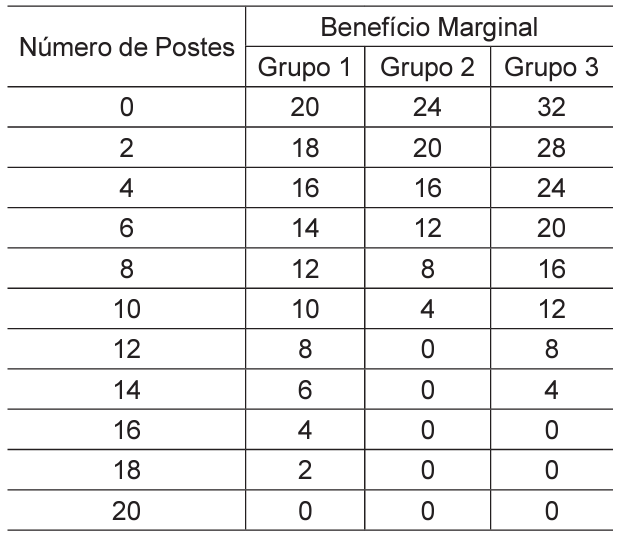
Sabe-se que, para a prefeitura, o custo de instalação de cada poste é de R$ 16,00.
Nesse contexto, conclui-se que,
Os resultados de cada indivíduo i estão apresentados na seguinte Tabela:
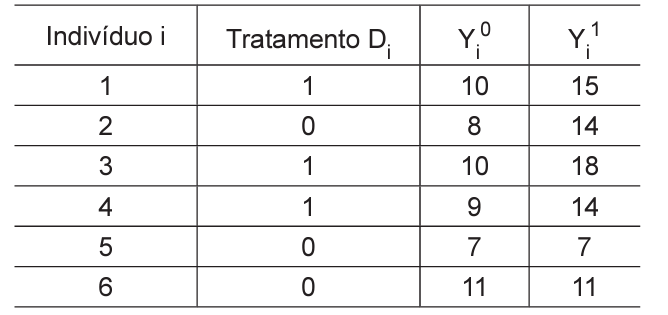
Na Tabela,
• Yi 1 representa o resultado para o indivíduo i, caso ele participe do programa.
• Yi 0 representa o resultado para o indivíduo i, caso ele não participe do programa.
• Di = 1 indica que o indivíduo i foi tratado (participou do programa) e 0 caso contrário.
Qual o Efeito Médio do Programa – EMP (Average Treatment Effect - ATE) e o Efeito Médio do Programa sobre os Tratados – EMPT (Average Treatment Effect for the Treated - ATT)?
No Pareamento por Escore de Propensão, um algoritmo utilizado para emparelhar cada sujeito tratado com um ou mais sujeitos não tratados que têm as pontuações de propensão mais próximas é o pareamento por
Equação I
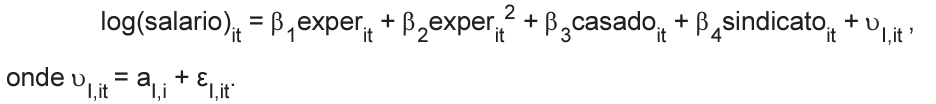
O p-valor do Teste de Hausman obtido é igual a 0,001.
Equação II
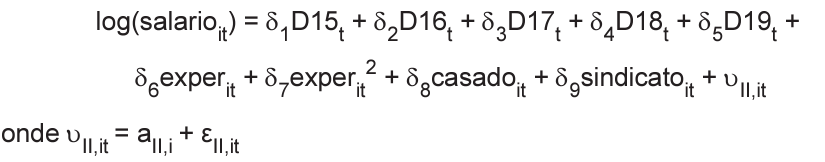
O p-valor do Teste de Hausman obtido é igual a 0,265.
A base de dados é composta pelas seguintes variáveis:
• salario = salário real; • exper = anos de experiência profissional;
• casado = variável dummy igual a 1 se casado e 0 caso contrário;
• sindicato = variável dummy igual a 1 se sindicalizado e 0 caso contrário; • D15,D16,D17,D18 e D19 são os efeitos fixos de cada ano no tempo;
• aI,i e aII,i são os efeitos fixos não observados associados aos trabalhadores das Equações I e II, respectivamente;
• εI,it e εII,it são os termos de erro das Equações I e II, respectivamente.
Com base nos resultados dos Testes de Hausman e considerando o nível de significância a 5%, conclui-se que os coeficientes
O modelo de Regressão com Descontinuidade (RDD) é uma técnica estatística usada para avaliar o impacto causal de uma variável independente em uma variável dependente, quando essa variável independente ultrapassa um certo limite ou ponto de corte.
Suponha que se esteja investigando o efeito do número de horas de estudo (variável independente) no desempenho em um teste (variável dependente). Assumindo-se que haja um ponto de corte de 5 horas de estudo e que se deseje verificar se há algum efeito no resultado do teste ao se ultrapassar esse ponto de corte.
A equação para esse modelo pode ser expressa da seguinte forma:
Yi = 60 + 5Xi + 8Di + ϵi ,
onde
• Yi é o desempenho no teste para o indivíduo i;
• Xi é o número de horas de estudo para o indivíduo i;
• Di é uma variável indicadora que vale 1 se Xi > 5 horas e 0 caso contrário para o indivíduo i;
• ϵi é o termo de erro para o indivíduo i.
Ao se comparar um estudante que estuda 6 horas para um teste com um outro que estuda 4 horas, de acordo com o modelo RDD apresentado acima, verifica-se que o
Yt = 3 + 0,5Yt-1 + ut ,
onde E(ut) =0 e Var(ut) = 6. Assuma, também, que ut e Yt-1 são independentes.
Nesse cenário, qual é a variância de Yt?
• taxa de desemprego do País Z em 2016 = 7%;
• taxa de desemprego do País Z em 2018 = 5%;
• taxas de desemprego das Unidades de Controle (Países P, Q, R, S, T) em 2016 = variando de 6% a 8%;
• taxas de desemprego das Unidades de Controle (Países P, Q, R, S, T) em 2018 = variando de 4% a 6%;
• taxa de desemprego sintética do País Z em 2016 = 6,5%;
• taxa de desemprego prevista para o controle sintético em 2018: 6%.
Nessa situação, qual foi o efeito estimado da política sobre a taxa de desemprego do País Z no ano seguinte à implementação da política de redução do seguro-desemprego?
Considere o seguinte sistema de equações, em suas respectivas formas estruturais:
qd = α1p +α2z + α3y + ε1 (demanda)
qs = β1p + ε2 (oferta)
qd = qs (equilíbrio),
onde qd é a quantidade demandada de um bem; qs é a quantidade ofertada do mesmo bem; p é o preço do bem; z e y são variáveis explicativas exógenas; ε1 e ε2 são os termos de erro das funções de demanda e oferta, respectivamente; α1 , α2 , α3 e β1 são coeficientes de inclinação.
Nesse contexto, no sistema de determinação da oferta e demanda,
Considere que a análise DAG foi utilizada para auxiliar na definição das restrições na identificação de um modelo VAR estrutural (SVAR) aplicado à política monetária. O modelo é constituído a partir das seguintes variáveis: Taxa Selic, PIB, câmbio nominal e taxa de inflação. Considere o DAG abaixo.
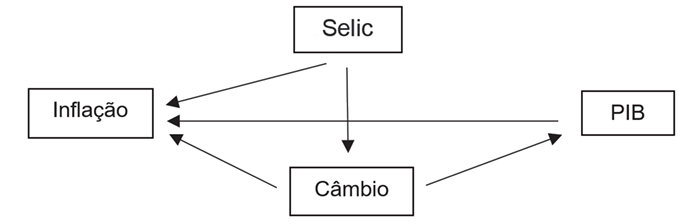
Nesse contexto, verifica-se que
Os modelos dinâmicos de dados em painel envolvem tanto dados de séries temporais quanto de seção transversal. Esses modelos frequentemente incorporam variáveis dependentes defasadas e regressores endógenos, o que pode levar a problemas de endogeneidade.
O modelo GMM aborda problemas de endogeneidade e autocorrelação em modelos dinâmicos de dados em painel. Ele faz isso utilizando variáveis instrumentais (IVs) e explorando a estrutura dos dados, para criar condições de momento que auxiliam na estimativa consistente de parâmetros.
Um dos principais testes usados para avaliar a adequação do modelo é o teste de Sargan-Hansen.
O teste de Sargan-Hansen
No Texto para Discussão do Ipea, é apresentada a seguinte Tabela que sumariza o resultado do teste de causalidade de Granger entre duas variáveis: Expectativa de Dívida Líquida do Setor Público (EDLSP) e a diferença da Expectativa de Superávit Primário (dESP), em que d representa a primeira diferença da série, entre janeiro de 2001 e junho de 2006.
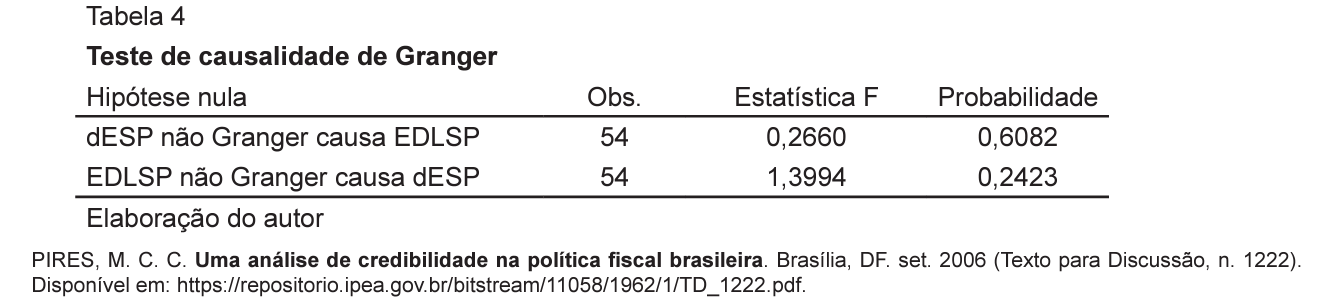
As informações da Tabela permitem inferir o seguinte resultado:
As formas mais utilizadas para testar a existência de cointegração entre as séries são:
Nesse contexto, as principais metodologias utilizadas para a previsão de séries econômicas estacionárias, considerando-se a utilização de uma única série temporal ou de diversas séries temporais, são as seguintes:
Yi = β1 + β2Xi + β3X2i + β4 X3i + u1i , modelo explicativo 0, onde Y é a variável dependente; X, a variável explicativa; β1 , β2 , β3 e β4 , os coeficientes da regressão; u, o termo de erro, e o subscrito i indica a i-ésima observação.
No entanto, considere que, por diversos motivos, o pesquisador decida estimar outros modelos (equações 1, 2, 3 e 4), cujas notações foram alteradas para distingui-los do modelo explicativo verdadeiro (modelo explicativo 0):
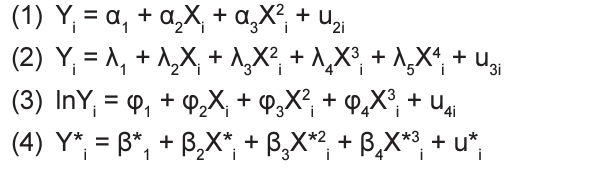
Essa decisão poderia levar a erros de especificação, já que os modelos 1, 2, 3 e 4 são diferentes do modelo explicativo verdadeiro (modelo equação 0), o que permite concluir que
Sobre esses testes considere as afirmativas abaixo.
I - O teste de Hansen investiga a exogeneidade dos instrumentos e a sua hipótese nula é que o modelo é corretamente especificado e os instrumentos em conjunto são válidos.
II - O teste Arellano-Bond AR (2) testa a autocorrelação serial, para o qual se deve rejeitar a hipótese nula de ausência de correlação serial de primeira e segunda ordem no termo de erro.
III - O teste Arellano-Bond AR (2) testa a autocorrelação serial, sob hipótese nula de ausência de correlação serial de segunda ordem no termo de erro.
Está correto o que se afirma em
Nesses modelos,
Quando um processo estocástico possui suas média, variância e autocovariância constantes ao longo do tempo, diz-se que este é um processo estocástico
O filtro HP
Sendo assim, a