Questões de Concurso Público TRT - 21ª Região (RN) 2010 para Analista Judiciário - Tecnologia da Informação
Foram encontradas 19 questões
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81724
Banco de Dados
Texto associado
É importante especificar como as entidades dentro de um dado
conjunto de entidades e os relacionamentos dentro de um conjunto
de relacionamentos podem ser identificados. Conceitualmente,
entidades e relacionamentos individuais são distintos, e, sob a ótica
de banco de dados, a diferença entre eles deve ser estabelecida com
base em seus atributos. Nesse sentido, tais distinções podem ser
feitas por meio de chaves. Em relação ao conceito de chaves, julgue
os itens a seguir.
conjunto de entidades e os relacionamentos dentro de um conjunto
de relacionamentos podem ser identificados. Conceitualmente,
entidades e relacionamentos individuais são distintos, e, sob a ótica
de banco de dados, a diferença entre eles deve ser estabelecida com
base em seus atributos. Nesse sentido, tais distinções podem ser
feitas por meio de chaves. Em relação ao conceito de chaves, julgue
os itens a seguir.
A chave candidata, conjunto de um ou mais atributos tomados coletivamente, permite identificar de maneira unívoca uma entidade em um conjunto de entidades.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81725
Banco de Dados
Texto associado
É importante especificar como as entidades dentro de um dado
conjunto de entidades e os relacionamentos dentro de um conjunto
de relacionamentos podem ser identificados. Conceitualmente,
entidades e relacionamentos individuais são distintos, e, sob a ótica
de banco de dados, a diferença entre eles deve ser estabelecida com
base em seus atributos. Nesse sentido, tais distinções podem ser
feitas por meio de chaves. Em relação ao conceito de chaves, julgue
os itens a seguir.
conjunto de entidades e os relacionamentos dentro de um conjunto
de relacionamentos podem ser identificados. Conceitualmente,
entidades e relacionamentos individuais são distintos, e, sob a ótica
de banco de dados, a diferença entre eles deve ser estabelecida com
base em seus atributos. Nesse sentido, tais distinções podem ser
feitas por meio de chaves. Em relação ao conceito de chaves, julgue
os itens a seguir.
Uma chave estrangeira é um atributo ou uma combinação de atributos em uma relação, cujos valores são necessários para equivaler somente à chave primária de outra relação.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81730
Banco de Dados
Texto associado
No que se refere às técnicas de programação utilizando banco de
dados, julgue os itens de 55 a 60.
dados, julgue os itens de 55 a 60.
A injeção de SQL (SQL injection, relacionada à structured query language - linguagem de consulta estruturada) é uma técnica de injeção de código que explora a vulnerabilidade de segurança da camada de banco de dados de uma aplicação. Quando se consegue inserir uma ou mais instruções SQL dentro de uma consulta, ocorre o fenômeno.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81731
Banco de Dados
Texto associado

Considerando a linguagem de definição de dados e o código acima,
que tem como objetivo criar duas relações estados e municípios,
julgue os itens de 58 a 60.
Considerando a linguagem de definição de dados e o código acima,
que tem como objetivo criar duas relações estados e municípios,
julgue os itens de 58 a 60.
Considere a visão do banco de dados (view), resultante do código abaixo, que cria uma lista com nome de município, área do município, sigla do estado e área do estado. Nesse caso, essa lista é atualizada automaticamente sempre que for atualizada a relação estados e(ou) municípios.
Create view area_municipios_estados_view as
select estados.sigla, municipios.nome,
municipios.area area_municipio, estados.area area_estado
from estados,municipios
where estados.ibge=municipios.ibge
Create view area_municipios_estados_view as
select estados.sigla, municipios.nome,
municipios.area area_municipio, estados.area area_estado
from estados,municipios
where estados.ibge=municipios.ibge
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81733
Banco de Dados
Texto associado
Considerando a linguagem de definição de dados e o código acima,
que tem como objetivo criar duas relações estados e municípios,
julgue os itens de 58 a 60.
Considerando a linguagem de definição de dados e o código acima,
que tem como objetivo criar duas relações estados e municípios,
julgue os itens de 58 a 60.
A expressão SQL abaixo terá como resultado nome do município, área do município e sigla do estado que tem o menor município em tamanho (menor área).

Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81734
Banco de Dados
Texto associado
Considerando o modelo relacional de dados, julgue os itens
subsecutivos.
subsecutivos.
A primeira forma normal estabelece que os atributos da relação contêm apenas valores atômicos.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81735
Banco de Dados
Texto associado
Considerando o modelo relacional de dados, julgue os itens
subsecutivos.
subsecutivos.
A dependência funcional é uma associação que se estabelece entre dois ou mais atributos de uma relação e define-se do seguinte modo: se A e B são atributos ou conjuntos de atributos, da relação R, diz-se que B é funcionalmente dependente de A se cada um dos valores de A em R tem associado a si um e um só valor de B em R.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81736
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
É recomendável o uso de índices do tipo clustered em colunas que sofram alterações frequentes, visando diminuir o "nível de folheamento" da página de índices.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81737
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
O Database Engine Tuning Advisor (DTA), ferramenta utilizada para capturar o rastreio dos eventos que ocorrem em uma carga de trabalho típica para o aplicativo, mostra como o SQL Server resolve consultas internamente e fornece uma interface gráfica para otimização de consultas.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81738
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
Os índices do tipo clustered determinam a ordem física dos dados em uma tabela e mostram-se particularmente eficientes em colunas pesquisadas frequentemente por uma faixa de valores ou quando o valor do registro é único na tabela.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81739
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
O ideal é que cada tabela possua pelo menos dois índices do tipo clustered - um para a chave primária e outro para a chave estrangeira principal -, a fim de permitir maior velocidade no acesso aos joins.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81740
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
Suponha que um índice do tipo unique tenha sido configurado em uma coluna. Nesse caso, não será possível configurar outra coluna, nessa mesma tabela, com índice do mesmo tipo, visto que cada tabela permite apenas um índice do tipo unique.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81741
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
A configuração dinâmica de valores no fill factor, para determinado índice entre 0% e 100%, permite ajustar o armazenamento e o desempenho de dados de índice. Desse modo, o mecanismo de banco de dados executa estatísticas sobre a tabela para manter a porcentagem de espaço livre especificada no fill factor, em cada página, a cada inserção de dados na tabela.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81742
Banco de Dados
Texto associado
Acerca de desempenho e otimização de consultas SQL no SQL
Server 2008, julgue os itens de 63 a 69.
Server 2008, julgue os itens de 63 a 69.
O particionamento de tabelas e índices no SQL Server (table partitioning) divide uma tabela em várias unidades que podem ser difundidas por mais de um grupo de arquivos em um banco de dados. Esse procedimento, porém, não influencia o desempenho de consultas, nessa tabela, independentemente do tipo de consulta executada ou da configuração de hardware associada às unidades.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81743
Banco de Dados
Texto associado
Acerca de sistemas de suporte a decisão e data warehousing, julgue
os itens a seguir.
os itens a seguir.
Em um data warehouse, cada linha em uma tabela fato corresponde a uma medida, representada por um valor aditivo, em que necessariamente essas medidas não compartilham a mesma granularidade.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81744
Banco de Dados
Texto associado
Acerca de sistemas de suporte a decisão e data warehousing, julgue
os itens a seguir.
os itens a seguir.
Em um modelo do tipo estrela (star schema), devido à ligação entre as tabelas dimensionais e suas respectivas fontes de dados, as dimensões são dependentes de códigos operacionais de produção. Desse modo, nessas tabelas, convenciona-se usar como chave primária as mesmas utilizadas no ambiente de produção - origem dos dados.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81745
Banco de Dados
Texto associado
Acerca de sistemas de suporte a decisão e data warehousing, julgue
os itens a seguir.
os itens a seguir.
O data mining é um processo automático de descoberta de padrões, de conhecimento em bases de dados, que utiliza, entre outros, árvores de decisão e métodos bayesianos como técnicas para classificação de dados.
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81754
Banco de Dados
Texto associado

Considerando as tabelas acima e seus relacionamentos, julgue os
itens seguintes.
Considerando as tabelas acima e seus relacionamentos, julgue os
itens seguintes.
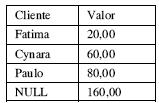
Considerando o SQL Server 2008, a execução do código SQL abaixo terá como resposta o resultado mostrado na tabela que relaciona cliente e valor do curso.
SELECT a.nomecliente Cliente, SUM(c.valorcurso) Valor
FROM tbcliente a
LEFT JOIN tbClienteCurso c
ON a.idcliente = c.idcliente
RIGHT JOIN tbcurso b
ON b.idcurso = c.idcurso
GROUP BY a.nomecliente
WITH CUBE
ORDER BY 2
SELECT a.nomecliente Cliente, SUM(c.valorcurso) Valor
FROM tbcliente a
LEFT JOIN tbClienteCurso c
ON a.idcliente = c.idcliente
RIGHT JOIN tbcurso b
ON b.idcurso = c.idcurso
GROUP BY a.nomecliente
WITH CUBE
ORDER BY 2
Ano: 2010
Banca:
CESPE / CEBRASPE
Órgão:
TRT - 21ª Região (RN)
Prova:
CESPE - 2010 - TRT - 21ª Região (RN) - Analista Judiciário - Tecnologia da Informação |
Q81755
Banco de Dados
Texto associado
Considerando as tabelas acima e seus relacionamentos, julgue os
itens seguintes.
Considerando as tabelas acima e seus relacionamentos, julgue os
itens seguintes.
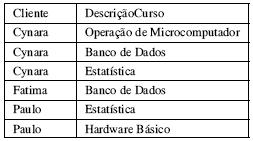
Na versão do SQL Server 2008, a execução do código SQL abaixo produzirá o resultado mostrado na tabela seguinte.
SELECT a.nomecliente Cliente, b.Descricaocurso
FROM tbcliente a
LEFT OUTER JOIN tbClienteCurso c
ON a.idcliente = c.idcliente
LEFT OUTER JOIN tbcurso b
ON b.idcurso = c.idcurso
WHERE a.nomecliente like '%a%'
ORDER BY 1
SELECT a.nomecliente Cliente, b.Descricaocurso
FROM tbcliente a
LEFT OUTER JOIN tbClienteCurso c
ON a.idcliente = c.idcliente
LEFT OUTER JOIN tbcurso b
ON b.idcurso = c.idcurso
WHERE a.nomecliente like '%a%'
ORDER BY 1