Questões de Concurso Público MPO 2013 para Gestor, Categoria Profissional 4
Foram encontradas 27 questões
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333884
Banco de Dados
Com relação à engenharia de software e arquiteturas, julgue os itens que se seguem.
Os modelos de fluxos de dados são utilizados para modelar a forma com que os dados são processados em um sistema, sendo úteis no nível de análise dos dados.
Os modelos de fluxos de dados são utilizados para modelar a forma com que os dados são processados em um sistema, sendo úteis no nível de análise dos dados.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333885
Banco de Dados
Acerca de banco de dados, organização de arquivos, modelos de dados e sistemas gerenciadores de banco de dados (SGBD), julgue os itens seguintes.
Em um banco de dados pequeno, em um sistema embarcado, sem um sistema operacional básico para o gerenciamento de arquivo, a organização de arquivos com agrupamento de múltiplas tabelas permite a redução da quantidade de códigos para a implementação do sistema.
Em um banco de dados pequeno, em um sistema embarcado, sem um sistema operacional básico para o gerenciamento de arquivo, a organização de arquivos com agrupamento de múltiplas tabelas permite a redução da quantidade de códigos para a implementação do sistema.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333886
Banco de Dados
Acerca de banco de dados, organização de arquivos, modelos de dados e sistemas gerenciadores de banco de dados (SGBD), julgue os itens seguintes.
Ao empregar as linguagens de programação para manipular os dados, os programadores trabalham, usualmente, no nível físico de abstração
Ao empregar as linguagens de programação para manipular os dados, os programadores trabalham, usualmente, no nível físico de abstração
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333887
Banco de Dados
Acerca de banco de dados, organização de arquivos, modelos de dados e sistemas gerenciadores de banco de dados (SGBD), julgue os itens seguintes.
Caso, em uma organização de arquivos com estrutura de acesso com base em índice, o campo de classificação do arquivo não seja um campo chave, um recurso para aumentar a velocidade de recuperação de registros que não tenham valor distinto de classificação é a utilização de um índice de agrupamento (clustering)
Caso, em uma organização de arquivos com estrutura de acesso com base em índice, o campo de classificação do arquivo não seja um campo chave, um recurso para aumentar a velocidade de recuperação de registros que não tenham valor distinto de classificação é a utilização de um índice de agrupamento (clustering)
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333888
Banco de Dados
Acerca de banco de dados, organização de arquivos,modelos de dados e sistemas gerenciadores de banco de dados (SGBD), julgue os itens seguintes.
Os modelos de dados semânticos, como o orientado a objetos e o relacional estendido, oferecem suporte a objetos complexos e a dados não estruturados.
Os modelos de dados semânticos, como o orientado a objetos e o relacional estendido, oferecem suporte a objetos complexos e a dados não estruturados.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333889
Banco de Dados

Com base na figura acima, que apresenta modelo relacional de dados em que os atributos com um círculo escuro são os identificadores (chaves primárias) das entidades, julgue os itens a seguir.
Os programadores participam apenas de um projeto.
Os programadores participam apenas de um projeto.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333890
Banco de Dados
Com base na figura acima, que apresenta modelo relacional de dados em que os atributos com um círculo escuro são os identificadores (chaves primárias) das entidades, julgue os itens a seguir.
A entidade “Atividade” está de acordo com uma relação na 2.ª Forma Normal.
A entidade “Atividade” está de acordo com uma relação na 2.ª Forma Normal.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333891
Banco de Dados
Com base na figura acima, que apresenta modelo relacional de dados em que os atributos com um círculo escuro são os identificadores (chaves primárias) das entidades, julgue os itens a seguir.
Os atributos da entidade “Escala” não estão de acordo com uma relação na 3.ª Forma Normal.
Os atributos da entidade “Escala” não estão de acordo com uma relação na 3.ª Forma Normal.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333892
Banco de Dados
Com base na figura acima, que apresenta modelo relacional de dados em que os atributos com um círculo escuro são os identificadores (chaves primárias) das entidades, julgue os itens a seguir.
Um programador não pode ser escalado para uma mesma atividade mais de uma vez.
Um programador não pode ser escalado para uma mesma atividade mais de uma vez.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333893
Banco de Dados
Com base na figura acima, que apresenta modelo relacional de dados em que os atributos com um círculo escuro são os identificadores (chaves primárias) das entidades, julgue os itens a seguir.
Um analista pode participar de diversos projetos, podendo um projeto contar com a presença de diversos analistas
Um analista pode participar de diversos projetos, podendo um projeto contar com a presença de diversos analistas
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333894
Banco de Dados

Considerando a figura acima, que apresenta um modelo de entidades e de relacionamento, julgue os próximos itens.
A cardinalidade da associação unária da entidade “Conteúdo” está modelada imprecisamente como (0, n), uma vez que todo o conteúdo composto deveria estar, obrigatoriamente, vinculado a um conteúdo mais geral.
A cardinalidade da associação unária da entidade “Conteúdo” está modelada imprecisamente como (0, n), uma vez que todo o conteúdo composto deveria estar, obrigatoriamente, vinculado a um conteúdo mais geral.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333895
Banco de Dados
Considerando a figura acima, que apresenta um modelo de entidades e de relacionamento, julgue os próximos itens.
Na conversão do relacionamento denominado “Exige” em uma tabela, uma das colunas da tabela associativa deve ser “Cod_Concurso”.
Na conversão do relacionamento denominado “Exige” em uma tabela, uma das colunas da tabela associativa deve ser “Cod_Concurso”.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333896
Banco de Dados
Considerando a figura acima, que apresenta um modelo de entidades e de relacionamento, julgue os próximos itens.
No atributo “Dificuldade” do relacionamento “Exige”, todos os conteúdos de um cargo têm o mesmo grau de dificuldade.
No atributo “Dificuldade” do relacionamento “Exige”, todos os conteúdos de um cargo têm o mesmo grau de dificuldade.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333897
Banco de Dados
Considerando a figura acima, que apresenta um modelo de entidades e de relacionamento, julgue os próximos itens.
Independentemente da representação, “Prova” é uma entidade fraca.
Independentemente da representação, “Prova” é uma entidade fraca.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333898
Banco de Dados
Considerando a figura acima, que apresenta um modelo de entidades e de relacionamento, julgue os próximos itens.
O conjunto de atributos que descreve “Títulos” inclui “Data_Realização”, “Nr_Candidato” e “Pontos”.
O conjunto de atributos que descreve “Títulos” inclui “Data_Realização”, “Nr_Candidato” e “Pontos”.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333899
Banco de Dados
No que se refere às técnicas de recuperação de informações usadas em bancos de dados textuais, julgue os itens que se seguem.
A técnica denominada extração de termos (term extraction) compreende a análise de especialistas no domínio do texto e a incorporação de informações linguísticas às informações estatísticas sobre os termos do documento.
A técnica denominada extração de termos (term extraction) compreende a análise de especialistas no domínio do texto e a incorporação de informações linguísticas às informações estatísticas sobre os termos do documento.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333900
Banco de Dados
No que se refere às técnicas de recuperação de informações usadas em bancos de dados textuais, julgue os itens que se seguem.
De acordo com a fórmula da técnica IDF (inverse document frequence), o termo com maior número de ocorrências em trechos de um texto gera menor índice na fórmula de prioridades, sendo esse termo o mais representativo do documento.
De acordo com a fórmula da técnica IDF (inverse document frequence), o termo com maior número de ocorrências em trechos de um texto gera menor índice na fórmula de prioridades, sendo esse termo o mais representativo do documento.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333901
Banco de Dados
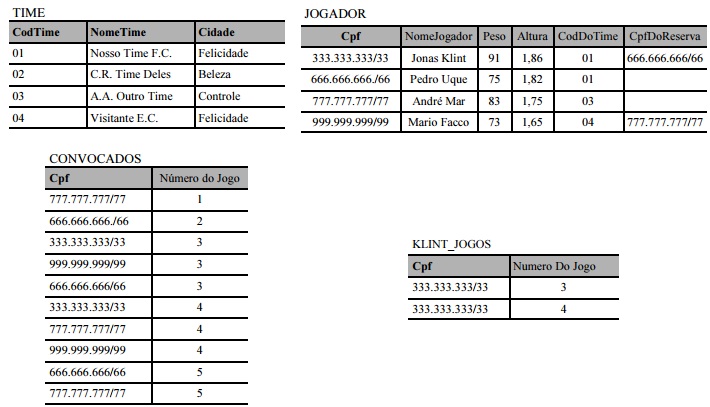
Com base nas tabelas acima e nos conceitos da álgebra relacional, julgue os itens subsecutivos.
Caso se aplique a operação relacional de divisão CONVOCADOS ÷ KLINT_JOGOS, o resultado será o seguinte:
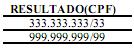
Caso se aplique a operação relacional de divisão CONVOCADOS ÷ KLINT_JOGOS, o resultado será o seguinte:
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333902
Banco de Dados
Com base nas tabelas acima e nos conceitos da álgebra relacional, julgue os itens subsecutivos.

Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
MPO
Prova:
CESPE - 2013 - MPOG - Gestor - Categoria Profissional 4 |
Q333903
Banco de Dados
Com base nas tabelas acima e nos conceitos da álgebra relacional, julgue os itens subsecutivos.
Mediante a expressão, ((TIME ▷◁ CodTime=CoddoTime JOGADOR) ▷◁ Cpf=CpfdoReserva JOGADOR) os dados de todos os jogadores cadastrados e os dados de seus respectivos times serão apresentados, bem como os dados disponíveis dos reservas de cada jogador, quando existentes, serão acrescentados.
Mediante a expressão, ((TIME ▷◁ CodTime=CoddoTime JOGADOR) ▷◁ Cpf=CpfdoReserva JOGADOR) os dados de todos os jogadores cadastrados e os dados de seus respectivos times serão apresentados, bem como os dados disponíveis dos reservas de cada jogador, quando existentes, serão acrescentados.