Questões de Concurso Público SEBRAE-NACIONAL 2024 para Analista Técnico II – Cientista de Dados
Foram encontradas 5 questões
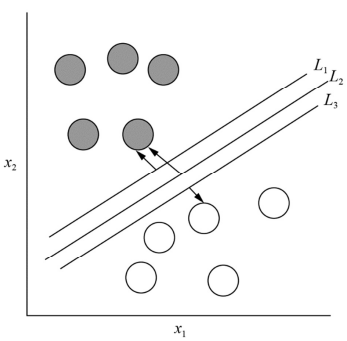
Considerando a figura precedente, assinale a opção correta em
relação ao algoritmo de SVM (support vector machine).
Em aprendizado de máquina, especialmente em algoritmos de árvores de decisão, é fundamental avaliar como os dados são organizados e classificados em diferentes níveis da árvore. Três conceitos-chave que auxiliam na construção e otimização dessas árvores são o gini impurity, a entropy e o information gain. A respeito desses conceitos, julgue os itens a seguir.
I Gini impurity mede a redução da entropy após a divisão de um conjunto de dados com base em um atributo.
II Entropy mede a quantidade de incerteza ou impureza no conjunto de dados.
III Information gain mede a probabilidade de uma nova instância ser classificada incorretamente, com base na distribuição de classes no conjunto de dados.
Assinale a opção correta.
Em relação aos conceitos do algoritmo k-means, julgue os itens a seguir.
I É importante continuar as iterações do algoritmo k-means até que a mudança na posição dos centroides entre as iterações seja menor que um limite predefinido.
II No coeficiente de silhueta, quanto mais próximo o coeficiente estiver de 1, menor a distância entre os clusters; 0 indica que os dados podem estar no cluster errado; valores negativos sugerem que o ponto está na borda.
III Apesar de um maior número clusters sempre reduzir o SSE (sum of squared errors), isso não significa que mais clusters sempre sejam melhores, pois um número muito grande de clusters pode levar a overfitting do modelo.
Assinale a opção correta.