Questões de Concurso Público TRE-MG 2013 para Analista Judiciário - Estatística
Foram encontradas 29 questões
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452947
Estatística
Marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452948
Estatística
Em uma população finita de tamanho N, onde existem k indivíduos com uma característica de interesse, ao se selecionar uma amostra aleatória de tamanho n sem reposição, o número de indivíduos com a característica na amostra (R) é uma variável aleatória com distribuição hipergeométrica. A probabilidade de se ter exatamente r indivíduos na amostra com a característica de interesse é dada por
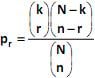 , onde max (0, n – N + k) = r = min (k, n).
, onde max (0, n – N + k) = r = min (k, n).
Analise.
I. Para N = 100, k = 20, n = 10 e r = 3, E(R) = 2 e Var(R) = 144/99.
II. Para N = 100, k = 20, n = 5 e r = 3, E(R) = 1 e Var(R) = 8/10.
III. Para N = 10000, k = 2000, n = 100 e r = 3, E(R) = 20 e Var(R) = 15,84.
IV. Para N = 10000, k = 1000, n = 100 e r = 3, E(R) = 10 e Var(R) ˜ 9.
V. Para N = 10000, k = 2000, n = 10 e r = 0, P(R = 0) ˜ 0,1074.
Estão corretas apenas as alternativas
, onde max (0, n – N + k) = r = min (k, n). Analise.
I. Para N = 100, k = 20, n = 10 e r = 3, E(R) = 2 e Var(R) = 144/99.
II. Para N = 100, k = 20, n = 5 e r = 3, E(R) = 1 e Var(R) = 8/10.
III. Para N = 10000, k = 2000, n = 100 e r = 3, E(R) = 20 e Var(R) = 15,84.
IV. Para N = 10000, k = 1000, n = 100 e r = 3, E(R) = 10 e Var(R) ˜ 9.
V. Para N = 10000, k = 2000, n = 10 e r = 0, P(R = 0) ˜ 0,1074.
Estão corretas apenas as alternativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452949
Estatística
Após o ajuste de um modelo de regressão linear múltipla, com n observações e k variáveis explicativas e o termo de intercepto, a tabela ANOVA pode ser utilizada na avaliação do modelo ajustado. As linhas da tabela ANOVA correspondem às fontes de variação devido à regressão, ao resíduo e ao total, e as colunas, aos graus de liberdade, as somas de quadrado, aos quadrados médios, a estatística F e ao valor p. Diante do exposto, analise.
I. O número de graus de liberdade da fonte regressão é k, da fonte resíduos é n-k-1 e do total é n-1.
II. O coeficiente de determinação múltipla corresponde à razão entre a soma de quadrados devido à regressão e à soma de quadrados total. Ele varia entre 0 e 1 e quanto mais próximo de 1, melhor é o modelo.
III. O coeficiente de determinação múltipla corrigido leva em consideração o número de observações e o número de variáveis explicativas incluídas no modelo e corresponde a 1 menos a razão entre o quadrado médio do resíduo e a soma de quadrado total dividida pelos seus graus de liberdade. Ele varia entre zero e 1 e quanto mais próximo de 1, melhor o modelo.
IV. A estatística F corresponde à razão entre o quadrado médio da regressão e o quadrado médio do resíduo e é utilizada para testar a significância do modelo ajustado quando comparado com o modelo nulo.
V. O valor p corresponde à probabilidade de significância ou ao nível descritivo do teste da estatística F, que é calculada utilizando a distribuição de Fisher-Snedecor com número de graus de liberdade iguais ao da fonte de variação da regressão e da fonte de variação do resíduo. Valores pequenos, em geral inferiores a 5%, são uma forte indicação de que o modelo é não significativo.
Estão corretas apenas as afirmativas
I. O número de graus de liberdade da fonte regressão é k, da fonte resíduos é n-k-1 e do total é n-1.
II. O coeficiente de determinação múltipla corresponde à razão entre a soma de quadrados devido à regressão e à soma de quadrados total. Ele varia entre 0 e 1 e quanto mais próximo de 1, melhor é o modelo.
III. O coeficiente de determinação múltipla corrigido leva em consideração o número de observações e o número de variáveis explicativas incluídas no modelo e corresponde a 1 menos a razão entre o quadrado médio do resíduo e a soma de quadrado total dividida pelos seus graus de liberdade. Ele varia entre zero e 1 e quanto mais próximo de 1, melhor o modelo.
IV. A estatística F corresponde à razão entre o quadrado médio da regressão e o quadrado médio do resíduo e é utilizada para testar a significância do modelo ajustado quando comparado com o modelo nulo.
V. O valor p corresponde à probabilidade de significância ou ao nível descritivo do teste da estatística F, que é calculada utilizando a distribuição de Fisher-Snedecor com número de graus de liberdade iguais ao da fonte de variação da regressão e da fonte de variação do resíduo. Valores pequenos, em geral inferiores a 5%, são uma forte indicação de que o modelo é não significativo.
Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452950
Estatística
“A análise de resíduos de um modelo de regressão linear múltipla pode ser utilizada para verificar se o modelo se adequa aos dados. Nesse sentido, gráficos e testes ajudam a identificar discrepâncias entre os valores observados da variável resposta e os valores preditos pelo modelo.” De acordo com o trecho anterior, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Quando os pontos do diagrama de dispersão do resíduo padronizado versus variável explicativa apresentar uma tendência, a inclusão do logaritmo da variável explicativa pode melhorar o modelo.
( ) Quando os pontos do diagrama de dispersão do resíduo versus variável omitida no modelo apresentar uma tendência linear, a inclusão da variável omitida pode melhorar o modelo.
( ) Quando o desenho esquemático (boxplot) dos resíduos padronizados apresentar observações além dos limites superior ou inferior, existe uma forte indicação da presença de outliers que devem ser investigados.
( ) Quando o desenho esquemático dos resíduos tem a distância entre a mediana e o primeiro quartil e a distância entre a mediana e o terceiro quartil bem distintas, existe uma forte indicação de que a distribuição das observações são assimétricas e o componente aleatório do modelo pode não ter distribuição normal.
( ) A suposição de homocedasticidade dos resíduos pode ser avaliada através de: teste de Levéne; teste de Brown & Forsythe; gráfico de resíduos versus valores preditos pelo modelo; gráfico do resíduo versus cada uma das variáveis incluídas no modelo.
A sequência está correta em
( ) Quando os pontos do diagrama de dispersão do resíduo padronizado versus variável explicativa apresentar uma tendência, a inclusão do logaritmo da variável explicativa pode melhorar o modelo.
( ) Quando os pontos do diagrama de dispersão do resíduo versus variável omitida no modelo apresentar uma tendência linear, a inclusão da variável omitida pode melhorar o modelo.
( ) Quando o desenho esquemático (boxplot) dos resíduos padronizados apresentar observações além dos limites superior ou inferior, existe uma forte indicação da presença de outliers que devem ser investigados.
( ) Quando o desenho esquemático dos resíduos tem a distância entre a mediana e o primeiro quartil e a distância entre a mediana e o terceiro quartil bem distintas, existe uma forte indicação de que a distribuição das observações são assimétricas e o componente aleatório do modelo pode não ter distribuição normal.
( ) A suposição de homocedasticidade dos resíduos pode ser avaliada através de: teste de Levéne; teste de Brown & Forsythe; gráfico de resíduos versus valores preditos pelo modelo; gráfico do resíduo versus cada uma das variáveis incluídas no modelo.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452951
Estatística
O modelo de componentes principais é utilizado para representar a estrutura de variância-covariância em função de um número reduzido de combinações lineares das variáveis originais, com o objetivo de se ter uma redução de dados e uma melhor interpretação destes. Para o vetor aleatório 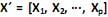 com matriz de covariância S e autovalores iguais a
com matriz de covariância S e autovalores iguais a  , e as combinações lineares:
, e as combinações lineares:
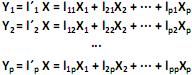
O modelo de componentes principais corresponde às combinações lineares não correlacionadas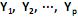 com vetores de coeficientes
com vetores de coeficientes 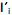 de comprimento unitário, que apresentam as maiores variâncias Var
de comprimento unitário, que apresentam as maiores variâncias Var 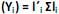 . Diante do exposto, é correto afirmar que
. Diante do exposto, é correto afirmar que
I. o primeiro componente principal é a combinação linear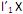 que maximiza Var
que maximiza Var 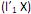 sujeito a
sujeito a 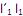 = 1.
= 1.
II. o i-ésimo componente principal é a combinação linear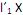 que maximiza Var
que maximiza Var 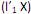 = 1 e Cov (
= 1 e Cov (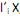 ,
, 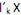 ) = 0, para k < i.
) = 0, para k < i.
III. sendo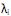 os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por
os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por 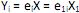 +
+  , onde i = 1, ··· p.
, onde i = 1, ··· p.
IV. Var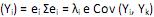 = 0, para i = 1,2, ···, p e i ≠ k.
= 0, para i = 1,2, ···, p e i ≠ k.
V. a proporção da variância total devido ao k-ésimo componente principal é dada por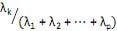 para k = 1, ···, p.
para k = 1, ···, p.
Estão corretas apenas as afirmativas
com matriz de covariância S e autovalores iguais a , e as combinações lineares: O modelo de componentes principais corresponde às combinações lineares não correlacionadas
com vetores de coeficientes de comprimento unitário, que apresentam as maiores variâncias Var . Diante do exposto, é correto afirmar que I. o primeiro componente principal é a combinação linear
que maximiza Var sujeito a = 1. II. o i-ésimo componente principal é a combinação linear
que maximiza Var = 1 e Cov (, ) = 0, para k < i. III. sendo
os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por + , onde i = 1, ··· p. IV. Var
= 0, para i = 1,2, ···, p e i ≠ k. V. a proporção da variância total devido ao k-ésimo componente principal é dada por
para k = 1, ···, p. Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452952
Estatística
O modelo de análise fatorial representa a estrutura de cova- riância entre muitas variáveis aleatórias 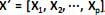 , através de poucas variáveis não observáveis F´ = [
, através de poucas variáveis não observáveis F´ = [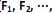
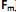 ] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz
] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz 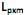 é conhecida como matriz das cargas fatoriais e seus elementos,
é conhecida como matriz das cargas fatoriais e seus elementos,  , carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas.
, carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas.
( ) No modelo fatorial ortogonal, as variáveis não observáveis F e e são independentes, E(F) = 0, V(F) = E(F´F) = I, E(e) = 0, V(e) = E(e´e) = ?. A matriz ? é não diagonal, V(X) = S = L´L + ? e Cov (X, F) = L.
( ) Um método de estimação para as cargas do modelo fatorial ortogonal é através de componentes principais, onde se utiliza a decomposição espectral da matriz S.
( ) Para se utilizar o método de máxima verossimilhança para estimar as cargas, é acrescida a suposição de que F e e têm distribuição normal multivariada. As comunalidades (elementos da diagonal LL´) têm como estimadores a proporção da variância total estimada pelo particular fator.
( ) Para melhorar a explicação do modelo fatorial, sem alterar a ortogonalidade dos fatores, muitas vezes, usa- se uma transformação ortogonal das cargas fatoriais, que, consequentemente, transforma os fatores. Esse procedimento é conhecido como rotação fatorial.
( ) Dependendo da natureza dos dados, os fatores não precisam ser ortogonais. Assim, para melhorar a explicação do modelo fatorial, pode-se utilizar a rotação oblíqua, onde cada variável é expressa em termos de um número máximo de fatores.
A sequência está correta em
, através de poucas variáveis não observáveis F´ = [ ] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz é conhecida como matriz das cargas fatoriais e seus elementos, , carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas. ( ) No modelo fatorial ortogonal, as variáveis não observáveis F e e são independentes, E(F) = 0, V(F) = E(F´F) = I, E(e) = 0, V(e) = E(e´e) = ?. A matriz ? é não diagonal, V(X) = S = L´L + ? e Cov (X, F) = L.
( ) Um método de estimação para as cargas do modelo fatorial ortogonal é através de componentes principais, onde se utiliza a decomposição espectral da matriz S.
( ) Para se utilizar o método de máxima verossimilhança para estimar as cargas, é acrescida a suposição de que F e e têm distribuição normal multivariada. As comunalidades (elementos da diagonal LL´) têm como estimadores a proporção da variância total estimada pelo particular fator.
( ) Para melhorar a explicação do modelo fatorial, sem alterar a ortogonalidade dos fatores, muitas vezes, usa- se uma transformação ortogonal das cargas fatoriais, que, consequentemente, transforma os fatores. Esse procedimento é conhecido como rotação fatorial.
( ) Dependendo da natureza dos dados, os fatores não precisam ser ortogonais. Assim, para melhorar a explicação do modelo fatorial, pode-se utilizar a rotação oblíqua, onde cada variável é expressa em termos de um número máximo de fatores.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452953
Estatística
Os Modelos Lineares Generalizados (MLG) são definidos a partir de três características: o componente aleatório, que estabelece a distribuição da variável resposta; o componente sistemático, que determina as variáveis explicativas a serem utilizadas como preditoras no modelo e estabelece a equação de predição como linear; e, a função de ligação, que estabelece a relação entre o componente sistemático e a esperança matemática da variável resposta. Diante do exposto, analise.
I. O componente aleatório permite que a distribuição seja da família exponencial ou de suas generalizações, contemplando, entre outras, as distribuições: normal, Bernoulli, Poisson, Gama, Normal, Inversa, Exponencial, Binomial.
II. A função de ligação deve transformar o domínio da variável aleatória de forma a permitir que qualquer valor do componente sistemático seja admissível. As funções mais utilizadas são: identidade, inversa, inversa ao quadrado, logarítmica, logito, probito, complemento log-log, potência, Box-Cox e Aranda-Ordaz.
III. O ajuste de um MLG pode ser feito pelo método de máxima verossimilhança. As equações normais produzidas, em geral, precisam ser resolvidas por processos iterativos. Os mais utilizados são o método de Newton- Raphson e o de escore de Fisher. Eles são distintos, qualquer que seja a função de ligação.
IV. Para dados de contagem com distribuição de Poisson, o MLG corresponde ao modelo de regressão de Poisson. A função de ligação mais utilizada é a logarítmica. Quando existe superdispersão nos dados, adota-se uma generalização de MLG que admite o parâmetro de dispersão.
V. Vários tipos de resíduo podem ser utilizados para avaliar a qualidade do ajuste de um MLG, entre eles, resíduos ordinários, resíduos de Pearson, resíduos de Pearson padronizados e componente do desvio.
Estão corretas apenas as afirmativas
I. O componente aleatório permite que a distribuição seja da família exponencial ou de suas generalizações, contemplando, entre outras, as distribuições: normal, Bernoulli, Poisson, Gama, Normal, Inversa, Exponencial, Binomial.
II. A função de ligação deve transformar o domínio da variável aleatória de forma a permitir que qualquer valor do componente sistemático seja admissível. As funções mais utilizadas são: identidade, inversa, inversa ao quadrado, logarítmica, logito, probito, complemento log-log, potência, Box-Cox e Aranda-Ordaz.
III. O ajuste de um MLG pode ser feito pelo método de máxima verossimilhança. As equações normais produzidas, em geral, precisam ser resolvidas por processos iterativos. Os mais utilizados são o método de Newton- Raphson e o de escore de Fisher. Eles são distintos, qualquer que seja a função de ligação.
IV. Para dados de contagem com distribuição de Poisson, o MLG corresponde ao modelo de regressão de Poisson. A função de ligação mais utilizada é a logarítmica. Quando existe superdispersão nos dados, adota-se uma generalização de MLG que admite o parâmetro de dispersão.
V. Vários tipos de resíduo podem ser utilizados para avaliar a qualidade do ajuste de um MLG, entre eles, resíduos ordinários, resíduos de Pearson, resíduos de Pearson padronizados e componente do desvio.
Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452954
Estatística
O modelo de regressão logística é um caso particular de um modelo linear generalizado em que o componente aleatório tem distribuição Bernoulli e a função de ligação é a logito. Diante do exposto, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade: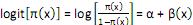 , ou seja, p(x) aumenta ou diminui como uma função linear de x.
, ou seja, p(x) aumenta ou diminui como uma função linear de x.
( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:

( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
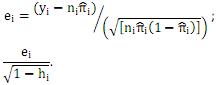
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade:
, ou seja, p(x) aumenta ou diminui como uma função linear de x. ( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:
( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452955
Estatística
Uma variável aleatória Gama é definida para valores reais e positivos e sua função densidade é dada por
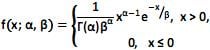
com parâmetros α > 0 e ß > 0.
Diante do exposto, analise as afirmativas.
I. Pode-se demonstrar que E(x) = αß e Var(x) = αß2.
II. A função gama é dada por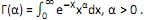
III. Pode-se mostrar que G(α) = (α – 1) G(α – 1) e para α inteiro, G(α) = (α – 1)!.
IV. Quando α = 1, a função densidade da gama e igual à distribuição exponencial com parâmetro ß.
V. Quando α = v/2 e ß = 2, com v > 0 inteiro, a função densidade da gama é igual à distribuição Qui-quadrado com ? graus de liberdade.
Estão corretas apenas as afirmativas
com parâmetros α > 0 e ß > 0.
Diante do exposto, analise as afirmativas.
I. Pode-se demonstrar que E(x) = αß e Var(x) = αß2.
II. A função gama é dada por
III. Pode-se mostrar que G(α) = (α – 1) G(α – 1) e para α inteiro, G(α) = (α – 1)!.
IV. Quando α = 1, a função densidade da gama e igual à distribuição exponencial com parâmetro ß.
V. Quando α = v/2 e ß = 2, com v > 0 inteiro, a função densidade da gama é igual à distribuição Qui-quadrado com ? graus de liberdade.
Estão corretas apenas as afirmativas