Questões de Concurso Público TJ-AC 2024 para Analista Judiciário - Analista de Ciência de Dados
Foram encontradas 24 questões
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457909
Algoritmos e Estrutura de Dados
O ecossistema Hadoop se refere aos vários componentes
da biblioteca de software Apache Hadoop, incluindo
projetos de código aberto e ferramentas complementares
para armazenar e processar Big Data. Algumas das
ferramentas mais conhecidas incluem HDFS, Pig, YARN,
MapReduce, Spark, HBase Oozie, Sqoop e Kafka, cada
uma com função específica no ecossistema Hadoop. São
funções dos componentes do ecossistema Hadoop:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457910
Algoritmos e Estrutura de Dados
Para classificar os processos tramitados no TJ-AC em
duas categorias (deferidos e indeferidos), um analista
escolheu um algoritmo que divide os dados de entrada em
duas regiões separadas por uma linha e resulta em uma
simetria na classificação, de forma que o ponto mais
próximo de cada classe está a uma distância d do ponto
médio entre os dois grupos de classe (hiperplano). O
algoritmo descrito é denominado:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457911
Algoritmos e Estrutura de Dados
Observe o gráfico a seguir.
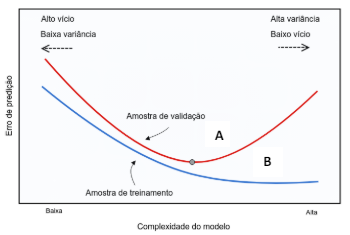
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457912
Algoritmos e Estrutura de Dados
Seja a matriz de confusão obtida na avaliação de
desempenho de um modelo de aprendizado treinado para
classificar processos julgados pelo TJ-AC:

Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457913
Algoritmos e Estrutura de Dados
Uma das métricas mais comumente utilizadas para
comparar resultados de algoritmos de clusterização é
obtida por meio da fórmula (b-a)/ max(a,b), em que:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457914
Algoritmos e Estrutura de Dados
Uma rede neural foi implementada a partir da arquitetura
Multilayer Perceptron (MLP) e o conjunto de dados foi
dividido em holdout com 50% para conjunto de
treinamento, 30% para conjunto de validação e 20% para
conjunto de teste. Se, durante o treinamento e a validação
da referida rede ocorreu underfitting, dois fatores que
podem ter condicionado tal fenômeno são:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457915
Algoritmos e Estrutura de Dados
A camada de uma rede convolucional que tem como
função primária reduzir progressivamente o tamanho
espacial do volume de dados de entrada por meio do
mapeamento de seções de features e diminuição dos
pesos de treinamento é denominada camada de
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457916
Algoritmos e Estrutura de Dados
Random Forest são algoritmos de aprendizado de máquina
utilizados para classificação ou regressão, sendo vantajoso
em relação às árvores de decisão no caso de
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457917
Algoritmos e Estrutura de Dados
O pré-processamento é um conjunto de atividades que
envolvem preparação, organização e estruturação de
dados, sendo fundamental no desempenho do modelo de
aprendizagem de máquina. Tais atividades contemplam
métodos e técnicas de limpeza, transformação, integração
e redução de dimensionalidade. Os métodos que podem
ser utilizados para o tratamento de dados faltantes são:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457918
Algoritmos e Estrutura de Dados
A árvore de decisão ilustrada a seguir foi modelada com
base nos dados de registros de ocorrência da dengue no
estado do Acre nos últimos cinco (5) anos e será utilizada
para tomada de decisão acerca da priorização na
disponibilização de vacinas.
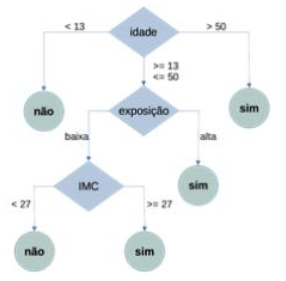
Qual é a evidência de que esse modelo foi construído usando o algoritmo C4.5 ou suas variantes, e não usando o ID3?
Qual é a evidência de que esse modelo foi construído usando o algoritmo C4.5 ou suas variantes, e não usando o ID3?
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457919
Algoritmos e Estrutura de Dados
Para reduzir a dimensionalidade de um conjunto de dados
bidimensionais, foi executado o algoritmo PCA (do inglês,
Principal Component Analysis). Se o PCA produzir como
resultado dois autovalores de mesmo valor, significa que
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457920
Algoritmos e Estrutura de Dados
PV-DM (do inglês, Paragraph Vector Distributed Memory) é
um método de aprendizado de máquina utilizado no
processamento de dados textuais. A ideia central é prever
uma palavra (de contexto) a partir de um conjunto de
palavras amostrado aleatoriamente – palavras de contexto
e ID de parágrafo. Quando aplicado sobre um conjunto de
documentos textuais (por exemplo, os processos deferidos
arquivados no TJ-AC), qual a vantagem desse método em
relação ao método BOW, baseado em contagem de
palavras?
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457921
Algoritmos e Estrutura de Dados
Considere a sentença a seguir.
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457922
Algoritmos e Estrutura de Dados
No processo de otimização de redes neurais artificiais,
diferentes métodos e técnicas são utilizados para
determinar os melhores parâmetros do aprendizado. Para
reduzir o overfitting, uma das técnicas amplamente
utilizadas é a regularização, que apresenta como
características:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457925
Algoritmos e Estrutura de Dados
Para implementar inovações no processo de decisão de
sentenças judiciais, um analista do TJ-AC decidiu pelo uso
da Tradução Automática Neural (do inglês, Neural Machine
Translation - NMT) após comparar diferentes técnicas de
Processamento de Linguagem Natural (PLN). As
vantagens dessa técnica em relação à Tradução
Automática Estatística (do inglês, Statistic Machine
Translation - SMT) são:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457926
Algoritmos e Estrutura de Dados
Redes neurais recorrentes (RNNs) são modelos de
aprendizado profundo treinados para reconhecer padrões
em dados sequenciais (texto, imagens, genomas,
caligrafia, palavra falada ou dados de séries numéricas),
em que componentes se inter-relacionam com base em
regras complexas de semântica e sintaxe. São
características das redes neurais recorrentes:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457927
Algoritmos e Estrutura de Dados
A multicolinearidade ocorre quando duas ou mais variáveis
independentes encontram-se altamente correlacionadas,
causando instabilidade na estimação dos parâmetros e
pode comprometer a interpretação dos modelos de
regressão. Uma técnica alternativa para lidar com a
multicolinearidade é a
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457928
Algoritmos e Estrutura de Dados
Os algoritmos de agrupamento buscam identificar padrões
existentes em conjuntos de dados, podendo ser do tipo
particionais, hierárquicos ou baseados na otimização da
função custo. É um exemplo de agrupamento hierárquico:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457929
Algoritmos e Estrutura de Dados
O Processamento de Linguagem Natural (PLN) é a área da
inteligência artificial que analisa, reconhece e/ou gera
textos em linguagens humanas (ou natural). Para
processar dados textuais, é necessário primeiramente
transformá-los em valores numéricos, sendo utilizados
algoritmos do tipo word embeddings, tais como glove, tf-idf,
word2vector e bag of words (BOW). São características do
algoritmo word2vector:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457930
Algoritmos e Estrutura de Dados
O LDA (do inglês, Latent Dirichlet Allocation) é um modelo
de aprendizado não supervisionado e estatístico utilizado
no Processamento de Linguagem Natural (PLN). No
processo de treinamento, o modelo LDA gera tópicos,
sendo que cada tópico incorpora uma quantidade de
palavras. Sob a mesma lógica, o resultado da aplicação do
LDA sobre um conjunto de documentos textuais pode ser
resumido como: