Questões de Concurso Público TJ-DFT 2022 para Analista Judiciário - Estatística
Foram encontradas 40 questões
Q1929189
Estatística
A função que representa um fenômeno físico é y = 10+ 4x.
Sabendo-se que x é uma variável aleatória com variância igual a
10, a variância de y é:
Q1929190
Estatística
Um arquivo de dados que foi compartilhado com você tem a
extensão “csv”. Esse arquivo está nomeado como “arq.csv” e
está no seu diretório de trabalho.
As quatro primeiras linhas desse arquivo estão apresentadas a seguir.
“1200,00”|”F”|”28”
“1387,00”|”M”|”26”
“3285,00”|”F”|”35”
“2784,00”|”M”|”-“
O símbolo “ – “, que está localizado na linha 4, coluna 3, significa um valor perdido ou “sem resposta”.
O comando mais adequado para a leitura do arquivo é:
As quatro primeiras linhas desse arquivo estão apresentadas a seguir.
“1200,00”|”F”|”28”
“1387,00”|”M”|”26”
“3285,00”|”F”|”35”
“2784,00”|”M”|”-“
O símbolo “ – “, que está localizado na linha 4, coluna 3, significa um valor perdido ou “sem resposta”.
O comando mais adequado para a leitura do arquivo é:
Q1929191
Estatística
Um estatístico deseja selecionar uma amostra aleatória simples,
com reposição, de uma população em que a variância é
conhecida e igual a 40.000.
A amostra precisa atender ao seguinte critério:
A amplitude máxima do intervalo bilateral de 95% de confiança para a média populacional deve ser de 200.
O menor tamanho de amostra que atende à condição descrita acima é:
A amostra precisa atender ao seguinte critério:
A amplitude máxima do intervalo bilateral de 95% de confiança para a média populacional deve ser de 200.
O menor tamanho de amostra que atende à condição descrita acima é:
Q1929192
Estatística
Utilizando a Linguagem R tem-se um objeto x como consta a
seguir.
x
## [1] 1 3 4 3 4 <NA>
## Levels: 1 3 4
is.factor(x)
## [1] TRUE
O comando que resulta na soma dos elementos numéricos de x é:
x
## [1] 1 3 4 3 4 <NA>
## Levels: 1 3 4
is.factor(x)
## [1] TRUE
O comando que resulta na soma dos elementos numéricos de x é:
Q1929193
Estatística
Um processo experimental gera vetores com grande quantidade
de observações.
Em uma execução do experimento, são gerados 5 milhões de vetores, cada um de tamanho 1.000.
Para reduzir o espaço de armazenamento de dados, armazena-se apenas a soma, ∑x e a soma dos quadrados, ∑x2 das observações de cada vetor.
Se, para um destes vetores, ∑x = 800 e ∑x2 = 999,64 então o coeficiente de variação é, aproximadamente:
Em uma execução do experimento, são gerados 5 milhões de vetores, cada um de tamanho 1.000.
Para reduzir o espaço de armazenamento de dados, armazena-se apenas a soma, ∑x e a soma dos quadrados, ∑x2 das observações de cada vetor.
Se, para um destes vetores, ∑x = 800 e ∑x2 = 999,64 então o coeficiente de variação é, aproximadamente:
Q1929194
Estatística
Um estatístico deseja testar se os efeitos de utilizar dois
lubrificantes, de marcas diferentes, no processo de fabricação de
uma indústria, são distintos.
Para isso, ele planeja executar um experimento controlado, aplicando cada marca de lubrificantes em uma amostra de máquinas idênticas, ou seja, a escolha das máquinas não afeta o resultado do teste. As amostras de máquinas para testar cada lubrificante têm o mesmo tamanho.
Desse modo, o estatístico selecionou uma amostra aleatória simples, supondo a população infinita, com distribuição normal, e desvios padrões conhecidos iguais a 1,5 e 1,6.
O número de máquinas selecionadas para testar cada lubrificante, de tal forma que o erro na estimação da diferença entre as médias observadas seja menor que 1, com 95% de confiança, é:
Para isso, ele planeja executar um experimento controlado, aplicando cada marca de lubrificantes em uma amostra de máquinas idênticas, ou seja, a escolha das máquinas não afeta o resultado do teste. As amostras de máquinas para testar cada lubrificante têm o mesmo tamanho.
Desse modo, o estatístico selecionou uma amostra aleatória simples, supondo a população infinita, com distribuição normal, e desvios padrões conhecidos iguais a 1,5 e 1,6.
O número de máquinas selecionadas para testar cada lubrificante, de tal forma que o erro na estimação da diferença entre as médias observadas seja menor que 1, com 95% de confiança, é:
Q1929195
Estatística
Duas sociedades empresárias, X e Y, produzem o mesmo produto
e têm seus processos de produção sob controle e centrados no
ponto médio da faixa de especificação.
Ambas operam com os limites de tolerâncias de 3 desvios padrões, ou seja, 3 sigmas acima e 3 sigmas abaixo do ponto médio.
Sabe-se que a amplitude da faixa de especificação é 0,21 e que os desvios padrões para as unidades X e Y são, respectivamente, 0,03 e 0,04. Com base na capacidade do processo (Cp), conclui-se que:
Ambas operam com os limites de tolerâncias de 3 desvios padrões, ou seja, 3 sigmas acima e 3 sigmas abaixo do ponto médio.
Sabe-se que a amplitude da faixa de especificação é 0,21 e que os desvios padrões para as unidades X e Y são, respectivamente, 0,03 e 0,04. Com base na capacidade do processo (Cp), conclui-se que:
Q1929196
Estatística
Um experimento de campo para aprimoramento do combate ao
ataque de formigas testou o efeito de um novo modelo de porta-iscas.
O experimento consistiu em espalhar 20 porta-iscas do novo modelo e, após um período de tempo, verificou-se o consumo das iscas em cada um dos recipientes.
Os resultados foram computados do seguinte modo: quando o consumo das iscas foi maior que a mediana histórica do consumo, registrou-se um sinal “+” (positivo), quando menor, um sinal “-” negativo e, se o consumo foi igual ao consumo mediano, o registrado foi um ponto “.”.
Os resultados do experimento foram: 15 positivos, 3 negativos e 2 pontos.
Para auxiliar nos cálculos, segue a tabela que apresenta os valores de 0,515; 0,518 e 0,520 multiplicados por uma constante k:
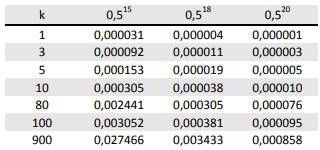
Utilizando o nível de 5% de significância, a conclusão do teste de hipótese é:
O experimento consistiu em espalhar 20 porta-iscas do novo modelo e, após um período de tempo, verificou-se o consumo das iscas em cada um dos recipientes.
Os resultados foram computados do seguinte modo: quando o consumo das iscas foi maior que a mediana histórica do consumo, registrou-se um sinal “+” (positivo), quando menor, um sinal “-” negativo e, se o consumo foi igual ao consumo mediano, o registrado foi um ponto “.”.
Os resultados do experimento foram: 15 positivos, 3 negativos e 2 pontos.
Para auxiliar nos cálculos, segue a tabela que apresenta os valores de 0,515; 0,518 e 0,520 multiplicados por uma constante k:
Utilizando o nível de 5% de significância, a conclusão do teste de hipótese é:
Q1929197
Estatística
Um estatístico utilizou um modelo de regressão linear simples, Y = β0 + β1X + ε, para fazer predições.
O modelo, com 20 observações, foi bem ajustado, atendendo a todos os pressupostos necessários, e os resultados foram:
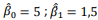 ; soma dos quadrados dos resíduos, 9; variância
de x, 28 e média de x, 22.
; soma dos quadrados dos resíduos, 9; variância
de x, 28 e média de x, 22.
O intervalo bilateral de 95% de confiança para predição quando é, aproximadamente:
O modelo, com 20 observações, foi bem ajustado, atendendo a todos os pressupostos necessários, e os resultados foram:
; soma dos quadrados dos resíduos, 9; variância
de x, 28 e média de x, 22.
O intervalo bilateral de 95% de confiança para predição quando é, aproximadamente:
Q1929198
Estatística
Com o objetivo de testar se um treinamento virtual melhoraria
o desempenho de uma determinada tarefa, 5 indivíduos foram
submetidos ao treinamento virtual e comparados com outros
5 indivíduos que não tiveram esse treinamento.
Os indivíduos foram submetidos a uma mesma tarefa repetidas vezes, e seus desempenhos foram mensurados. Posteriormente, os indivíduos foram ordenados conforme mostra a tabela abaixo.
A Posição 1 indica a melhor performance e 10, a pior. O Grupo “T” indica que o indivíduo teve treinamento, e “NT”, que não teve treinamento.
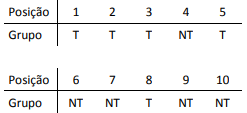
Utilizou-se a Linguagem R para efetuar vários testes.
Entretanto, o resultado para o teste de hipóteses mais adequado é:
Os indivíduos foram submetidos a uma mesma tarefa repetidas vezes, e seus desempenhos foram mensurados. Posteriormente, os indivíduos foram ordenados conforme mostra a tabela abaixo.
A Posição 1 indica a melhor performance e 10, a pior. O Grupo “T” indica que o indivíduo teve treinamento, e “NT”, que não teve treinamento.
Utilizou-se a Linguagem R para efetuar vários testes.
Entretanto, o resultado para o teste de hipóteses mais adequado é:
Q1929199
Estatística
Suponha X = (X1, X2, X3, X4)t uma distribuição normal
multivariada com matriz de covariância
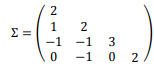
A variância de X1, X2, X3, X4 é:
A variância de X1, X2, X3, X4 é:
Q1929200
Estatística
O gestor de uma grande sociedade empresária, para definir
metas e indicadores de desempenho, cria uma base de dados
com os resultados da última avaliação realizada com os
funcionários. Essa avaliação formou uma base que pretende ser
utilizada para tomada de decisões como promoções, aumentos
salariais, transferências e até demissões.
Cada funcionário foi avaliado segundo os critérios de pontualidade, assiduidade, motivação, satisfação no trabalho e cumprimento das tarefas designadas, recebendo uma nota de 0 a 10 pontos para cada critério. Para simplificar a análise, agruparam-se os funcionários por similaridade de acordo com os critérios mencionados.
A técnica de análise multivariada mais adequada para criar os grupos e analisar o desempenho dos funcionários é:
Cada funcionário foi avaliado segundo os critérios de pontualidade, assiduidade, motivação, satisfação no trabalho e cumprimento das tarefas designadas, recebendo uma nota de 0 a 10 pontos para cada critério. Para simplificar a análise, agruparam-se os funcionários por similaridade de acordo com os critérios mencionados.
A técnica de análise multivariada mais adequada para criar os grupos e analisar o desempenho dos funcionários é:
Q1929201
Estatística
Considere a matriz de variância e covariância dada por
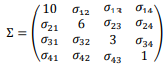
Suponha que os dois maiores autovalores dessa matriz sejam λ1=10,9 e λ2=4,1.
Considerando a análise de componentes principais, o percentual de variação explicada por λ1 e λ2 é:
Suponha que os dois maiores autovalores dessa matriz sejam λ1=10,9 e λ2=4,1.
Considerando a análise de componentes principais, o percentual de variação explicada por λ1 e λ2 é:
Q1929202
Estatística
Suponha que a única condição para que ocorra ação da justiça
itinerante hoje seja a realização de ação da justiça itinerante no
dia imediatamente anterior, isto é, não depende das condições
de dias anteriores.
Considere também que, se ocorrer ação da justiça itinerante hoje, então ocorrerá amanhã com probabilidade 0,6; e se ocorrer ação da justiça itinerante hoje, então não ocorrerá amanhã com probabilidade 0,3.
Associamos a ação “ocorrer ação da justiça itinerante” ao estado 1 e “não ocorrer ação da justiça itinerante” ao estado 0, o espaço de estados da cadeia de Markov é: S = {0, 1}. A matriz de transição, parcial, é dada por:
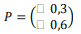
Considerando a distribuição inicial π = (0,5 0,5), a distribuição do sistema na etapa “amanhã” é:
Considere também que, se ocorrer ação da justiça itinerante hoje, então ocorrerá amanhã com probabilidade 0,6; e se ocorrer ação da justiça itinerante hoje, então não ocorrerá amanhã com probabilidade 0,3.
Associamos a ação “ocorrer ação da justiça itinerante” ao estado 1 e “não ocorrer ação da justiça itinerante” ao estado 0, o espaço de estados da cadeia de Markov é: S = {0, 1}. A matriz de transição, parcial, é dada por:
Considerando a distribuição inicial π = (0,5 0,5), a distribuição do sistema na etapa “amanhã” é:
Q1929203
Estatística
No contexto de Séries Temporais são impostas restrições de
estacionariedade e invertibilidade para os modelos ARIMA(p, d, q).
Considerando a notação na forma de operador retardo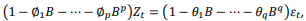 sendo
sendo 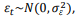 o modelo, na forma de equação de
diferenças, que está de acordo com as restrições é:
o modelo, na forma de equação de
diferenças, que está de acordo com as restrições é:
Considerando a notação na forma de operador retardo
sendo o modelo, na forma de equação de
diferenças, que está de acordo com as restrições é:
Q1929204
Estatística
Considere o modelo SARIMA(p,d,q)(P,D,Q)12 dado pela equação:
(1 - B)3(1 + 0,4B - 0,5B2)(1 - 0,8B12)Xt = (1 - 0,3B)(1 - 0,3B12 + 0,6B24)εt.
As ordens p, d, q, P, D, Q são, respectivamente:
(1 - B)3(1 + 0,4B - 0,5B2)(1 - 0,8B12)Xt = (1 - 0,3B)(1 - 0,3B12 + 0,6B24)εt.
As ordens p, d, q, P, D, Q são, respectivamente:
Q1929205
Estatística
Uma sociedade empresária que atua na área de logística
transporta frutas até o limite de 800 caixas.
A sociedade empresária recebeu um pedido para transportar 200 caixas de laranjas, a R$ 20,00 de lucro por caixa; pelo menos 100 caixas de ameixas, a R$ 10,00 de lucro por caixa e, no máximo 200 caixas de amoras, a R$ 10,00 de lucro por caixa.
Considerando como x1, x2, x3 as quantidades de caixas de laranjas, ameixas e amoras, respectivamente, o modelo de programação linear que representa de que forma a empresa deverá carregar o caminhão para obter o lucro máximo é:
A sociedade empresária recebeu um pedido para transportar 200 caixas de laranjas, a R$ 20,00 de lucro por caixa; pelo menos 100 caixas de ameixas, a R$ 10,00 de lucro por caixa e, no máximo 200 caixas de amoras, a R$ 10,00 de lucro por caixa.
Considerando como x1, x2, x3 as quantidades de caixas de laranjas, ameixas e amoras, respectivamente, o modelo de programação linear que representa de que forma a empresa deverá carregar o caminhão para obter o lucro máximo é:
Q1929206
Estatística
No modelo de filas M/M/1/ /FIFO, existe um único posto de
atendimento. Não existe limitação de capacidade no espaço
reservado para a fila de espera, sendo que a ordem de acesso de
usuários ao serviço segue a ordem de chegada dos ususários ao
sistema (FIFO).
/FIFO, existe um único posto de
atendimento. Não existe limitação de capacidade no espaço
reservado para a fila de espera, sendo que a ordem de acesso de
usuários ao serviço segue a ordem de chegada dos ususários ao
sistema (FIFO).
Suponha que, num sistema desse tipo, as chegadas ocorrem conforme uma distribuição de Poisson com valor médio de 12 chegadas por hora, e o tempo de serviço segue uma distribuição exponencial com média de 4 minutos.
Nesse caso, a taxa de utilização do servidor único nesse sistema é:
/FIFO, existe um único posto de
atendimento. Não existe limitação de capacidade no espaço
reservado para a fila de espera, sendo que a ordem de acesso de
usuários ao serviço segue a ordem de chegada dos ususários ao
sistema (FIFO). Suponha que, num sistema desse tipo, as chegadas ocorrem conforme uma distribuição de Poisson com valor médio de 12 chegadas por hora, e o tempo de serviço segue uma distribuição exponencial com média de 4 minutos.
Nesse caso, a taxa de utilização do servidor único nesse sistema é:
Q1929207
Estatística
Considere um sistema de fila de um cartório com servidor único,
fila ilimitada e fonte de chegada ilimitada.
Suponha que as chegadas ocorrem de acordo com uma distribuição de Poisson, e os atendimentos, de acordo com uma distribuição exponencial.
Se chegam em média 20 clientes por hora e o número médio de clientes no cartório é 2, cada cliente gasta, em média, para ser atendido:
Suponha que as chegadas ocorrem de acordo com uma distribuição de Poisson, e os atendimentos, de acordo com uma distribuição exponencial.
Se chegam em média 20 clientes por hora e o número médio de clientes no cartório é 2, cada cliente gasta, em média, para ser atendido:
Q1929208
Estatística
Em um modelo de simulação de uma fila com apenas um servidor
para atendimento, foram realizadas 9 replicações para
determinar o número médio de pessoas em fila.
Os resultados obtidos para cada replicação estão no quadro a seguir.
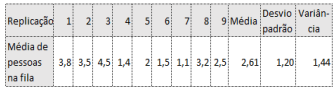
O intervalo bilateral de confiança de 95% para a média é, aproximadamente:
Os resultados obtidos para cada replicação estão no quadro a seguir.
O intervalo bilateral de confiança de 95% para a média é, aproximadamente: