Questões de Concurso Público CVM 2024 para Analista CVM - Perfil 7 - Ciência de Dados - Tarde
Foram encontradas 26 questões
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517623
Banco de Dados
Observe os conjuntos de dados a seguir.
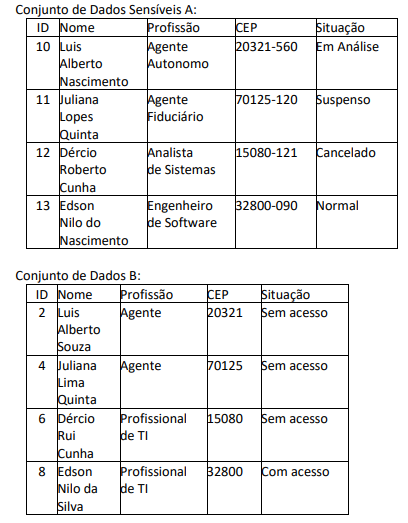
Para desidentificar o Conjunto de Dados Sensíveis A e gerar o
Conjunto de Dados B, a técnica de anonimização que deve ser
aplicada é o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517624
Banco de Dados
O analista João desenvolveu diversos dashboards na plataforma
Microsoft Power BI e solicitou ao programador web Pedro que
disponibilizasse aquelas análises no portal de acesso à
informação da CVM.
Para inserir os dashboards desenvolvidos por João na página web da CVM, o recurso do Power BI que Pedro deve usar é o(a):
Para inserir os dashboards desenvolvidos por João na página web da CVM, o recurso do Power BI que Pedro deve usar é o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517625
Banco de Dados
Para tomar decisões diárias, o analista João precisa consultar o
preço de diversas ações do mercado financeiro, bem como outros
dados da CVM. Contudo, ao acessar o ambiente de BigData da
CVM, João verificou que os preços das ações desse ambiente
demoravam para ser atualizados.
João procurou o arquiteto de BigData da CVM para tratar a dimensão da qualidade de dados denominada:
João procurou o arquiteto de BigData da CVM para tratar a dimensão da qualidade de dados denominada:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517628
Banco de Dados
As informações são a base de toda tomada de decisão e gestão
de empresas, sendo um diferencial importante o uso de grandes
volumes de dados de diversas fontes.
Nesse contexto, as soluções de Big Data para análise de dados devem ter a capacidade de:
Nesse contexto, as soluções de Big Data para análise de dados devem ter a capacidade de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517630
Banco de Dados
Texto associado
Texto 1
Aline, cientista de dados da CVM, foi designada para aferir a
reação à prova da CVM entre os usuários de uma rede social de
textos curtos usando técnicas de análise de sentimentos. Para
isso, ela realiza um processo de KDD. Nesse processo, Aline opta
por representar os textos obtidos da rede social no formato de
vetores reais de baixa dimensionalidade, calculados a partir das
representações das palavras obtidas de um modelo de
linguagem pré-treinado utilizando a técnica word2vec.
Considerando o texto 1, a fase do KDD em que Aline gera os
vetores a partir dos textos é chamada de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517632
Banco de Dados
Flávia, responsável pelo setor de análise de dados de uma rede
de concessionárias de carros, está realizando o pré-processamento dos dados dos clientes da rede. Entre os atributos
do conjunto de dados, estão os CPFs dos clientes, o seu sexo e a
quantidade de carros que eles já compraram na rede.
Esses três atributos podem ser classificados, respectivamente, como:
Esses três atributos podem ser classificados, respectivamente, como:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517634
Banco de Dados
Uma equipe de analistas de dados preparou um modelo preditivo
cuja entrada consiste em planilhas contendo uma matriz de
valores reais entre 1 e 10. Tais planilhas são obtidas de um
sistema externo à equipe. O modelo foi treinado com um
conjunto de planilhas que foi coletado pelos analistas, de forma a
obter uma amostra representativa dos dados a serem utilizados.
A média e o desvio padrão de duas colunas importantes foram
calculados do conjunto de treinamento, como uma forma simples
de verificar a consistência da distribuição dos dados, sendo seus
valores 4,89 e 3,08, respectivamente. O modelo obteve bons
resultados durante sua etapa de testes, com uma precisão de
94%.
Ao iniciar a operação do modelo com planilhas atuais, entretanto, os analistas observaram que o modelo teve um desempenho muito inferior, com precisão de apenas 72%. Investigando as planilhas recebidas, obtiveram a média e o desvio padrão para as duas colunas importantes com valores 5,34 e 3,68, respectivamente.
A explicação mais adequada à situação descrita é:
Ao iniciar a operação do modelo com planilhas atuais, entretanto, os analistas observaram que o modelo teve um desempenho muito inferior, com precisão de apenas 72%. Investigando as planilhas recebidas, obtiveram a média e o desvio padrão para as duas colunas importantes com valores 5,34 e 3,68, respectivamente.
A explicação mais adequada à situação descrita é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517635
Banco de Dados
Visando a maximizar a eficiência de uma equipe de auditores
fiscais, um sistema de classificação de documentação foi
encomendado à equipe de ciência de dados, com o objetivo de
decidir, com base nos documentos obtidos durante uma
fiscalização, se um exame detalhado de documentação é ou não
necessário.
Idealmente, o sistema permitiria aos auditores direcionar mais tempo às auditorias complexas e agilizar a análise dos casos mais simples, otimizando o custo de pessoal e equipamento especializado. Contudo, não examinar detalhadamente um caso complexo pode custar muito caro ao governo, a ponto de anular quaisquer ganhos obtidos usando o sistema com um pequeno número de erros.
Considerando esse cenário, e o fato de o sistema de classificação responder apenas “sim” ou “não” quanto à necessidade de exame detalhado, a métrica de classificação a ser maximizada pela equipe que irá implementar o sistema é:
Idealmente, o sistema permitiria aos auditores direcionar mais tempo às auditorias complexas e agilizar a análise dos casos mais simples, otimizando o custo de pessoal e equipamento especializado. Contudo, não examinar detalhadamente um caso complexo pode custar muito caro ao governo, a ponto de anular quaisquer ganhos obtidos usando o sistema com um pequeno número de erros.
Considerando esse cenário, e o fato de o sistema de classificação responder apenas “sim” ou “não” quanto à necessidade de exame detalhado, a métrica de classificação a ser maximizada pela equipe que irá implementar o sistema é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517636
Banco de Dados
Para ser utilizado em um modelo neural de regressão, um
conjunto de dados precisa ser tratado de tal forma que todos os
atributos de entrada sejam representados como um ou mais
valores numéricos no intervalo [0, 1].
Os atributos de uma observação são: idade (inteiro >= 18), escolaridade (fundamental, médio, superior, pós-graduação), estado de residência (Acre, Alagoas, …, Tocantins, incluindo Distrito Federal) e local de trabalho (empresa, home office, misto).
O número mínimo de valores necessários para representar uma observação com os atributos acima descritos para o modelo de regressão, de forma que não ocorra perda de informação ordinal nem inserção de vieses nos dados, é:
Os atributos de uma observação são: idade (inteiro >= 18), escolaridade (fundamental, médio, superior, pós-graduação), estado de residência (Acre, Alagoas, …, Tocantins, incluindo Distrito Federal) e local de trabalho (empresa, home office, misto).
O número mínimo de valores necessários para representar uma observação com os atributos acima descritos para o modelo de regressão, de forma que não ocorra perda de informação ordinal nem inserção de vieses nos dados, é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517637
Banco de Dados
Ao receber um conjunto de dados para elaborar um modelo
preditivo, uma equipe de analistas de dados percebeu que havia
uma quantidade significativa de dados faltantes em certos
atributos. Foi então debatido o uso de duas técnicas para lidar
com esse problema: (1) remoção de observações contendo dados
ausentes e (2) “inputação” multivariável, sendo que apenas uma
das duas seria aplicada.
Duas características do conjunto de dados que devem ser prioritariamente consideradas na escolha entre as duas técnicas são:
Duas características do conjunto de dados que devem ser prioritariamente consideradas na escolha entre as duas técnicas são:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517641
Banco de Dados
Uma certa organização gostaria de compartilhar dados com um
grupo de pesquisadores de uma universidade para a condução de
um estudo sobre problemas ergonômicos nos seus escritórios.
Entre os dados coletados, há informações sensíveis sobre seus
funcionários; portanto, o responsável pela coleta decidiu
anonimizar os dados. Isso foi feito removendo-se nomes e outros
campos identificadores e adicionando-se um número
identificador próprio a cada funcionário. Dessa forma, a
identidade dos funcionários seria preservada. Após a verificação
de uma amostra, o pesquisador responsável pelo estudo
recomendou medidas que deveriam ser aplicadas antes que os
dados pudessem ser aceitos para o estudo.
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517646
Banco de Dados
Documentos do Jupyter Notebook são salvos com a extensão
.ipynb, mas internamente eles são documentos do tipo:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517647
Banco de Dados
Observe o Modelo de Entidades e Relacionamentos a seguir.
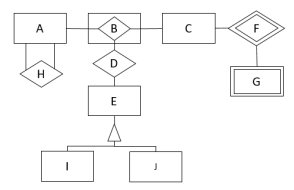
Com base nos relacionamentos apresentados, está explícito que:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517648
Banco de Dados
O modelo relacional representa o banco de dados como uma
coleção de relações. Considere a relação COLABORADOR
apresentada a seguir, cuja chave primária é Matricula.
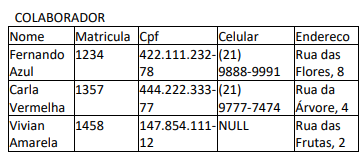
Na relação COLABORADOR, o(a):
Na relação COLABORADOR, o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517649
Banco de Dados
As transações em banco de dados possuem propriedades que
buscam proteger dados contra perdas ou danos.
A propriedade durabilidade tem relação com:
A propriedade durabilidade tem relação com:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517650
Banco de Dados
Os Sistemas Gerenciadores de Banco de Dados (SGBD) comerciais
implementam internamente técnicas para processar, otimizar e
executar consultas de alto nível.
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517651
Banco de Dados
Diante de várias reclamações de performance em resposta a
consultas a dados por meio de um dos sistemas estruturantes de
uma autarquia federal, a equipe de tecnologia identificou que o
motivo estava na lentidão para recuperação de registros na base
de dados utilizada pelo sistema. Para agilizar a recuperação de
registros em resposta a uma pesquisa que utiliza um campo que
comporta valores repetidos, a equipe de tecnologia criou índices.
Considerando que já existe um índice primário para o conjunto de dados em questão, a equipe criou um índice:
Considerando que já existe um índice primário para o conjunto de dados em questão, a equipe criou um índice:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517652
Banco de Dados
Janine é a responsável pela administração dos bancos de dados
gerenciados pelo PostgreSQL de uma autarquia federal. Durante
a criação de um banco de dados, Janine especificou a criação de
um tablespace diferente do tablespace default.
O tablespace criado por Janine:
O tablespace criado por Janine:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517653
Banco de Dados
O analista Gabriel fez um levantamento das bases de dados
existentes na CVM e percebeu que havia Data Marts distintos,
criados para atender a requisitos analíticos específicos de cada
Superintendência, como: Relações Institucionais, Auditoria e
Registro de Valores Imobiliários. Cada Data Mart foi construído
de forma independente, o que dificultava análises integradas
para relacionar dados das diferentes Superintendências. Gabriel
observou que havia várias dimensões em comum nos Data Marts.
Para permitir análises integradas padronizando e compartilhando
as dimensões em comum dos Data Marts da CVM, Gabriel
implementou um(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517654
Banco de Dados
Para apoiar análises sobre os fundadores de empresas ao longo
do tempo, elaborou-se, inicialmente, o seguinte modelo
multidimensional de dados, no qual a tabela FATO FUNDAÇÃO
EMPRESAS se relaciona com múltiplos valores da tabela
DIMENSÃO FUNDADOR.
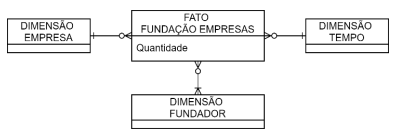
No caso apresentado, a implementação de uma dimensão multivalorada deve ser realizada por meio da aplicação da técnica de modelagem multidimensional:
No caso apresentado, a implementação de uma dimensão multivalorada deve ser realizada por meio da aplicação da técnica de modelagem multidimensional: