Questões de Concurso Público BRDE 2023 para Analista de Sistemas - Administração de Banco de Dados
Foram encontradas 22 questões
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107761
Banco de Dados
Uma escola que oferece aulas de reforço possui um cadastro de professores
especializados em alguma matéria e de alunos que precisam de reforço escolar em matérias
específicas. As tabelas estão desenhadas abaixo.

Solicitaram ao DBA que casasse as necessidades dos alunos com a especialidade dos professores, mas não deram muitos detalhes. O DBA preparou, então, três possibilidades de combinação, representadas pelas consultas SQL (padrão SQL99 ou superior) abaixo:
I. select nomea, nomep from professores natural join alunos II. select nomea, nomep from professores right join alunos on professores.materia = alunos.materia III. select nomea, nomep from professores full join alunos using (materia)
Selecione a alternativa que representa, nesta ordem, o número de tuplas resultantes das consultas I, II e III.
Solicitaram ao DBA que casasse as necessidades dos alunos com a especialidade dos professores, mas não deram muitos detalhes. O DBA preparou, então, três possibilidades de combinação, representadas pelas consultas SQL (padrão SQL99 ou superior) abaixo:
I. select nomea, nomep from professores natural join alunos II. select nomea, nomep from professores right join alunos on professores.materia = alunos.materia III. select nomea, nomep from professores full join alunos using (materia)
Selecione a alternativa que representa, nesta ordem, o número de tuplas resultantes das consultas I, II e III.
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107762
Banco de Dados
Considere a tabela ALUNOS criada usando o comando SQL (padrão SQL99 ou
superior) abaixo.
Create table Alunos (pk int not null primary key, nomea varchar(100), idade int, nascimento date not null);
Assinale qual, dentre as instruções ALTER TABLE listadas abaixo, representa um comando SQL INVÁLIDO, que causa um erro de execução.
Create table Alunos (pk int not null primary key, nomea varchar(100), idade int, nascimento date not null);
Assinale qual, dentre as instruções ALTER TABLE listadas abaixo, representa um comando SQL INVÁLIDO, que causa um erro de execução.
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107765
Banco de Dados
Imagine que em um banco de dados ORACLE existe um usuário USUARIO1 e uma
tabela de nome PROJETOS. Considere que o DBA emitiu o seguinte comando SQL nesse banco de
dados:
GRANT ALL PRIVILEGES ON PROJETOS TO USUARIO1;
Analise as assertivas abaixo, sobre os privilégios concedidos a USUARIO1 com esse comando, assinalando V, se verdadeiras, ou F, se falsas.
( ) USUARIO1 pode remover tuplas da tabela PROJETOS. ( ) USUARIO1 pode conceder a outros usuários um ou mais privilégios recebidos sobre a tabela PROJETOS através de comandos GRANT. ( ) USUARIO1 pode definir um gatilho sobre a tabela PROJETOS.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
GRANT ALL PRIVILEGES ON PROJETOS TO USUARIO1;
Analise as assertivas abaixo, sobre os privilégios concedidos a USUARIO1 com esse comando, assinalando V, se verdadeiras, ou F, se falsas.
( ) USUARIO1 pode remover tuplas da tabela PROJETOS. ( ) USUARIO1 pode conceder a outros usuários um ou mais privilégios recebidos sobre a tabela PROJETOS através de comandos GRANT. ( ) USUARIO1 pode definir um gatilho sobre a tabela PROJETOS.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107767
Banco de Dados
Considere a tabela PILOTOS e a visão PILOTOSA320 definidas pelos comandos SQL
abaixo (padrão SQL99 ou superior).

Considere os comandos SQL abaixo no mesmo padrão, em que cada comando corresponde a uma transação. Assinale com V, se o comando executa corretamente, ou com F, se o comando resulta em erro.
( ) insert into PILOTOSA320(codp, nomep, companhia, aviao) values (1, 'jose', 'gol', 'A320'); ( ) insert into PILOTOSA320(codp, nomep, companhia, aviao) values (2, 'maria', 'tam', '777'); ( ) insert into PILOTOSA320(codp, nomep, aviao) values (2, 'jose', 'A320');
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Considere os comandos SQL abaixo no mesmo padrão, em que cada comando corresponde a uma transação. Assinale com V, se o comando executa corretamente, ou com F, se o comando resulta em erro.
( ) insert into PILOTOSA320(codp, nomep, companhia, aviao) values (1, 'jose', 'gol', 'A320'); ( ) insert into PILOTOSA320(codp, nomep, companhia, aviao) values (2, 'maria', 'tam', '777'); ( ) insert into PILOTOSA320(codp, nomep, aviao) values (2, 'jose', 'A320');
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107768
Banco de Dados
Considere as tabelas criadas com os comandos SQL abaixo, e os comandos de
inserção de tuplas SQL (padrão SQL99 ou superior).
Create table A (pka int primary key, a1 integer); Create table B (pkb int primary key, b1 integer); Create table C (pkc int primary key, c1 integer); insert into A values (1,10); insert into A values (2, 10); insert into A values (3, 2); insert into A values (4, 3); insert into B values (10,0); insert into C values (100,0);
Suponha a criação dos gatilhos T1 e T2 definidos abaixo cujas cláusulas estão de acordo com padrão, e cujo código disparado foi escrito conforme sintaxe PL/SQL (Oracle).

Considere que os três comandos SQL de remoção de tuplas abaixo foram executados sem erro:
I. delete from A where a1>=10; II. delete from A where a1<10; III. delete from A where a1 is null;
Finalmente, foram executadas as duas consultas SQL abaixo, cada qual retornando uma única tupla:
(1) SELECT b1 FROM B; (2) SELECT c1 FROM C;
Selecione a alternativa que representa, nesta ordem, o valor do atributo b1 resultante da consulta (1), e o valor do atributo c1 resultante da consulta (2).
Create table A (pka int primary key, a1 integer); Create table B (pkb int primary key, b1 integer); Create table C (pkc int primary key, c1 integer); insert into A values (1,10); insert into A values (2, 10); insert into A values (3, 2); insert into A values (4, 3); insert into B values (10,0); insert into C values (100,0);
Suponha a criação dos gatilhos T1 e T2 definidos abaixo cujas cláusulas estão de acordo com padrão, e cujo código disparado foi escrito conforme sintaxe PL/SQL (Oracle).
Considere que os três comandos SQL de remoção de tuplas abaixo foram executados sem erro:
I. delete from A where a1>=10; II. delete from A where a1<10; III. delete from A where a1 is null;
Finalmente, foram executadas as duas consultas SQL abaixo, cada qual retornando uma única tupla:
(1) SELECT b1 FROM B; (2) SELECT c1 FROM C;
Selecione a alternativa que representa, nesta ordem, o valor do atributo b1 resultante da consulta (1), e o valor do atributo c1 resultante da consulta (2).
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107769
Banco de Dados
O DBA de um banco de dados SQL Server 2019 precisou procurar no catálogo algumas
definições existentes sobre um esquema da base de dados específico para executar o seu trabalho.
Ele descobriu que:
• Para procurar as tabelas existentes, deveria consultar a SYS.TABLES, e para encontrar as chaves primárias existentes, poderia consultar a tabela _____________; • Encontraria na tabela _________ o identificador do tipo de dado associado aos atributos de uma dada tabela; • Para encontrar os procedimentos armazenados na base de dados, precisava consultar a SYS.PROCEDURES, e que se quisesse saber detalhes dos parâmetros de um dado procedimento armazenado, poderia encontrá-los na ___________;
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
• Para procurar as tabelas existentes, deveria consultar a SYS.TABLES, e para encontrar as chaves primárias existentes, poderia consultar a tabela _____________; • Encontraria na tabela _________ o identificador do tipo de dado associado aos atributos de uma dada tabela; • Para encontrar os procedimentos armazenados na base de dados, precisava consultar a SYS.PROCEDURES, e que se quisesse saber detalhes dos parâmetros de um dado procedimento armazenado, poderia encontrá-los na ___________;
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107770
Banco de Dados
Considere que o DBA de um banco de dados SQL Server 2019 definiu o índice abaixo
sobre a tabela TAB1:
CREATE NONCLUSTERED INDEX IDX1 ON TAB1 (codcomp, dataInicial) WHERE DataFinal IS NOT NULL;
Sobre isso, analise as assertivas abaixo:
I. Esse comando cria um índice filtrado. II. O índice criado por esse comando contribui à melhoria do desempenho de consultas principalmente quando a condição (DataFinal IS NOT NULL) é observada em um grande número de tuplas dessa tabela. III. O formato de armazenamento primário do índice criado por esse comando é columnstore.
Quais estão corretas?
CREATE NONCLUSTERED INDEX IDX1 ON TAB1 (codcomp, dataInicial) WHERE DataFinal IS NOT NULL;
Sobre isso, analise as assertivas abaixo:
I. Esse comando cria um índice filtrado. II. O índice criado por esse comando contribui à melhoria do desempenho de consultas principalmente quando a condição (DataFinal IS NOT NULL) é observada em um grande número de tuplas dessa tabela. III. O formato de armazenamento primário do índice criado por esse comando é columnstore.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107771
Banco de Dados
Analise as assertivas abaixo sobre benefícios de procedimentos armazenados (stored
procedures) em bancos de dados relacionais:
I. Melhor manutenabilidade: é possível alterar o código de um procedimento armazenado diretamente, sem que as diferentes aplicações que o usam sejam impactadas. II. Maior segurança: é possível conceder a procedimentos armazenados os privilégios de acesso necessários ao acesso/atualização dos objetos que manipula. Se usuários forem forçados a atualizar certos objetos da base de dados através de procedimentos armazenados específicos, é possível limitar a concessão de privilégios a usuários para acesso/manipulação desses objetos. III. Melhor desempenho: um procedimento armazenado pode executar com melhor desempenho no servidor, pode se beneficiar de otimizações específicas feitas pelo sistema de gerência de banco de dados, pode implicar em redução de tráfego entre o servidor e a aplicação cliente, entre outras razões.
Quais estão corretas?
I. Melhor manutenabilidade: é possível alterar o código de um procedimento armazenado diretamente, sem que as diferentes aplicações que o usam sejam impactadas. II. Maior segurança: é possível conceder a procedimentos armazenados os privilégios de acesso necessários ao acesso/atualização dos objetos que manipula. Se usuários forem forçados a atualizar certos objetos da base de dados através de procedimentos armazenados específicos, é possível limitar a concessão de privilégios a usuários para acesso/manipulação desses objetos. III. Melhor desempenho: um procedimento armazenado pode executar com melhor desempenho no servidor, pode se beneficiar de otimizações específicas feitas pelo sistema de gerência de banco de dados, pode implicar em redução de tráfego entre o servidor e a aplicação cliente, entre outras razões.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107772
Banco de Dados
No Oracle, cada instância de um banco de dados tem um redo log associado para
proteger o banco de dados em caso de falha da instância. Um redo log consiste em um ou mais
arquivos pré-alocados que armazenam todas as alterações feitas no banco de dados à medida que
ocorrem. O Log Writer (LGWR) é o processo que controla a escrita das mudanças nos arquivos de
redo log. Analise as seguintes assertivas sobre o redo log no Oracle:
I. O recurso de multiplexar um redo log (multiplexed redo logs) visa proteger contra uma falha envolvendo o próprio redo log. II. Quando um redo log é multiplexado, é recomendado que todos os membros de um grupo sejam colocados em discos físicos distintos. III. É uma boa prática que a necessidade de arquivamento dos arquivos de redo log em mídias de armazenamento off-line, tais como discos ou fitas, seja levada em conta pelo DBA ao definir o tamanho do arquivo de redo log.
Quais estão corretas?
I. O recurso de multiplexar um redo log (multiplexed redo logs) visa proteger contra uma falha envolvendo o próprio redo log. II. Quando um redo log é multiplexado, é recomendado que todos os membros de um grupo sejam colocados em discos físicos distintos. III. É uma boa prática que a necessidade de arquivamento dos arquivos de redo log em mídias de armazenamento off-line, tais como discos ou fitas, seja levada em conta pelo DBA ao definir o tamanho do arquivo de redo log.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107773
Banco de Dados
O Oracle Data Guard fornece um conjunto abrangente de serviços que criam,
mantêm, gerenciam e monitoram um ou mais bancos de dados em espera (standby). Analise as
seguintes assertivas sobre serviços providos pelo Oracle Data Guard, assinalando V, se verdadeiras,
ou F, se falsas.
( ) Existem quatro tipos de bancos de dados standby: físico, lógico, snapshot e cloud. ( ) Uma transição do banco de dados primário para uma base de dados standby pode ocorrer tanto para gerenciar casos de falha (failover), tais como desastres e corrupção de dados, quanto situações que não envolvem falhas (switchover), como, por exemplo, manutenções programadas. ( ) Oferece três modos de proteção: disponibilidade máxima, desempenho máximo e proteção máxima.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
( ) Existem quatro tipos de bancos de dados standby: físico, lógico, snapshot e cloud. ( ) Uma transição do banco de dados primário para uma base de dados standby pode ocorrer tanto para gerenciar casos de falha (failover), tais como desastres e corrupção de dados, quanto situações que não envolvem falhas (switchover), como, por exemplo, manutenções programadas. ( ) Oferece três modos de proteção: disponibilidade máxima, desempenho máximo e proteção máxima.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107774
Banco de Dados
Considere as seguintes assertivas sobre recursos de backup no SQL Server 2019,
assinalando V, se verdadeiras, ou F, se falsas.
( ) Oferece diferentes modelos de recuperação, entre eles o total, diferencial e log de transações. ( ) Um backup diferencial captura apenas as extensões dos dados alterados desde o último backup diferencial. ( ) Se a base de dados foi criada com múltiplos arquivos de dados, é possível criar backups de arquivos individuais e restaurá-los individualmente.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
( ) Oferece diferentes modelos de recuperação, entre eles o total, diferencial e log de transações. ( ) Um backup diferencial captura apenas as extensões dos dados alterados desde o último backup diferencial. ( ) Se a base de dados foi criada com múltiplos arquivos de dados, é possível criar backups de arquivos individuais e restaurá-los individualmente.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107776
Banco de Dados
Considere as tabelas ESPECIALIDADES e MEDICOS abaixo, bem como a sequência
de criação de instâncias (padrão SQL99 ou superior).

insert into ESPECIALIDADES values (1,'cardiologia'); insert into ESPECIALIDADES values (2,'oftalmologia'); insert into ESPECIALIDADES values (3,'pediatria'); insert into MEDICOS values (1, 'joao', 1, 'ufrgs'); insert into MEDICOS values (2, 'maria', 1, 'pucrs'); insert into MEDICOS values (3, 'pedro', 2, 'ufsm');
Considere a sequência de comandos SQL abaixo, em que cada comando deve ser considerado uma transação separada:
I. delete from ESPECIALIDADES where nomee = 'pediatria'; II. update ESPECIALIDADES set code = 4 where nomee = 'oftalmologia'; III. delete from ESPECIALIDADES where nomee = 'cardiologia';
Após a execução das transações I, II e III, é possível afirmar que:
• A tabela ESPECIALIDADES tem __________ tupla(s); • Na tabela MEDICOS, no registro em que MEDICOS.codm = 1, o valor do atributo MEDICOS.code é _________; • Na tabela MEDICOS, no registro em que MEDICOS.codm = 3, o valor do atributo MEDICOS.code é _________.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
insert into ESPECIALIDADES values (1,'cardiologia'); insert into ESPECIALIDADES values (2,'oftalmologia'); insert into ESPECIALIDADES values (3,'pediatria'); insert into MEDICOS values (1, 'joao', 1, 'ufrgs'); insert into MEDICOS values (2, 'maria', 1, 'pucrs'); insert into MEDICOS values (3, 'pedro', 2, 'ufsm');
Considere a sequência de comandos SQL abaixo, em que cada comando deve ser considerado uma transação separada:
I. delete from ESPECIALIDADES where nomee = 'pediatria'; II. update ESPECIALIDADES set code = 4 where nomee = 'oftalmologia'; III. delete from ESPECIALIDADES where nomee = 'cardiologia';
Após a execução das transações I, II e III, é possível afirmar que:
• A tabela ESPECIALIDADES tem __________ tupla(s); • Na tabela MEDICOS, no registro em que MEDICOS.codm = 1, o valor do atributo MEDICOS.code é _________; • Na tabela MEDICOS, no registro em que MEDICOS.codm = 3, o valor do atributo MEDICOS.code é _________.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107777
Banco de Dados
Considere o modelo de dados Entidade-Relacionamento (ER) e as situações descritas
nos itens abaixo. Para cada situação, são fornecidos o nome de um relacionamento e de três entidades
(identificados em letras maiúsculas), junto com a descrição de uma situação a ser modelada. Assuma
sempre que as entidades indicadas são necessárias considerando o propósito da base de dados.
I. Relacionamento MENTORIA, entidades ESTAGIARIO, MENTOR, e SETOR: em um programa de treinamento, um estagiário passa por vários setores da empresa, em cada um deles sendo atribuído a um mentor. Deseja-se registrar sobre cada mentoria, além do estagiário, do mentor, e do setor, a data de início e de fim da mentoria. II. Relacionamento CONSULTA, entidades MEDICO, PACIENTE, e EXAME: uma clínica médica oferece consultas e exames a seus pacientes. Deseja-se registrar sobre cada consulta realizada, além do médico e do paciente, a data/hora da consulta, a forma de pagamento, bem como possivelmente um ou mais exames solicitados durante a consulta. III. Relacionamento ALOCACAO, entidades PROJETO, FUNCIONARIO, e FUNCAO: uma empresa de TI desenvolve diferentes projetos, na qual aloca seus funcionários em uma dada função. Deseja-se registrar sobre cada alocação, além do funcionário, do projeto e da função, o número de horas alocado.
Qual dos relacionamentos acima poderia ser corretamente modelado por um relacionamento ternário entre as três entidades participantes indicadas?
I. Relacionamento MENTORIA, entidades ESTAGIARIO, MENTOR, e SETOR: em um programa de treinamento, um estagiário passa por vários setores da empresa, em cada um deles sendo atribuído a um mentor. Deseja-se registrar sobre cada mentoria, além do estagiário, do mentor, e do setor, a data de início e de fim da mentoria. II. Relacionamento CONSULTA, entidades MEDICO, PACIENTE, e EXAME: uma clínica médica oferece consultas e exames a seus pacientes. Deseja-se registrar sobre cada consulta realizada, além do médico e do paciente, a data/hora da consulta, a forma de pagamento, bem como possivelmente um ou mais exames solicitados durante a consulta. III. Relacionamento ALOCACAO, entidades PROJETO, FUNCIONARIO, e FUNCAO: uma empresa de TI desenvolve diferentes projetos, na qual aloca seus funcionários em uma dada função. Deseja-se registrar sobre cada alocação, além do funcionário, do projeto e da função, o número de horas alocado.
Qual dos relacionamentos acima poderia ser corretamente modelado por um relacionamento ternário entre as três entidades participantes indicadas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107778
Banco de Dados
Qual das propriedades abaixo NÃO constitui uma característica que distingue a
abordagem de banco de dados relacional de uma abordagem tradicional de processamento de
arquivos?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107780
Banco de Dados
Uma empresa de logística, que possui carros e bombas de combustível, deseja
controlar o abastecimento de sua frota. Ela deseja poder gerenciar cada abastecimento realizado em
um de seus veículos. O analista identificou os dados importantes, apresentados abaixo na forma de
nome de atributo e sua semântica. Projetou então uma tabela ABASTECIMENTO, descrita abaixo em
SQL padrão, que apresentou ao DBA.

Create table ABASTECIMENTO (nbomb int not null, capac int not null, data_hora timestamp not null, placa char(7) not null, descr varchar(50) not null, ano_fab date not null, litros int not null, primary key (nbomb, data_hora));
A DBA analisou essa proposta e observou que não seguia as formas normais. Com base na descrição dos atributos acima, assinale com V, se a dependência funcional é responsável pelo fato da tabela não estar na terceira forma normal, ou com F, em caso contrário.
( ) nbomb, data-hora → capac ( ) nbomb, data-hora → placa ( ) nbomb, data-hora → ano-fab
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Create table ABASTECIMENTO (nbomb int not null, capac int not null, data_hora timestamp not null, placa char(7) not null, descr varchar(50) not null, ano_fab date not null, litros int not null, primary key (nbomb, data_hora));
A DBA analisou essa proposta e observou que não seguia as formas normais. Com base na descrição dos atributos acima, assinale com V, se a dependência funcional é responsável pelo fato da tabela não estar na terceira forma normal, ou com F, em caso contrário.
( ) nbomb, data-hora → capac ( ) nbomb, data-hora → placa ( ) nbomb, data-hora → ano-fab
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107781
Banco de Dados
Um histórico (schedule) S de n transações ordena uma sequência de operações sobre
objetos do banco de dados, entre elas, de leitura (r) ou gravação (w). Dado um histórico parcial Si:
rj(A), wk(A), pode-se dizer que ele ordena duas operações, onde rj(A) representa operação de leitura
sobre o objeto A na transação Tj, seguida da operação wk(A) representando uma operação de escrita
sobre o objeto A na transação Tk. Considere um banco de dados com objetos X e Y, duas transações
T1 e T2, e os históricos parciais S1, S2, e S3 descritos abaixo.
S1: r2(X), r1(X), r2(Y), r1(X), r2(Y), w2(Y) ... S2: r2(X), r2(Y), r1(X), r1(Y), w1(X) ... S3: r2(Y), r2(Y), r1(X), r1(Y), w1(X), w2(X) ...
Quais históricos apresentam operações conflitantes?
S1: r2(X), r1(X), r2(Y), r1(X), r2(Y), w2(Y) ... S2: r2(X), r2(Y), r1(X), r1(Y), w1(X) ... S3: r2(Y), r2(Y), r1(X), r1(Y), w1(X), w2(X) ...
Quais históricos apresentam operações conflitantes?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107782
Banco de Dados
O desaninhamento de subconsulta é uma otimização disponível no Oracle que
converte uma subconsulta em uma junção na consulta externa, permitindo que o otimizador considere
a(s) tabela(s) de subconsulta durante o caminho de acesso, método de junção e seleção de ordem de
junção. As consultas (a) e (b) exemplificam respectivamente uma subconsulta ALL e uma subconsulta
EXISTS. Os atributos dessas tabelas usadas podem ser inferidos a partir dessas consultas SQL:
(a) SELECT C.sobrenome, C.renda FROM clientes C WHERE C.codc <> ALL (SELECT V.codc FROM vendas V WHERE V.valor > 1000);
(b) SELECT C.sobrenome, C.renda FROM clientes C WHERE NOT EXISTS (SELECT 1 FROM vendas V WHERE V.valor > 1000 and V.codc = C.codc);
Considere as assertivas abaixo sobre a otimização baseada em desaninhamento de subconsultas no Oracle:
I. O recurso fundamental do desaninhamento de subconsultas é a conversão da subconsulta com processamento relacionado em outra equivalente com processamento não relacionado. II. No caso de uma subconsulta ALL, o desaninhamento explora semi-join. III. No caso de uma subconsulta NOT EXISTS, o desaninhamento explora o anti-join.
Quais estão corretas?
(a) SELECT C.sobrenome, C.renda FROM clientes C WHERE C.codc <> ALL (SELECT V.codc FROM vendas V WHERE V.valor > 1000);
(b) SELECT C.sobrenome, C.renda FROM clientes C WHERE NOT EXISTS (SELECT 1 FROM vendas V WHERE V.valor > 1000 and V.codc = C.codc);
Considere as assertivas abaixo sobre a otimização baseada em desaninhamento de subconsultas no Oracle:
I. O recurso fundamental do desaninhamento de subconsultas é a conversão da subconsulta com processamento relacionado em outra equivalente com processamento não relacionado. II. No caso de uma subconsulta ALL, o desaninhamento explora semi-join. III. No caso de uma subconsulta NOT EXISTS, o desaninhamento explora o anti-join.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107783
Banco de Dados
Considere as seguintes assertivas sobre o protocolo de bloqueio em duas fases (2PL
- Two Phase Lock) em sistemas de gerência de banco de dados:
I. 2PL garante possibilidade de serialização (serializability). II. 2PL evita deadlocks. III. 2PL não permite intercalação de lock e unlock.
Quais estão corretas?
I. 2PL garante possibilidade de serialização (serializability). II. 2PL evita deadlocks. III. 2PL não permite intercalação de lock e unlock.
Quais estão corretas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107784
Banco de Dados
Considere que uma empresa deseja controlar os pedidos que clientes fazem de seus
produtos. Clientes são identificados por um CPF único, produtos por um código único (codpro) e
pedidos por um número único (nro). Existem produtos que não fazem parte de pedidos, e clientes que
não fizeram pedidos. Ao registrar um pedido de um cliente, no qual podem ser incluídos um ou mais
produtos, deve ser possível gerar o recibo exemplificado abaixo.
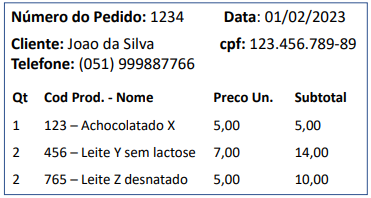
Foi solicitado a um estagiário fazer um projeto conceitual utilizando o modelo EntidadeRelacionamento (ER). Recebeu como recomendação que o projeto deveria conter os dados necessários para gerar este recibo, considerar o emprego correto do modelo de dados ER, e evitar redundâncias de dados que possam levar a problemas de integridade na base de dados.
Utilizando a notação gráfica proposta por Heuser (2009), baseada na proposta por Peter Chen com as extensões mais populares, o estagiário desenhou vários diagramas ER (DER). As caixas representam as entidades, os losangos os relacionamentos, as cardinalidades dos relacionamentos são representadas por pares (min-max), e os “pirulitos” representam os atributos. Quando pintado de preto, um “pirulito” representa uma restrição de identificação.
Qual DER melhor atende às recomendações recebidas?
Foi solicitado a um estagiário fazer um projeto conceitual utilizando o modelo EntidadeRelacionamento (ER). Recebeu como recomendação que o projeto deveria conter os dados necessários para gerar este recibo, considerar o emprego correto do modelo de dados ER, e evitar redundâncias de dados que possam levar a problemas de integridade na base de dados.
Utilizando a notação gráfica proposta por Heuser (2009), baseada na proposta por Peter Chen com as extensões mais populares, o estagiário desenhou vários diagramas ER (DER). As caixas representam as entidades, os losangos os relacionamentos, as cardinalidades dos relacionamentos são representadas por pares (min-max), e os “pirulitos” representam os atributos. Quando pintado de preto, um “pirulito” representa uma restrição de identificação.
Qual DER melhor atende às recomendações recebidas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2023 - BRDE - Analista de Sistemas - Administração de Banco de Dados |
Q2107785
Banco de Dados
Considere o diagrama Entidade-Relacionamento abaixo, desenhado de acordo com a
notação proposta em Heuser (2009), baseada na proposta por Peter Chen com as extensões mais
populares. As caixas representam as entidades, os losangos os relacionamentos, as cardinalidades
dos relacionamentos são representadas por pares (min-max), e os “pirulitos” representam os
atributos. Quando pintado de preto, um “pirulito” representa uma restrição de identificação.
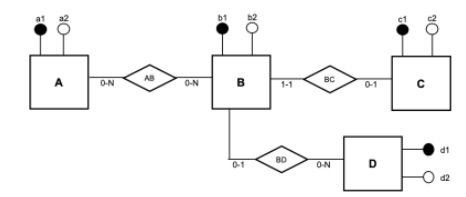
Foi solicitado à projetista que fizesse um modelo lógico relacional correspondente a este DER. A projetista mapeou as entidades A, B, C e D nas tabelas A, B, C e D, respectivamente, cada qual com sua chave primária (atributos a1, b1, c1 e d1, respectivamente) e demais atributos (a2, b2, c2 e d2, respectivamente).
Considere as seguintes assertivas sobre o mapeamento dos relacionamentos:
I. Deve ser criada uma tabela própria para representar o relacionamento AB, na qual deve haver colunas (chaves estrangeiras) referenciando as chaves primárias das tabelas A e B. II. O relacionamento BD pode ser modelado como uma coluna adicional na tabela B (chave estrangeira referenciando a chave primária da tabela D). III. O relacionamento BC pode ser modelado como uma coluna adicional (chave estrangeira) na tabela C ou B, sendo essas escolhas equivalentes. Se incluído na tabela C, esse atributo deve referenciar a chave primária da tabela B, e se incluído na tabela B, deve referenciar a chave primária da tabela C.
Quais estão corretas?
Foi solicitado à projetista que fizesse um modelo lógico relacional correspondente a este DER. A projetista mapeou as entidades A, B, C e D nas tabelas A, B, C e D, respectivamente, cada qual com sua chave primária (atributos a1, b1, c1 e d1, respectivamente) e demais atributos (a2, b2, c2 e d2, respectivamente).
Considere as seguintes assertivas sobre o mapeamento dos relacionamentos:
I. Deve ser criada uma tabela própria para representar o relacionamento AB, na qual deve haver colunas (chaves estrangeiras) referenciando as chaves primárias das tabelas A e B. II. O relacionamento BD pode ser modelado como uma coluna adicional na tabela B (chave estrangeira referenciando a chave primária da tabela D). III. O relacionamento BC pode ser modelado como uma coluna adicional (chave estrangeira) na tabela C ou B, sendo essas escolhas equivalentes. Se incluído na tabela C, esse atributo deve referenciar a chave primária da tabela B, e se incluído na tabela B, deve referenciar a chave primária da tabela C.
Quais estão corretas?