Questões de Concurso Público EMGEPRON 2021 para Analista de Sistemas (Auditoria)
Foram encontradas 17 questões
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771424
Banco de Dados
A arquitetura OLAP representa um método que
garante que os dados corporativos sejam analisados
de forma mais ágil, consistente e interativa pelos
gerentes, analistas, executivos e outros interessados
nas informações. Constitui uma interface com o
usuário e não uma forma de armazenamento de
dados, porém se utiliza do armazenamento para
poder apresentar as informações. Entre os métodos
de armazenamento, quatro são descritos a seguir.
I. Os dados são armazenados de forma relacional. II. Os dados são armazenados de forma multidimensional. III. Uma combinação dos métodos caracterizados em I e em II. IV. O conjunto de dados multidimensionais deve ser criado no servidor e transferido para o desktop, além de permitir portabilidade aos usuários OLAP que não possuem acesso direto ao servidor.
O métodos descritos em I, II, III e IV são conhecidos, respectivamente, pelas siglas:
I. Os dados são armazenados de forma relacional. II. Os dados são armazenados de forma multidimensional. III. Uma combinação dos métodos caracterizados em I e em II. IV. O conjunto de dados multidimensionais deve ser criado no servidor e transferido para o desktop, além de permitir portabilidade aos usuários OLAP que não possuem acesso direto ao servidor.
O métodos descritos em I, II, III e IV são conhecidos, respectivamente, pelas siglas:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771427
Banco de Dados
No que diz respeito aos tipos de dados
suportados pelo banco de dados Oracle, para
armazenar caracteres de tamanho variável e
números inteiros, as variáveis devem ser declaradas,
respectivamente, dos seguintes tipos:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771432
Banco de Dados
A normalização do banco de dados é o processo
de transformações na estrutura de um banco de
dados que visa eliminar redundâncias e anomalias de
inserção, atualização e exclusão. Tal procedimento é
feito a partir da identificação de uma anomalia em
uma relação, decompondo-a em relações melhor
estruturadas. Este processo compreende o uso de
um conjunto de regras, chamadas de formas normais.
Existem diversas FORMAS NORMAIS, com
requisitos específicos, conforme caracterizado a
seguir.
I. Uma relação está na forma normal X quando não existir dependências multivaloradas entre seus atributos, ou seja, campos que se repetem em relação à chave primária, gerando redundância nas tuplas da entidade. II. Uma relação está na forma normal Y quando todos os atributos contêm apenas um valor correspondente, singular, e não existem grupos de atributos repetidos, ou seja, não admite repetições ou campos que tenham mais que um valor. III. Uma relação está na forma normal W quando, na análise de uma tupla, não se encontra um atributo não chave dependente de outro atributo não chave. IV. Uma relação está na forma normal Z quando todos os registros na tabela, que não são chaves, dependem da chave primária em sua totalidade e não apenas parte dela.
Nessas condições, os indicadores X, Y, W e Z referem-se, respectivamente, às formas normais:
I. Uma relação está na forma normal X quando não existir dependências multivaloradas entre seus atributos, ou seja, campos que se repetem em relação à chave primária, gerando redundância nas tuplas da entidade. II. Uma relação está na forma normal Y quando todos os atributos contêm apenas um valor correspondente, singular, e não existem grupos de atributos repetidos, ou seja, não admite repetições ou campos que tenham mais que um valor. III. Uma relação está na forma normal W quando, na análise de uma tupla, não se encontra um atributo não chave dependente de outro atributo não chave. IV. Uma relação está na forma normal Z quando todos os registros na tabela, que não são chaves, dependem da chave primária em sua totalidade e não apenas parte dela.
Nessas condições, os indicadores X, Y, W e Z referem-se, respectivamente, às formas normais:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771433
Banco de Dados
No que tange à abstração de dados, um sistema
de BD deve garantir uma visão totalmente abstrata do
banco de dados para o usuário, ou seja, para esse
usuário pouco importa qual unidade de
armazenamento está sendo usada para guardar seus
dados, desde que estes estejam disponíveis no
momento necessário.
A figura abaixo tem por foco a abstração do BD em
três níveis.
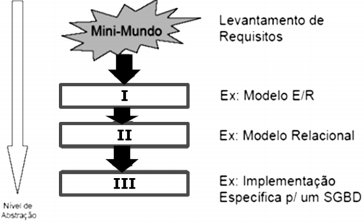
De acordo com a figura, destacam-se três níveis:
I. Este nível é o de mais alto nível de abstração, correspondendo a um modelo que independe da implementação em um SGBD. No contexto do projeto de BD, emprega uma técnica de modelagem baseada na representação por meio do diagrama entidade-relacionamento. II. Este nível refere-se a uma descrição do BD, correspondendo a um modelo que considera a abstração na visão do usuário do SGBD. Pode-se concluir que o projeto depende do SGBD em uso, além de definir como será a implementação em um SGBD específico. III. Este nível é o nível mais baixo de abstração, correspondendo a um modelo que descreve como os dados estão realmente armazenados. Pode-se concluir que engloba estruturas complexas de baixo nível e descreve os detalhes completos do armazenamento de dados e o caminho de acesso ao banco de dados.
Nessas condições, os níveis I, II e III são denominados, respectivamente:
De acordo com a figura, destacam-se três níveis:
I. Este nível é o de mais alto nível de abstração, correspondendo a um modelo que independe da implementação em um SGBD. No contexto do projeto de BD, emprega uma técnica de modelagem baseada na representação por meio do diagrama entidade-relacionamento. II. Este nível refere-se a uma descrição do BD, correspondendo a um modelo que considera a abstração na visão do usuário do SGBD. Pode-se concluir que o projeto depende do SGBD em uso, além de definir como será a implementação em um SGBD específico. III. Este nível é o nível mais baixo de abstração, correspondendo a um modelo que descreve como os dados estão realmente armazenados. Pode-se concluir que engloba estruturas complexas de baixo nível e descreve os detalhes completos do armazenamento de dados e o caminho de acesso ao banco de dados.
Nessas condições, os níveis I, II e III são denominados, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771434
Banco de Dados
No que tange aos projetos lógico e físico de BD,
a modelagem assume papel de extrema importância.
Entre as ferramentas disponíveis, o Modelo Entidade
Relacionamento (MER) é um modelo utilizado na
Engenharia de Software para descrever as entidades
envolvidas em um domínio de negócios, com seus
atributos e os relacionamentos. Esse modelo
representa de forma abstrata a estrutura que possuirá
o banco de dados da aplicação, sendo o Diagrama
Entidade-Relacionamento (DER) a representação
gráfica do MER. Na elaboração de um DER, de
acordo com a notação Peter Chen para representar
entidades, atributos, relacionamentos e
especialização, respectivamente, foram
padronizados os seguintes símbolos:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771435
Banco de Dados
A sigla SGBD tem por significado Sistema de
Gerenciamento de Banco de Dados, definido como o
conjunto de programas para gerenciamento de uma
base de dados, tendo como principal objetivo retirar
da aplicação cliente a responsabilidade de gerenciar
o acesso, a manipulação e a organização dos dados.
Qualquer banco de dados que seja utilizado por mais
de um usuário terá que realizar um controle de acesso
entre as informações que estão sendo acessadas
pelos usuários. Neste contexto, os SGBD
implementam um recurso no qual usuários distintos
tentam acessar a mesma informação e então é feito
um controle entre essas transações. E, para a
solução deste problema, existem diversas técnicas
que são utilizadas como forma de assegurar a
propriedade de não interferência entre uma operação
e outra, ou o isolamento das transações executadas
ao mesmo tempo. Grande parte dessas técnicas
garante a serialização, que é a execução das
transações de forma serial. Para isso, é necessário
saber que transações são todas as operações
executadas entre o início e o fim da transação. Esse
recurso é conhecido por Controle de:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771436
Banco de Dados
A segurança de um banco de dados herda as
mesmas dificuldades que a segurança da informação
enfrenta, que é garantir a integridade, a
disponibilidade e a confidencialidade. Um SGBD
deve fornecer mecanismos que auxiliem nesta tarefa,
sendo três deles descritos a seguir.
I. É todo controle feito por meio de regras de restrição, implementadas nas contas dos usuários. O DBA é o responsável por declarar as regras dentro do SGBD, sendo o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuir um nível de segurança aos usuários do sistema, de acordo com a política da empresa. II. É um mecanismo para BD estatísticos, que atua protegendo informações estatísticas de um indivíduo ou de um grupo. Estes tipos de BD são usados principalmente para produzir estatísticas sobre populações, podendo conter informações confidenciais. Os usuários têm permissão apenas para recuperar informações estatísticas sobre populações e não para recuperar dados individuais, como, por exemplo, a renda de uma pessoa específica. III. É um mecanismo que previne que as informações fluam por canais secretos e violem a política de segurança ao alcançarem usuários não autorizados. Ele regula tráfego de dados entre um objeto ALFA para outro BETA, que ocorre quando um programa lê valores de ALFA e escreve valores em BETA.
Os três mecanismos descritos em I, II e III são denominados, respectivamente, controle de:
I. É todo controle feito por meio de regras de restrição, implementadas nas contas dos usuários. O DBA é o responsável por declarar as regras dentro do SGBD, sendo o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuir um nível de segurança aos usuários do sistema, de acordo com a política da empresa. II. É um mecanismo para BD estatísticos, que atua protegendo informações estatísticas de um indivíduo ou de um grupo. Estes tipos de BD são usados principalmente para produzir estatísticas sobre populações, podendo conter informações confidenciais. Os usuários têm permissão apenas para recuperar informações estatísticas sobre populações e não para recuperar dados individuais, como, por exemplo, a renda de uma pessoa específica. III. É um mecanismo que previne que as informações fluam por canais secretos e violem a política de segurança ao alcançarem usuários não autorizados. Ele regula tráfego de dados entre um objeto ALFA para outro BETA, que ocorre quando um programa lê valores de ALFA e escreve valores em BETA.
Os três mecanismos descritos em I, II e III são denominados, respectivamente, controle de:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771437
Banco de Dados
No desenvolvimento de um Banco de Dados, é
realizada, no Projeto Lógico, a seguinte atividade:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771438
Banco de Dados
No contexto de bancos de dados, um tipo de
restrição de integridade assegura que valores de uma
coluna em uma tabela são válidos baseados nos
valores em uma outra tabela relacionada. Por
exemplo, se um produto de COD $75DF foi
cadastrado em uma tabela de Vendas, então um
produto com COD $75DF deve existir na tabela de
produtos relacionada. Resumindo, cada valor de uma
chave estrangeira deve corresponder a um valor de
uma chave primária existente, servindo para manter a
consistência entre tuplas de duas relações, existindo
em consequência dos relacionamentos entre
entidades.
O tipo de restrição é denominado integridade:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771439
Banco de Dados
A tabela abaixo, faz parte de um banco de dados
relacional PostgreSQL.
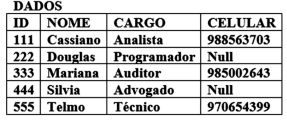
Para obter o nome e cargo de todos os funcionários, ordenando o resultado por celular em ordem alfabética de nome das pessoas que tenham celulares cadastrados, a sintaxe correta para o comando SQL a ser executado é:
Para obter o nome e cargo de todos os funcionários, ordenando o resultado por celular em ordem alfabética de nome das pessoas que tenham celulares cadastrados, a sintaxe correta para o comando SQL a ser executado é:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771440
Banco de Dados
No contexto dos bancos de dados relacionais
SQL, muitas vezes surge a necessidade de se
realizar uma determinada ação, de acordo com algum
evento que acontecer e é isso que o Trigger viabiliza.
No que diz respeito à sintaxe para criação de um
trigger, observam-se os parâmetros descritos a
seguir.
I. NOME DO TRIGGER – identifica o nome da trigger como objeto do banco de dados, devendo seguir as regras básicas de nomenclatura de objetos. II. NOME DA TABELA – identifica o nome da tabela à qual o trigger estará ligado, para ser disparado mediante ações de insert, update ou delete. III. Opção X/Y/Z – escolhida para definir o momento em que o trigger será disparado, onde X representa o valor padrão e faz com o que o gatilho seja disparado junto da ação, Y faz com que o disparo se dê somente após a ação que o gerou ser concluída, e Z faz com que o trigger seja executado no lugar da ação que o gerou. IV. Opção M/N/P – escolhida entre as instruções DML para indicar e informar ao banco qual ação irá disparar o gatilho.
Os parâmetros que devem substituir X/Y/Z em III e M/N/P em IV são, respectivamente:
I. NOME DO TRIGGER – identifica o nome da trigger como objeto do banco de dados, devendo seguir as regras básicas de nomenclatura de objetos. II. NOME DA TABELA – identifica o nome da tabela à qual o trigger estará ligado, para ser disparado mediante ações de insert, update ou delete. III. Opção X/Y/Z – escolhida para definir o momento em que o trigger será disparado, onde X representa o valor padrão e faz com o que o gatilho seja disparado junto da ação, Y faz com que o disparo se dê somente após a ação que o gerou ser concluída, e Z faz com que o trigger seja executado no lugar da ação que o gerou. IV. Opção M/N/P – escolhida entre as instruções DML para indicar e informar ao banco qual ação irá disparar o gatilho.
Os parâmetros que devem substituir X/Y/Z em III e M/N/P em IV são, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771441
Banco de Dados
A SQL é conhecida comercialmente como uma
“linguagem de consulta” padrão utilizada para
manipular bases de dados relacionais, possuindo
diversos recursos na definição da estrutura de dados
para modificação de dados no banco de dados e para
a especificação de restrições de segurança. A SQL
integra três sub-linguagens, descritas a seguir.
I. Suporta comandos para manipular dados, como select, insert, update e delete. II. Suporta comandos para supervisionar o acesso aos dados, como grant e revoke. III. Suporta comandos para criação de objetos e administração do banco de dados, como alter e drop.
As sub-linguagens descritas em I, II e III são, respectivamente:
I. Suporta comandos para manipular dados, como select, insert, update e delete. II. Suporta comandos para supervisionar o acesso aos dados, como grant e revoke. III. Suporta comandos para criação de objetos e administração do banco de dados, como alter e drop.
As sub-linguagens descritas em I, II e III são, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771443
Banco de Dados
No que diz respeito à análise das informações e
tomada de decisões, um termo possui as
características listadas a seguir.
É um sistema utilizado para armazenar dados, de uma maneira organizada.
Pode guardar informações relativas às atividades de uma organização em bancos de dados, de forma consolidada. O desenho da base de dados favorece os relatórios, a análise de grandes volumes de dados e a obtenção de informações estratégicas que podem facilitar a tomada de decisão.
Centraliza e consolida grandes quantidades de dados de várias fontes. Seus recursos analíticos permitem que as organizações obtenham informações de negócios úteis de seus dados para melhorar a tomada de decisões.
É um sistema utilizado para armazenar dados, de uma maneira organizada.
Pode guardar informações relativas às atividades de uma organização em bancos de dados, de forma consolidada. O desenho da base de dados favorece os relatórios, a análise de grandes volumes de dados e a obtenção de informações estratégicas que podem facilitar a tomada de decisão.
Centraliza e consolida grandes quantidades de dados de várias fontes. Seus recursos analíticos permitem que as organizações obtenham informações de negócios úteis de seus dados para melhorar a tomada de decisões.
Esse termo é conhecido como:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771444
Banco de Dados
No que concerne à arquitetura de sistemas de
bancos de dados Oracle, existem diversos termos
específicos, siglas e nomes de serviços e aplicações.
Entre estes termos, dois são descritos a seguir.
I. Arquivos físicos de log que permitem a recuperação da instância do banco de dados. Esses arquivos contêm um registro de todas as alterações feitas nos dados nas tabelas e índices do banco, assim como mudanças realizadas na estrutura do banco de dados em si. A instância pode recuperar o banco com as informações contidas nesses arquivos – se os datafiles não forem perdidos. II. Área da SGA que armazena dados como declarações SQL executadas, cópias do dicionário de dados do banco e cache de resultados de consultas SQL e PL/SQL para reuso. Também contém dados das tabelas de sistema, como informações do conjunto de caracteres e informações de segurança.
Os termos descritos em I e em II são denominados, respectivamente:
I. Arquivos físicos de log que permitem a recuperação da instância do banco de dados. Esses arquivos contêm um registro de todas as alterações feitas nos dados nas tabelas e índices do banco, assim como mudanças realizadas na estrutura do banco de dados em si. A instância pode recuperar o banco com as informações contidas nesses arquivos – se os datafiles não forem perdidos. II. Área da SGA que armazena dados como declarações SQL executadas, cópias do dicionário de dados do banco e cache de resultados de consultas SQL e PL/SQL para reuso. Também contém dados das tabelas de sistema, como informações do conjunto de caracteres e informações de segurança.
Os termos descritos em I e em II são denominados, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771445
Banco de Dados
A SQL oferece a possibilidade de uso de uma
cláusula no comando SELECT para eliminar
repetições em consultas, considerando as colunas
informadas na listagem de colunas do comando
SELECT que contenham valores iguais como o
mesmo registro. Considere o caso descrito a seguir.

A figura refere-se a uma tabela AUTO de um banco de dados relacional. Para saber as marcas de automóveis envolvidas nesse caso, foi utilizada uma query SQL, que retorna essas marcas, sem repetição, indicada na
tabela SAIDA - .
.
O comando SQL empregado foi:
A figura refere-se a uma tabela AUTO de um banco de dados relacional. Para saber as marcas de automóveis envolvidas nesse caso, foi utilizada uma query SQL, que retorna essas marcas, sem repetição, indicada na
tabela SAIDA -
. O comando SQL empregado foi:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771449
Banco de Dados
No que diz respeito à manipulação de dados em
bancos de dados relacionais, Stored Procedure é um
bloco de código PL/SQL armazenado no servidor
com as seguintes características:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771450
Banco de Dados
No que diz respeito à mineração de dados, Data
Mining é um processo para explorar grandes
quantidades de dados à procura de padrões
consistentes, visando transformar dados em
informações úteis, e que utiliza diversas técnicas de
análise e mineração de dados, das quais três são
caracterizadas a seguir.
I. É direcionada ao agrupamento de dados, com base em um critério de identificação de dados semelhantes, fundamental para a seleção de grupos e posterior geração de insights. II. São utilizadas com mais frequência nos estágios iniciais do processo de Data Mining que servem para modelar relações entre os dados que entram e saem do processo de mineração. Por meio do uso de algoritmos, podem reconhecer padrões escondidos e correlações em dados brutos, agrupá-los e classificá-los e, com o tempo, aprender e melhorar continuamente. III. É uma ferramenta para ajudar uma pessoa, ou um grupo de pessoas, a tomarem uma decisão ao visualizar as suas ramificações e consequências. É uma ferramenta de suporte bastante útil para orientar discussões e guiar um grupo na resolução de um problema ou, até mesmo, na elaboração de um plano de ação. É de fácil interpretação dos dados e mostra o caminho a ser percorrido para alcançar determinado objetivo.
Essas técnicas em I, II e III, são conhecidas, respectivamente, como:
I. É direcionada ao agrupamento de dados, com base em um critério de identificação de dados semelhantes, fundamental para a seleção de grupos e posterior geração de insights. II. São utilizadas com mais frequência nos estágios iniciais do processo de Data Mining que servem para modelar relações entre os dados que entram e saem do processo de mineração. Por meio do uso de algoritmos, podem reconhecer padrões escondidos e correlações em dados brutos, agrupá-los e classificá-los e, com o tempo, aprender e melhorar continuamente. III. É uma ferramenta para ajudar uma pessoa, ou um grupo de pessoas, a tomarem uma decisão ao visualizar as suas ramificações e consequências. É uma ferramenta de suporte bastante útil para orientar discussões e guiar um grupo na resolução de um problema ou, até mesmo, na elaboração de um plano de ação. É de fácil interpretação dos dados e mostra o caminho a ser percorrido para alcançar determinado objetivo.
Essas técnicas em I, II e III, são conhecidas, respectivamente, como: