Questões de Concurso
Sobre banco de dados
Foram encontradas 15.756 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Quanto aos conceitos relativos à arquitetura de dados, julgue o item a seguir.
Em normalização de banco de dados, na terceira forma
normal os valores em um registro que não fazem parte da
chave desse registro não pertencem à tabela; em geral,
sempre que o conteúdo de um grupo de campos se aplica a
mais de um único registro na tabela, recomenda-se colocar
esses campos em uma tabela separada.
Quanto aos conceitos relativos à arquitetura de dados, julgue o item a seguir.
No modelo físico de dados, todas as informações coletadas
são convertidas em modelos relacionais e modelos de
negócios. Durante a modelagem física, os objetos são
definidos no denominado nível de esquema, logo, não
depende do software que já está sendo usado na organização.
Quanto aos conceitos relativos à arquitetura de dados, julgue o item a seguir.
O desenvolvimento de soluções inicia pela modelagem de dados conceitual, que é feita geralmente pelo gestor de dados de negócio ou outro profissional acompanhado de sua supervisão e(ou) orientação.
O Hadoop Distributed File System (HDFS) é construído usando a linguagem Java, o que permite que sua arquitetura mestre/escravo seja implementada em uma ampla variedade de máquinas
Com referência aos conceitos de banco de dados e data warehouse, julgue o item seguinte.
Em sistemas NoSQL baseados em armazenamento de chave-valor, a chave é multidimensional e composta pela
combinação do nome de tabela com a chave linha-coluna e
com o rótulo de data e hora.

Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.

A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Por meio do comando SQL a seguir, é possível recuperar o nome dos pesquisadores responsáveis por projetos, seguido pelo nome de seu orientador, mas apenas os projetos orientados por Pedro.

Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.
A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Projeto é uma entidade fraca em relação à entidade
Pesquisador, considerando o relacionamento
identificado como Responsavel e os atributos do MER.
Com respeito a métodos para imputação de dados, julgue o seguinte item.
Um dos passos para tratar com dados faltantes é avaliar o
tipo de dado perdido; assim, por exemplo, o método MICE
(multivariate imputation by chained equations) não seria
aplicável para dados perdidos do tipo MAR (missing at
random).
Com respeito a métodos para imputação de dados, julgue o seguinte item.
O método de imputação K-NN (k-nearest neighbours) leva
em consideração os padrões de similaridade presentes no
conjunto de dados para predizer os valores faltantes. No
entanto, a escolha da função de distância para a aplicação
desse método, como, por exemplo, HEOM (heterogeneous
euclidean-overlap metric) ou HVDM (heterogeneous value
difference metric), pode influenciar significativamente nos
resultados da imputação.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere que, em uma análise de agrupamentos por meio de
mistura de gaussianas, três distribuições normais com médias 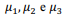 se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média
se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média 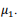
Os hiperparâmetros de um modelo são todos os parâmetros que podem ser definidos antes do inicio do treinamento, diferentemente dos parâmetros do modelo, que são aprendidos durante o treino do modelo. A busca por hiperparâmetros de determinado algoritmo de aprendizado de máquina que retorne o melhor desempenho medido em um conjunto de validação deu origem ao conceito de otimização de hiperparâmetros.
Acerca dos conceitos de otimização de hiperparâmetros de
modelos de aprendizado de máquinas, julgue o item que se segue.
A otimização bayesiana se utiliza do conceito de
probabilidade para encontrar o valor de entrada de uma
função que possa retornar o menor valor de saída possível.
Nesse método, o número de iterações de pesquisa pode ser
reduzido a partir da escolha dos valores de entrada, levando
em consideração os resultados anteriores, o que caracteriza
um processo iterativo.
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Em um processo em que se utiliza a ciência de dados, o número de variáveis necessárias para a realização da investigação de um fenômeno é direta e simplesmente igual ao número de variáveis utilizadas para mensurar as respectivas características desejadas; entretanto, é diferente o procedimento para determinar o número de variáveis explicativas, cujos dados estejam em escalas qualitativas.
Considerando esse aspecto dos modelos de regressão, julgue o item a seguir.
Para evitar um erro de ponderação arbitrária, deve-se
recorrer ao artifício de uso de variáveis dummy, o que
permitirá a estratificação da amostra da maneira que for
definido um determinado critério, evento ou atributo, para
então serem inseridas no modelo em análise; isso permitirá o
estudo da relação entre o comportamento de determinada
variável explicativa qualitativa e o fenômeno em questão,
representado pela variável dependente.
João é um cientista de dados que iniciou o processo de estudo dos dados de sua empresa com o objetivo de identificar um diferencial competitivo diante de seus concorrentes. Como resultado, João decidiu implementar um Big Data e hospedá-lo em um ambiente de nuvem.
Diante das possibilidades dos serviços, considerando os requisitos de escalabilidade e elasticidade, em caso de aumento de demanda pontual, aliados à tecnologia de Big Data, a alternativa que melhor descreve o tipo de serviço em nuvem a ser contratado por João é:
Considere uma tabela de banco de dados T1, com colunas A e B, e outra, T2, com colunas C e D. A coluna A constitui a chave primária de T1. Não há chave primária em T2. Há n1 registros em T1 e n2 registros em T2, n1 > 0 e n2 > 0.
Considere ainda o comando SQL a seguir.
select distinct A
from T1 right join T2 on T1.A=T2.C
Para quaisquer instâncias de T1 e T2 de acordo com as premissas acima, é correto afirmar, sobre o resultado produzido pela execução desse comando, que:
No contexto da implementação de bancos de dados, o acrônimo ACID denota o conjunto de propriedades que devem ser observadas por sistemas transacionais.
Essas quatro propriedades são:
Considere um projeto de banco de dados no qual há uma tabela T com colunas a, b, c, d. Sabe-se que, para essa tabela, são verificadas as seguintes dependências funcionais:
a → b
a → c
a → d
b → c
c → a
Com relação às restrições de integridade decorrentes do
processo de normalização da tabela T, as constraints incluídas no
comando create table devem ser equivalentes a:
No contexto do ambiente Android, considere as seguintes afirmativas a respeito do SQLite.
I. Deve ser utilizado com o apoio de um servidor de bancos de dados separado.
II. Suporta transações (ACID).
III. Sua instalação requer cuidados, haja vista o número de arquivos que devem ser preparados.
Está correto o que se afirma em:
Quanto a gatilhos (triggers), procedimentos armazenados (stored procedures) e gerência de bloqueios, julgue o item subsecutivo.
Trigger é um tipo especial de procedimento armazenado que
é executado em resposta a determinado evento na tabela,
como inserção, exclusão ou atualização de dados.