Questões de Concurso
Sobre banco de dados
Foram encontradas 15.698 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Observe the instruction below:
SELECT * FROM Companies WHERE Name LIKE '%ar%';
The SQL statement finds any values that:
Em uma tabela chamada Func, que continha os dados dos funcionários da organização, um administrador de banco de dados digitou o comando TRUNCATE TABLE Func.
Com base nessa situação hipotética, é correto afirmar que o comando teve a finalidade de
CREATE TABLE Cliente (
ID int NOT NULL,
Nome varchar(100),
Idade int,
Cidade varchar(100),
_________
);
Na criação, com SQL, da tabela mostrada acima, para se
definir uma restrição, na coluna Idade, que garanta que a
idade de entrada seja maior ou igual a 18, deve-se utilizar, na
lacuna, a instrução
A Internet das coisas (IoT) aumenta a quantidade e a complexidade dos dados por meio de novas formas e novas fontes de informações, influenciando diretamente em uma ou mais das características do big data, a exemplo de volume, velocidade e variedade.
Considere um banco de dados relacional e o código abaixo, em SQL:
CREATE TABLE cliente
(
id INT,
nome CHAR(20),
telefone CHAR(15),
endereco CHAR(30)
);
O 'nome' representa:
I. Os tesauros são utilizados para permitir ao usuário encontrar o termo que represente um determinado significado para o que procura. II. As taxonomias navegacionais são utilizadas para permitir que os usuários leigos naveguem pelo conteúdo do repositório e, por esse motivo, são criadas levando em conta o comportamento do usuário. III. As taxonomias descritivas não auxiliam os especialistas em suas buscas por informações. IV. As ontologias permitem o aprimoramento das buscas realizadas pelos usuários com a delimitação do contexto.
Está (estão) correta(s):
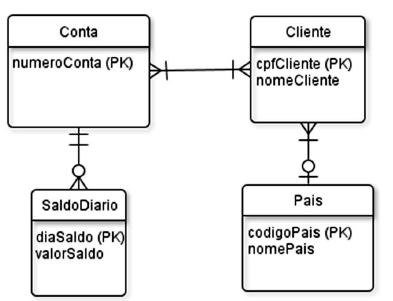
Foi feita uma transformação desse diagrama em tabelas relacionais para a terceira forma normal, na qual o sublinhado indica chaves primárias e não são usadas chaves substitutas ou artificiais (surrogate keys).
Qual a melhor representação dessa transformação?
• uma tabela possui um nome e um conjunto de colunas, separadas por vírgulas; • em uma linha qualquer, os valores referentes às colunas são atômicos e monovalorados; • colunas que admitem o valor nulo aparecem entre colchetes; • colunas que compõem a chave primária aparecem sublinhadas; • a notação X → Y indica que Y depende funcionalmente de X (ou X determina Y).
De acordo com a notação apresentada, qual esquema relacional de banco de dados se encontra na 3FN?
Os responsáveis pelo site desejam contratar o desenvolvimento de um sistema de informação que lhes permita saber o seguinte:
• Quais imóveis estão disponíveis para alugar? • Quais se encontram alugados em determinado momento? • Quais estarão disponíveis nos próximos 15 dias? • Quem é o locador que ofereceu determinado imóvel para aluguel? • Quais são os imóveis que determinado locatário reservou para aluguel nos próximos 90 dias?
Vale ressaltar, ainda, que os responsáveis pelo site desejam que o registro de um aluguel seja fisicamente excluído do banco de dados tão logo esse aluguel se encerre. Além disso, querem que o banco de dados não contenha redundâncias de dados desnecessárias.
Qual modelo conceitual de dados atende aos requisitos apresentados?
O modelo conceitual de dados apresentado a seguir exibe uma generalização exclusiva e total.
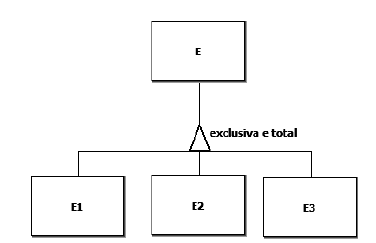
Um banco de dados é composto por um conjunto cujos elementos são instâncias da entidade E presente no diagrama acima.
E={e1, e2, e3, e4, e5, e6, e7, e8, e9, e10}
Nesse cenário, quais subconjuntos de E NÃO violam as
propriedades dessa generalização?
Quais operações OLAP a serem realizadas sobre a tabela inicial atenderão a essa solicitação do diretor de operações?
SELECT * FROM Compras where codProduto not in (select codProduto from Produtos where codProduto<3 or valor<4000)
Para simplificar o código, sem alterar a resposta, a instrução apresentada acima pode ser substituída por
I- DML é acrônimo de 'Data Management Language'. II- Os comandos INSERT, DELETE e UPDATE são do tipo DML. III- Os comandos INSERT e UPDATE são do tipo DDL. IV- DDL é acrônimo de 'Data Description Language'.
Assinale a alternativa correta:
Considere a seguinte estrutura de um banco SQL:
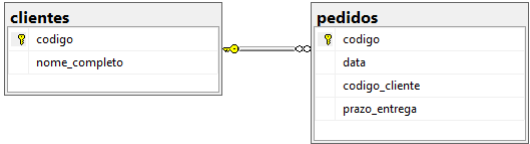
Selecione a consulta SQL que permite retornar o nome do cliente e o prazo para clientes, cujo nome comece com 'M' e com pedidos cujo prazo de entrega médio seja maior que 30.
A alternativa que contempla o exposto é: