Questões de Concurso
Sobre banco de dados
Foram encontradas 15.797 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Uma das principais novidades do Microsoft SQL Server 2014 é o recurso OLTP na memória (In-memory OLTP), o qual permite melhorar significativamente o desempenho de sistemas com processamento de transações on-line e data warehousing. A única maneira de remover um grupo de arquivos com otimização de memória é descartar o banco de dados.
O PostgreSQL 9.3 possui a propriedade de autocommit, isto é, qualquer comando SQL executado será automaticamente efetivado no banco, sendo impossível desabilitar este comportamento.
A utilização de um arquivo SQL autocontido restringe a importação das tabelas aos seus Schemas originais.
A importação de uma tabela específica somente poderá ser realizada se a exportação dessa tabela tiver sido feita por meio de pastas do projeto.
Um arquivo HTML com o conteúdo de uma tabela pode ser gerado por meio da função exportação de dados.
A função exportação de dados permite exportar a estrutura de uma tabela, sem que sejam exportados os seus dados.

A figura apresentada ilustra um modelo de dados implementado em MySQL 5.7, com a utilização de tabelas do tipo InnoDB. Considere que, trinta dias após a implementação dessas tabelas, os seguintes comportamentos foram observados:
 a tabela A apresentou 1 milhão de registros por dia;
a tabela A apresentou 1 milhão de registros por dia;
 como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
 o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
 a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
 todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
 as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
A criação de um índice na tabela A, composto apenas pelo campo B1, aumentará o desempenho das operações de leitura e escrita observadas nessa tabela.
A figura apresentada ilustra um modelo de dados implementado em MySQL 5.7, com a utilização de tabelas do tipo InnoDB. Considere que, trinta dias após a implementação dessas tabelas, os seguintes comportamentos foram observados:
a tabela A apresentou 1 milhão de registros por dia;
como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
A criação de um índice do tipo HASH, utilizando-se os cinco primeiros caracteres do campo B2, aumentará a probabilidade de desempenho das consultas observadas na tabela B.
A figura apresentada ilustra um modelo de dados implementado em MySQL 5.7, com a utilização de tabelas do tipo InnoDB. Considere que, trinta dias após a implementação dessas tabelas, os seguintes comportamentos foram observados:
a tabela A apresentou 1 milhão de registros por dia;
como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
Em caso de crash, a recuperação de A e B necessitará de intervenção manual para realizar rollback dos registros não confirmados, devido à engine utilizada.
A figura apresentada ilustra um modelo de dados implementado em MySQL 5.7, com a utilização de tabelas do tipo InnoDB. Considere que, trinta dias após a implementação dessas tabelas, os seguintes comportamentos foram observados:
a tabela A apresentou 1 milhão de registros por dia;
como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
Na execução de um hot backup nas tabelas A e B, as operações de leitura e escrita estão disponíveis nas respectivas tabelas.
A figura apresentada ilustra um modelo de dados implementado em MySQL 5.7, com a utilização de tabelas do tipo InnoDB. Considere que, trinta dias após a implementação dessas tabelas, os seguintes comportamentos foram observados:
a tabela A apresentou 1 milhão de registros por dia;
como critério de busca, em 20% das consultas realizadas na
tabela A, foram utilizados cinco caracteres ao final do campo
A2 e, no restante das consultas realizadas, utilizou-se um
número específico no campo B1 da tabela A;
o campo B1 da tabela A continha uma chave estrangeira,
referenciada para o campo B1 da tabela B;
a tabela B apresentava duzentos mil registros, a mesma
quantidade desde a data de sua implantação;
todas as consultas realizadas na tabela B utilizaram, como
critério de busca, os cinco primeiros caracteres do campo B2;
as tabelas A e B apresentaram quantidade fixa de consultas
diárias, igual a dez acessos e um milhão de acessos,
respectivamente.
Para criar um índice no campo A4, é obrigatória a determinação de um prefixo de caracteres.
Transação é uma coleção de operações de escrita e(ou) leitura, que representa uma única unidade de trabalho.
Os bloqueios no modo compartilhado são considerados compatíveis entre si, visto que bloqueios simultâneos, nesse modo, podem ser mantidos por diferentes transações sobre um mesmo item de dados.
Uma transação é considerada estagnada quando aguarda, por tempo indeterminado, a obtenção de um bloqueio no modo compartilhado, enquanto uma segunda transação está sendo realizada no modo de bloqueio exclusivo.
Caso uma transação obtenha um bloqueio no modo compartilhado sobre um item de dados, essa transação poderá ler o item de dados e, também, escrever nele.
O isolamento de uma transação, de responsabilidade do componente de gerenciamento de controle de concorrência, pode ter o seu comportamento personalizado em vários níveis.
0 Considerando-se o diagrama entidade-relacionamento ilustrado a seguir, bem como as informações apresentadas na sequência, é correto afirmar que o atributo codigo_superior deve ser NOT NULL para permitir a inserção de informações das unidades organizacionais e sua hierarquia.
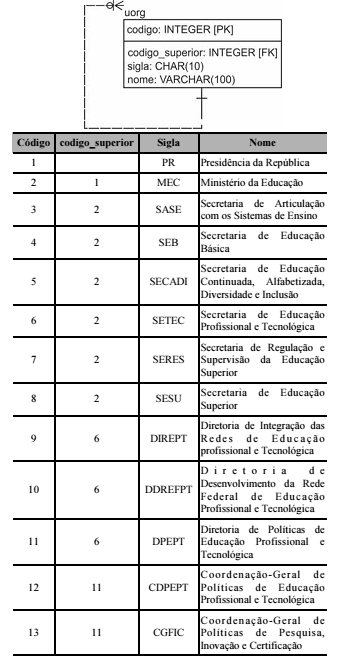
Em um processo de modelagem de dados, a cardinalidade define o número de ocorrências de uma entidade associadas às ocorrências de outra entidade por meio de um relacionamento específico.
No processo de modelagem do banco de dados, o modelo conceitual deve realizar uma descrição das estruturas onde serão armazenados os dados, uma vez que, nessa fase, é fundamental ter definida a estrutura do sistema gerenciador de banco de dados.