Questões de Concurso
Para fgv
Foram encontradas 109.060 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090120
Sistemas Operacionais
Analise as seguintes afirmações sobre conteinerização e
orquestração de contêineres.
I. Em sistemas conteinerizados, é recomendado que todos os contêineres compartilhem o mesmo sistema de arquivos e ambiente de rede para garantir consistência entre os serviços.
II. Em ferramentas de orquestração como Kubernetes, a comunicação entre contêineres pode ser gerenciada por uma rede de sobreposição, que permite a comunicação direta entre contêineres em diferentes nós, sem expor seus endereços IP ao ambiente externo.
III. A principal vantagem da conteinerização em relação à virtualização tradicional é a capacidade de compartilhar o kernel do sistema operacional host, o que garante isolamento total entre contêineres, como em máquinas virtuais.
É correto o que se afirma em
I. Em sistemas conteinerizados, é recomendado que todos os contêineres compartilhem o mesmo sistema de arquivos e ambiente de rede para garantir consistência entre os serviços.
II. Em ferramentas de orquestração como Kubernetes, a comunicação entre contêineres pode ser gerenciada por uma rede de sobreposição, que permite a comunicação direta entre contêineres em diferentes nós, sem expor seus endereços IP ao ambiente externo.
III. A principal vantagem da conteinerização em relação à virtualização tradicional é a capacidade de compartilhar o kernel do sistema operacional host, o que garante isolamento total entre contêineres, como em máquinas virtuais.
É correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090119
Segurança da Informação
Considerando os conceitos e ferramentas relacionados a serviços de
autenticação/autorização, webhooks e message brokers, avalie se as
afirmativas a seguir são verdadeiras (V) ou falsas (F).
( ) Um dos principais objetivos do SAML é proporcionar Single-Sign On (SSO), isto é, permitir que um usuário se autentique uma vez e tenha acesso a outros sistemas sem a necessidade de fornecer novamente suas credenciais.
( ) No protocolo MQTT do RabbitMQ, a publicação de mensagens acontece dentro do contexto de um link.
( ) Keycloak permite a implementação de Single-Sign On (SSO) e fornece suporte para OpenID Connect e OAuth 2.0.
As afirmativas são, respectivamente,
( ) Um dos principais objetivos do SAML é proporcionar Single-Sign On (SSO), isto é, permitir que um usuário se autentique uma vez e tenha acesso a outros sistemas sem a necessidade de fornecer novamente suas credenciais.
( ) No protocolo MQTT do RabbitMQ, a publicação de mensagens acontece dentro do contexto de um link.
( ) Keycloak permite a implementação de Single-Sign On (SSO) e fornece suporte para OpenID Connect e OAuth 2.0.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090117
Banco de Dados
O H2 Database é um sistema de gerenciamento de banco de dados
relacional open source desenvolvido em Java.
A respeito de características do H2 Database, julgue as seguintes afirmativas.
I. O modo incorporado é mais lento que o modo servidor.
II. No modo servidor, uma aplicação abre um banco de dados remotamente por meio da API JDBC ou ODBC.
III. Não é possível combinar conexões locais e remotas ao mesmo tempo.
Está correto o que se afirma em
A respeito de características do H2 Database, julgue as seguintes afirmativas.
I. O modo incorporado é mais lento que o modo servidor.
II. No modo servidor, uma aplicação abre um banco de dados remotamente por meio da API JDBC ou ODBC.
III. Não é possível combinar conexões locais e remotas ao mesmo tempo.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090115
Arquitetura de Software
Uma API REST (Representational State Transfer) é uma interface que
permite a comunicação entre sistemas utilizando um determinado
protocolo em que os recursos são acessados e manipulados por meio
de requisições padrão como GET, POST, PUT e DELETE, seguindo
princípios de simplicidade, escalabilidade e independência de
plataforma.
Isso posto, assinale a afirmativa correta a seguir sobre API REST.
Isso posto, assinale a afirmativa correta a seguir sobre API REST.
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090110
Legislação dos TRFs, STJ, STF e CNJ
Os Manuais e Protocolos criados pela Resolução CNJ nº 396/2021,
que instituiu a Estratégia Nacional de Segurança Cibernética do
Poder Judiciário (ENSEC-PJ) e aprovados pela Portaria nº 162 de
10/06/2021 normatizam diversas atividades na área de segurança
cibernética a serem implantadas pelos diversos órgãos do Poder
Judiciário.
Com base nos Manuais e Protocolos aprovados pela Portaria nº 162 de 10/06/2021, analise as informações a seguir.
I. Os Protocolos e Manuais serão atualizados a qualquer tempo por indicação do Comitê Gestor de Segurança Cibernética do Poder Judiciário.
II. O Protocolo de Investigação de Ilícitos Cibernéticos do Poder Judiciário (PIILC-PJ) deverá ser implementado por todos os órgãos do Poder Judiciário, com exceção do Supremo Tribunal Federal.
III. O Manual de Proteção de Infraestruturas de TIC descreve as ações responsivas a serem colocadas em prática quando ficar evidente que um incidente de segurança cibernética não será mitigado rapidamente e poderá durar dias, semanas ou meses.
Está correto o que se afirma em
Com base nos Manuais e Protocolos aprovados pela Portaria nº 162 de 10/06/2021, analise as informações a seguir.
I. Os Protocolos e Manuais serão atualizados a qualquer tempo por indicação do Comitê Gestor de Segurança Cibernética do Poder Judiciário.
II. O Protocolo de Investigação de Ilícitos Cibernéticos do Poder Judiciário (PIILC-PJ) deverá ser implementado por todos os órgãos do Poder Judiciário, com exceção do Supremo Tribunal Federal.
III. O Manual de Proteção de Infraestruturas de TIC descreve as ações responsivas a serem colocadas em prática quando ficar evidente que um incidente de segurança cibernética não será mitigado rapidamente e poderá durar dias, semanas ou meses.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090107
Programação
Os dados são importante elemento de apoio à tomada de decisão,
sendo que algumas aplicações geram quantidade massiva e
heterogênea de dados, com alta velocidade. Para lidar com esse
cenário, foi desenvolvido um modelo de programação que consiste
em dividir, processar e combinar os dados em paralelo, de forma a
acelerar o processamento e garantir a confiabilidade dos resultados.
Assinale o modelo que contém as características elencadas no enunciado.
Assinale o modelo que contém as características elencadas no enunciado.
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090106
Programação
A biblioteca spaCy é utilizada em diferentes tarefas de
Processamento de Linguagem Natural. Ela disponibiliza o módulo
‘pt_core_news_sm’, que contém dados específicos provenientes de
textos em português.
Considere o trecho de código em linguagem Python a seguir.

Admitindo que a biblioteca spaCy e o modelo 'pt_core_news_sm' já estejam instalados na máquina em que o trecho de código será executado, a string impressa no prompt após a execução será
Considere o trecho de código em linguagem Python a seguir.
Admitindo que a biblioteca spaCy e o modelo 'pt_core_news_sm' já estejam instalados na máquina em que o trecho de código será executado, a string impressa no prompt após a execução será
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090103
Programação
Considerando a linguagem de programação Python, analise os itens
I, II e III a seguir. Os códigos foram escritos na versão 3.10.12.

Está correto o que se afirma em
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090102
Programação
Considere as linhas de código a seguir, que foram escritas na
linguagem de programação Python (versão 3.10.12), com utilização
de NumPy (versão 1.25.0).

Com relação à execução da linha <4>, assinale a afirmativa correta.
Com relação à execução da linha <4>, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090101
Estatística
Os outliers são dados que se distinguem significativamente dos
demais no conjunto. Um outlier é um valor que se desvia
substancialmente da normalidade e pode causar anomalias nos
resultados gerados por algoritmos e sistemas de análise.
A seguir, é apresentado um gráfico de boxplot, que ilustra os retornos mensais das ações de uma empresa
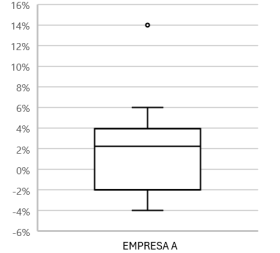
Nesse contexto, analise as seguintes afirmações.
I. Outliers nunca devem ser removidos, pois sempre carregam informações importantes e não têm a capacidade de distorcer resultados ou enviesar modelos de análise.
II. A partir da análise visual do boxplot apresentado, é possível afirmar que o valor 14% é um outlier, pois ele está visivelmente distante do corpo principal dos dados, fora do intervalo interquartil (IQR).
III. Para a detecção de outliers, além da identificação visual, é possível utilizar métodos estatísticos e técnicas baseadas em aprendizado de máquina.
Está correto o que se afirma em
A seguir, é apresentado um gráfico de boxplot, que ilustra os retornos mensais das ações de uma empresa
Nesse contexto, analise as seguintes afirmações.
I. Outliers nunca devem ser removidos, pois sempre carregam informações importantes e não têm a capacidade de distorcer resultados ou enviesar modelos de análise.
II. A partir da análise visual do boxplot apresentado, é possível afirmar que o valor 14% é um outlier, pois ele está visivelmente distante do corpo principal dos dados, fora do intervalo interquartil (IQR).
III. Para a detecção de outliers, além da identificação visual, é possível utilizar métodos estatísticos e técnicas baseadas em aprendizado de máquina.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090100
Conhecimentos Bancários
Regtechs e Suptechs têm se destacado como grandes tendências no
sistema financeiro. Com a modernização do setor e o crescimento
das fintechs, o mundo tem presenciado uma série de transformações
regulatórias para acompanhar e fomentar essas inovações.
Nesse contexto, analise as seguintes afirmações sobre Regtech e Suptech.
I. Suptech é voltada para as autoridades reguladoras, permitindo monitorar em tempo real o mercado e as instituições financeiras. Com o uso de big data e análise preditiva, essas tecnologias ajudam a identificar riscos, prevenir crises e garantir a estabilidade financeira.
II. O Suptech é voltado tanto para as autoridades reguladoras quanto para as empresas, com o objetivo de aprimorar a supervisão dos sistemas, aumentando a eficiência no monitoramento de transações e na detecção de fraudes.
III. As soluções de Regtech se concentram exclusivamente na gestão de dados e riscos das empresas, sem abordar aspectos relacionados a compliance ou a geração de relatórios regulatórios.
Está correto o que se afirma em
Nesse contexto, analise as seguintes afirmações sobre Regtech e Suptech.
I. Suptech é voltada para as autoridades reguladoras, permitindo monitorar em tempo real o mercado e as instituições financeiras. Com o uso de big data e análise preditiva, essas tecnologias ajudam a identificar riscos, prevenir crises e garantir a estabilidade financeira.
II. O Suptech é voltado tanto para as autoridades reguladoras quanto para as empresas, com o objetivo de aprimorar a supervisão dos sistemas, aumentando a eficiência no monitoramento de transações e na detecção de fraudes.
III. As soluções de Regtech se concentram exclusivamente na gestão de dados e riscos das empresas, sem abordar aspectos relacionados a compliance ou a geração de relatórios regulatórios.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090096
Engenharia de Software
Modelos de linguagem de larga escala (Large Language Models -
LLM) são frequentemente utilizados em processamento de
linguagem natural, e podem gerar resultados inesperados em
resposta às consultas dos usuários. Essas respostas são chamadas de
alucinações dos modelos. Uma técnica usada para se evitar tais
alucinações consiste em combinar os modelos generativos com
sistemas de recuperação de informações, permitindo buscas em
bases de dados mais confiáveis e melhorando a qualidade das
respostas geradas.
A essa técnica dá-se o nome de
A essa técnica dá-se o nome de
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090095
Programação
O processamento MapReduce consiste na aplicação de um algoritmo
de computação distribuída para processar grandes conjuntos de
dados em um cluster de computadores, dividindo cálculos
complexos em tarefas menores e que podem ser executadas em
paralelo. O MapReduce é implementado em etapas. Em uma dessas
etapas, os dados de entrada divididos em partes são transformados
em conjuntos de pares chave-valor (i.e., key-value pairs) adequados
para o processamento paralelo e distribuído.
A essa etapa do MapReduce dá-se o nome de
A essa etapa do MapReduce dá-se o nome de
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090094
Programação
A ingestão de dados consiste na coleta, importação ou transferência
de dados para um sistema de armazenamento e processamento. Em
geral, a ingestão de dados representa o primeiro passo em um
pipeline de processamento. Os dois principais métodos de ingestão
de dados são a ingestão em lote (batch) e a ingestão em tempo real
(streaming).
A respeito desses métodos, avalie as afirmativas a seguir.
I. A ingestão em lotes se dá continuamente ao longo do tempo e é utilizada quando há necessidade de se processar os dados imediatamente após sua coleta.
II. A ingestão em tempo real incorpora novos dados em massa, em intervalos ou blocos periodicamente transmitidos da fonte para o dispositivo em que ocorre o processamento.
III. Em ambos os métodos, é comum que os dados sejam transformados e validados, garantindo-se assim a precisão e a consistência das informações ingeridas.
Está correto o que se afirma em
A respeito desses métodos, avalie as afirmativas a seguir.
I. A ingestão em lotes se dá continuamente ao longo do tempo e é utilizada quando há necessidade de se processar os dados imediatamente após sua coleta.
II. A ingestão em tempo real incorpora novos dados em massa, em intervalos ou blocos periodicamente transmitidos da fonte para o dispositivo em que ocorre o processamento.
III. Em ambos os métodos, é comum que os dados sejam transformados e validados, garantindo-se assim a precisão e a consistência das informações ingeridas.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090093
Estatística
Um time de futebol disputa um campeonato em que joga um
número igual de partidas em seu estádio e fora de seu estádio. As
probabilidades de ganhar, empatar ou perder uma partida quando
joga em seu estádio são, respectivamente, 1/2, 1/5 e 3/10. As
probabilidades de ganhar, empatar ou perder uma partida quando
joga fora de seu estádio são, respectivamente, 1/5, 1/5 e 3/5.
Um torcedor desinformado, ao chegar em sua aula sobre inferência bayesiana, ouviu de seus amigos que o referido time havia perdido a última partida que disputou. Sem obter nenhuma informação adicional, o torcedor resolveu calcular as probabilidades (a posteriori) de o time haver jogado a última partida em seu estádio ou fora de seu estádio.
As probabilidades calculadas corretamente pelo torcedor foram, respectivamente,
Um torcedor desinformado, ao chegar em sua aula sobre inferência bayesiana, ouviu de seus amigos que o referido time havia perdido a última partida que disputou. Sem obter nenhuma informação adicional, o torcedor resolveu calcular as probabilidades (a posteriori) de o time haver jogado a última partida em seu estádio ou fora de seu estádio.
As probabilidades calculadas corretamente pelo torcedor foram, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090092
Estatística
Uma das etapas essenciais do tratamento e processamento de
dados, em especial para estatística e para o aprendizado de
máquina, consiste em sua organização e identificação. Uma maneira
de organizar os dados de um conjunto consiste em classificá-los.
Relacione cada uma das variáveis a seguir, constantes de um conjunto de dados sobre um grupo de pessoas, com a classificação a ela mais adequada.
1. Grau de instrução (ex.: superior)
2. Número de filhos
3. Estado de Procedência (ex.: Minas Gerais)
4. Massa corporal
( ) Quantitativa Contínua ( ) Quantitativa Discreta ( ) Qualitativa Nominal ( ) Qualitativa Ordinal
A relação correta, na ordem apresentada, é
Relacione cada uma das variáveis a seguir, constantes de um conjunto de dados sobre um grupo de pessoas, com a classificação a ela mais adequada.
1. Grau de instrução (ex.: superior)
2. Número de filhos
3. Estado de Procedência (ex.: Minas Gerais)
4. Massa corporal
( ) Quantitativa Contínua ( ) Quantitativa Discreta ( ) Qualitativa Nominal ( ) Qualitativa Ordinal
A relação correta, na ordem apresentada, é
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090091
Sistemas Operacionais
A normalização numérica é utilizada para o tratamento de dados,
especialmente quando o processamento é dificultado por conta de
as características de instâncias estarem distribuídas em diferentes
escalas e intervalos. Uma técnica comum de normalização numérica
utilizada para o tratamento de outliers é o escalonamento robusto,
que se utiliza da mediana e da distância entre o primeiro e o terceiro
quartis para efetuar o escalonamento dos dados.
Considere o conjunto de dados a seguir.
[3, 5, 7, 8, 10, 12, 15, 20, 22, 30, 50]
O valor normalizado por escalonamento robusto referente ao elemento “22” é dado aproximadamente por
Considere o conjunto de dados a seguir.
[3, 5, 7, 8, 10, 12, 15, 20, 22, 30, 50]
O valor normalizado por escalonamento robusto referente ao elemento “22” é dado aproximadamente por
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090090
Engenharia de Software
Um dos principais objetivos dos algoritmos de aprendizado de
máquinas é o de estabelecer um modelo que melhor descreva as
relações entre variáveis de um conjunto de dados. Em algumas
situações, ao serem treinados, os modelos ajustam-se
demasiadamente aos dados do conjunto, capturando até mesmo
padrões relacionados aos ruídos dos dados. Esses modelos tendem
a ser excessivamente complexos e a ter um mau desempenho na
generalização, isto é, nas etapas em que é necessário processar
novas instâncias de dados não pertencentes ao conjunto de
treinamento original.
Uma maneira de mitigar esse comportamento inconveniente é usar técnicas de
Uma maneira de mitigar esse comportamento inconveniente é usar técnicas de
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090089
Engenharia de Software
Técnicas de redução de dimensionalidade são usadas em
aprendizado de máquina para reduzir o número de características
(dimensões, ou, do inglês, features) de um conjunto de dados. Uma
das técnicas mais usadas para a redução de dimensionalidade é a
Análise de Componentes Principais (Principal Component Analysis -
PCA).
A respeito da PCA, avalie as afirmativas a seguir.
I. As componentes principais equivalem às direções resultantes do cálculo dos autovetores da matriz de covariâncias dos dados normalizados, selecionando-se aqueles autovetores associados aos menores autovalores, até um limite definido pelo analista.
II. As componentes principais equivalem, em geral, a combinações lineares das características originais do conjunto de dados.
III. A maior vantagem da PCA é a manutenção total das informações do conjunto de dados original, sem ocorrência de perdas decorrentes de projeções dos dados sobre as componentes principais.
Está correto o que se afirma em
A respeito da PCA, avalie as afirmativas a seguir.
I. As componentes principais equivalem às direções resultantes do cálculo dos autovetores da matriz de covariâncias dos dados normalizados, selecionando-se aqueles autovetores associados aos menores autovalores, até um limite definido pelo analista.
II. As componentes principais equivalem, em geral, a combinações lineares das características originais do conjunto de dados.
III. A maior vantagem da PCA é a manutenção total das informações do conjunto de dados original, sem ocorrência de perdas decorrentes de projeções dos dados sobre as componentes principais.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090088
Engenharia de Software
A classificação de dados é uma tarefa comumente executada por
meio de algoritmos de aprendizado de máquina. Uma técnica muito
conhecida de classificação se dá por aprendizado supervisionado, e
classifica novas instâncias de dados por associação à classe da
maioria das instâncias de dados preexistentes mais próximas a elas.
A avaliação dessa proximidade é baseada em normas (isto é,
métricas de distância) definidas no espaço multidimensional das
amostras.
Assinale a técnica de classificação que melhor se enquadra nas características descritas acima.
Assinale a técnica de classificação que melhor se enquadra nas características descritas acima.