Questões de Concurso
Foram encontradas 10.215 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2014
Banca:
FCC
Órgão:
TRT - 13ª Região (PB)
Prova:
FCC - 2014 - TRT - 13ª Região (PB) - Analista Judiciário - Estatística |
Q457267
Estatística
A tabela de frequências absolutas, abaixo, corresponde à distribuição dos salários dos empregados em uma empresa, em que todos os intervalos de classe têm a mesma amplitude. O valor da mediana dos salários (obtido por interpolação linear) é igual a R$ 4.100,00 e pertence ao intervalo [c , d) em que c = R$ 3.500,00.
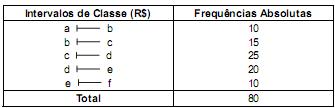
Calculando o valor da média aritmética destes salários, considerando que todos os valores incluídos em um certo intervalo de classe são coincidentes com o ponto médio deste intervalo, verifica-se que este valor pertence ao intervalo (em R$)
Ano: 2014
Banca:
FUNCAB
Órgão:
SEFAZ-BA
Prova:
FUNCAB - 2014 - SEMGE - BA - Auditor Fiscal - Tecnologia da Informação - Manhã |
Q457078
Estatística
Inicialmente, a média aritmética dos faturamentos dos últimos cinco meses de uma loja foi de R$ 126.000,00. Porém, após uma revisão, verificou-se que o faturamento do último mês, no valor de R$ 134.000,00, estava errado. Após a devida correção, a nova média dos faturamentos dos últimos cinco meses foi de R$ 125.000,00. Determine o valor correto do faturamento do último mês.
Ano: 2014
Banca:
FUNCAB
Órgão:
SEFAZ-BA
Prova:
FUNCAB - 2014 - SEMGE - BA - Auditor Fiscal - Tecnologia da Informação - Manhã |
Q457077
Estatística
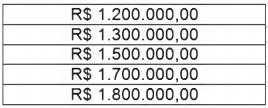
A tabela a seguir contém o faturamento dos últimos cinco meses de um hotel. Pode-se afirmar que o desvio-padrão X, dos faturamentos na tabela, pertence ao intervalo:
Ano: 2014
Banca:
CESGRANRIO
Órgão:
Petrobras
Prova:
CESGRANRIO - 2014 - Petrobras - Engenheiro(a) de Produção Júnior |
Q454115
Estatística
Uma agência de viagens possui apenas um funcionário para atender a seus clientes. Como os vários pacotes turísticos comercializados diferem muito entre si, a taxa de atendimento é distribuída aleatoriamente, mas se aproxima da de Poisson. Em média, chegam dois clientes a cada 50 minutos, e são atendidos quatro a cada hora. Os clientes toleram aguardar, em média, 25 minutos na fila antes de desistir do atendimento.
Nesse caso, pode-se dizer que a agência corre
Nesse caso, pode-se dizer que a agência corre
Ano: 2014
Banca:
CESGRANRIO
Órgão:
Petrobras
Prova:
CESGRANRIO - 2014 - Petrobras - Engenheiro(a) de Equipamentos Júnior - Elétrica |
Q454081
Estatística
Uma tensão elétrica de natureza aleatória incide sobre um circuito elétrico, causando incertezas. A variável aleatória v tem a sua função densidade de probabilidade dada em volts assim definida para v:

Qual é o valor médio esperado dessa tensão, em volts?
Qual é o valor médio esperado dessa tensão, em volts?
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452955
Estatística
Uma variável aleatória Gama é definida para valores reais e positivos e sua função densidade é dada por
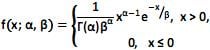
com parâmetros α > 0 e ß > 0.
Diante do exposto, analise as afirmativas.
I. Pode-se demonstrar que E(x) = αß e Var(x) = αß2.
II. A função gama é dada por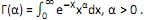
III. Pode-se mostrar que G(α) = (α – 1) G(α – 1) e para α inteiro, G(α) = (α – 1)!.
IV. Quando α = 1, a função densidade da gama e igual à distribuição exponencial com parâmetro ß.
V. Quando α = v/2 e ß = 2, com v > 0 inteiro, a função densidade da gama é igual à distribuição Qui-quadrado com ? graus de liberdade.
Estão corretas apenas as afirmativas
com parâmetros α > 0 e ß > 0.
Diante do exposto, analise as afirmativas.
I. Pode-se demonstrar que E(x) = αß e Var(x) = αß2.
II. A função gama é dada por
III. Pode-se mostrar que G(α) = (α – 1) G(α – 1) e para α inteiro, G(α) = (α – 1)!.
IV. Quando α = 1, a função densidade da gama e igual à distribuição exponencial com parâmetro ß.
V. Quando α = v/2 e ß = 2, com v > 0 inteiro, a função densidade da gama é igual à distribuição Qui-quadrado com ? graus de liberdade.
Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452954
Estatística
O modelo de regressão logística é um caso particular de um modelo linear generalizado em que o componente aleatório tem distribuição Bernoulli e a função de ligação é a logito. Diante do exposto, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade: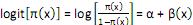 , ou seja, p(x) aumenta ou diminui como uma função linear de x.
, ou seja, p(x) aumenta ou diminui como uma função linear de x.
( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:

( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
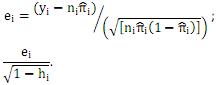
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade:
, ou seja, p(x) aumenta ou diminui como uma função linear de x. ( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:
( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452952
Estatística
O modelo de análise fatorial representa a estrutura de cova- riância entre muitas variáveis aleatórias 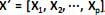 , através de poucas variáveis não observáveis F´ = [
, através de poucas variáveis não observáveis F´ = [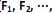
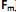 ] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz
] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz 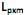 é conhecida como matriz das cargas fatoriais e seus elementos,
é conhecida como matriz das cargas fatoriais e seus elementos,  , carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas.
, carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas.
( ) No modelo fatorial ortogonal, as variáveis não observáveis F e e são independentes, E(F) = 0, V(F) = E(F´F) = I, E(e) = 0, V(e) = E(e´e) = ?. A matriz ? é não diagonal, V(X) = S = L´L + ? e Cov (X, F) = L.
( ) Um método de estimação para as cargas do modelo fatorial ortogonal é através de componentes principais, onde se utiliza a decomposição espectral da matriz S.
( ) Para se utilizar o método de máxima verossimilhança para estimar as cargas, é acrescida a suposição de que F e e têm distribuição normal multivariada. As comunalidades (elementos da diagonal LL´) têm como estimadores a proporção da variância total estimada pelo particular fator.
( ) Para melhorar a explicação do modelo fatorial, sem alterar a ortogonalidade dos fatores, muitas vezes, usa- se uma transformação ortogonal das cargas fatoriais, que, consequentemente, transforma os fatores. Esse procedimento é conhecido como rotação fatorial.
( ) Dependendo da natureza dos dados, os fatores não precisam ser ortogonais. Assim, para melhorar a explicação do modelo fatorial, pode-se utilizar a rotação oblíqua, onde cada variável é expressa em termos de um número máximo de fatores.
A sequência está correta em
, através de poucas variáveis não observáveis F´ = [ ] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz é conhecida como matriz das cargas fatoriais e seus elementos, , carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas. ( ) No modelo fatorial ortogonal, as variáveis não observáveis F e e são independentes, E(F) = 0, V(F) = E(F´F) = I, E(e) = 0, V(e) = E(e´e) = ?. A matriz ? é não diagonal, V(X) = S = L´L + ? e Cov (X, F) = L.
( ) Um método de estimação para as cargas do modelo fatorial ortogonal é através de componentes principais, onde se utiliza a decomposição espectral da matriz S.
( ) Para se utilizar o método de máxima verossimilhança para estimar as cargas, é acrescida a suposição de que F e e têm distribuição normal multivariada. As comunalidades (elementos da diagonal LL´) têm como estimadores a proporção da variância total estimada pelo particular fator.
( ) Para melhorar a explicação do modelo fatorial, sem alterar a ortogonalidade dos fatores, muitas vezes, usa- se uma transformação ortogonal das cargas fatoriais, que, consequentemente, transforma os fatores. Esse procedimento é conhecido como rotação fatorial.
( ) Dependendo da natureza dos dados, os fatores não precisam ser ortogonais. Assim, para melhorar a explicação do modelo fatorial, pode-se utilizar a rotação oblíqua, onde cada variável é expressa em termos de um número máximo de fatores.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452951
Estatística
O modelo de componentes principais é utilizado para representar a estrutura de variância-covariância em função de um número reduzido de combinações lineares das variáveis originais, com o objetivo de se ter uma redução de dados e uma melhor interpretação destes. Para o vetor aleatório 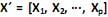 com matriz de covariância S e autovalores iguais a
com matriz de covariância S e autovalores iguais a  , e as combinações lineares:
, e as combinações lineares:
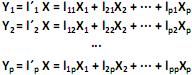
O modelo de componentes principais corresponde às combinações lineares não correlacionadas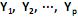 com vetores de coeficientes
com vetores de coeficientes 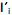 de comprimento unitário, que apresentam as maiores variâncias Var
de comprimento unitário, que apresentam as maiores variâncias Var 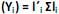 . Diante do exposto, é correto afirmar que
. Diante do exposto, é correto afirmar que
I. o primeiro componente principal é a combinação linear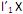 que maximiza Var
que maximiza Var 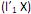 sujeito a
sujeito a 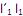 = 1.
= 1.
II. o i-ésimo componente principal é a combinação linear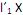 que maximiza Var
que maximiza Var 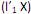 = 1 e Cov (
= 1 e Cov (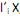 ,
, 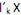 ) = 0, para k < i.
) = 0, para k < i.
III. sendo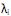 os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por
os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por 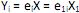 +
+  , onde i = 1, ··· p.
, onde i = 1, ··· p.
IV. Var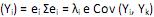 = 0, para i = 1,2, ···, p e i ≠ k.
= 0, para i = 1,2, ···, p e i ≠ k.
V. a proporção da variância total devido ao k-ésimo componente principal é dada por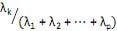 para k = 1, ···, p.
para k = 1, ···, p.
Estão corretas apenas as afirmativas
com matriz de covariância S e autovalores iguais a , e as combinações lineares: O modelo de componentes principais corresponde às combinações lineares não correlacionadas
com vetores de coeficientes de comprimento unitário, que apresentam as maiores variâncias Var . Diante do exposto, é correto afirmar que I. o primeiro componente principal é a combinação linear
que maximiza Var sujeito a = 1. II. o i-ésimo componente principal é a combinação linear
que maximiza Var = 1 e Cov (, ) = 0, para k < i. III. sendo
os autovalores e ei os autovetores de S, o i-ésimo componente principal é dado por + , onde i = 1, ··· p. IV. Var
= 0, para i = 1,2, ···, p e i ≠ k. V. a proporção da variância total devido ao k-ésimo componente principal é dada por
para k = 1, ···, p. Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452950
Estatística
“A análise de resíduos de um modelo de regressão linear múltipla pode ser utilizada para verificar se o modelo se adequa aos dados. Nesse sentido, gráficos e testes ajudam a identificar discrepâncias entre os valores observados da variável resposta e os valores preditos pelo modelo.” De acordo com o trecho anterior, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Quando os pontos do diagrama de dispersão do resíduo padronizado versus variável explicativa apresentar uma tendência, a inclusão do logaritmo da variável explicativa pode melhorar o modelo.
( ) Quando os pontos do diagrama de dispersão do resíduo versus variável omitida no modelo apresentar uma tendência linear, a inclusão da variável omitida pode melhorar o modelo.
( ) Quando o desenho esquemático (boxplot) dos resíduos padronizados apresentar observações além dos limites superior ou inferior, existe uma forte indicação da presença de outliers que devem ser investigados.
( ) Quando o desenho esquemático dos resíduos tem a distância entre a mediana e o primeiro quartil e a distância entre a mediana e o terceiro quartil bem distintas, existe uma forte indicação de que a distribuição das observações são assimétricas e o componente aleatório do modelo pode não ter distribuição normal.
( ) A suposição de homocedasticidade dos resíduos pode ser avaliada através de: teste de Levéne; teste de Brown & Forsythe; gráfico de resíduos versus valores preditos pelo modelo; gráfico do resíduo versus cada uma das variáveis incluídas no modelo.
A sequência está correta em
( ) Quando os pontos do diagrama de dispersão do resíduo padronizado versus variável explicativa apresentar uma tendência, a inclusão do logaritmo da variável explicativa pode melhorar o modelo.
( ) Quando os pontos do diagrama de dispersão do resíduo versus variável omitida no modelo apresentar uma tendência linear, a inclusão da variável omitida pode melhorar o modelo.
( ) Quando o desenho esquemático (boxplot) dos resíduos padronizados apresentar observações além dos limites superior ou inferior, existe uma forte indicação da presença de outliers que devem ser investigados.
( ) Quando o desenho esquemático dos resíduos tem a distância entre a mediana e o primeiro quartil e a distância entre a mediana e o terceiro quartil bem distintas, existe uma forte indicação de que a distribuição das observações são assimétricas e o componente aleatório do modelo pode não ter distribuição normal.
( ) A suposição de homocedasticidade dos resíduos pode ser avaliada através de: teste de Levéne; teste de Brown & Forsythe; gráfico de resíduos versus valores preditos pelo modelo; gráfico do resíduo versus cada uma das variáveis incluídas no modelo.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452948
Estatística
Em uma população finita de tamanho N, onde existem k indivíduos com uma característica de interesse, ao se selecionar uma amostra aleatória de tamanho n sem reposição, o número de indivíduos com a característica na amostra (R) é uma variável aleatória com distribuição hipergeométrica. A probabilidade de se ter exatamente r indivíduos na amostra com a característica de interesse é dada por
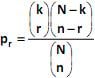 , onde max (0, n – N + k) = r = min (k, n).
, onde max (0, n – N + k) = r = min (k, n).
Analise.
I. Para N = 100, k = 20, n = 10 e r = 3, E(R) = 2 e Var(R) = 144/99.
II. Para N = 100, k = 20, n = 5 e r = 3, E(R) = 1 e Var(R) = 8/10.
III. Para N = 10000, k = 2000, n = 100 e r = 3, E(R) = 20 e Var(R) = 15,84.
IV. Para N = 10000, k = 1000, n = 100 e r = 3, E(R) = 10 e Var(R) ˜ 9.
V. Para N = 10000, k = 2000, n = 10 e r = 0, P(R = 0) ˜ 0,1074.
Estão corretas apenas as alternativas
, onde max (0, n – N + k) = r = min (k, n). Analise.
I. Para N = 100, k = 20, n = 10 e r = 3, E(R) = 2 e Var(R) = 144/99.
II. Para N = 100, k = 20, n = 5 e r = 3, E(R) = 1 e Var(R) = 8/10.
III. Para N = 10000, k = 2000, n = 100 e r = 3, E(R) = 20 e Var(R) = 15,84.
IV. Para N = 10000, k = 1000, n = 100 e r = 3, E(R) = 10 e Var(R) ˜ 9.
V. Para N = 10000, k = 2000, n = 10 e r = 0, P(R = 0) ˜ 0,1074.
Estão corretas apenas as alternativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452947
Estatística
Marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452946
Estatística
Uma série temporal corresponde a um conjunto de observações que são, naturalmente, ordenadas pelo tempo, espaço, profundidade etc., que apresentam dependência em observações vizinhas. As observações correspondem a um processo  , e
, e
I. que pode ser discreto, se T =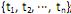 ; contínuo, se T =
; contínuo, se T = 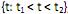 , ou multivariado, se
, ou multivariado, se 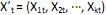 .
.
II. pode ser uma variável discreta ou contínua.
pode ser uma variável discreta ou contínua.
III. os dois principais objetivos da análise de uma série temporal, a saber: compreender o mecanismo gerador e predizer o comportamento gerador e o comportamento futuro.
IV. a tendência é um efeito de longo prazo na média. Sazonalidade é um efeito ligado às variações periódicas. Ciclos são variações periódicas não associadas automaticamente a nenhuma medida temporal.
V. apresenta a família de modelos paramétricos de séries temporais, escrita de tal modo que cada observação corresponde a um sinal mais um ruído não correlacionado.
Estão corretas apenas as afirmativas
, e I. que pode ser discreto, se T =
; contínuo, se T = , ou multivariado, se . II.
pode ser uma variável discreta ou contínua. III. os dois principais objetivos da análise de uma série temporal, a saber: compreender o mecanismo gerador e predizer o comportamento gerador e o comportamento futuro.
IV. a tendência é um efeito de longo prazo na média. Sazonalidade é um efeito ligado às variações periódicas. Ciclos são variações periódicas não associadas automaticamente a nenhuma medida temporal.
V. apresenta a família de modelos paramétricos de séries temporais, escrita de tal modo que cada observação corresponde a um sinal mais um ruído não correlacionado.
Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452945
Estatística
Pesquisadores da área da saúde cardiovascular pretendem descobrir se um tratamento para diminuir o nível de colesterol no sangue sofre influência do gênero do paciente. Para isso, selecionaram um grupo de voluntários de ambos os sexos e coletaram dados sobre as variáveis clínicas relacionadas na tabela abaixo.
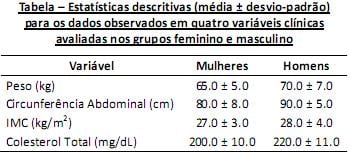
Considerando as estatísticas descritivas (média e desvio- padrão) divulgadas na tabela, analise.
I. As mulheres são mais homogêneas na variável IMC do que na variável Colesterol Total.
II. Os homens são mais homogêneos na variável Peso do que na variável IMC.
III. Tanto para mulheres quanto para homens, a variável com medidas mais heterogêneas é o Colesterol Total.
Está(ão) correta(s) apenas a(s) afirmativa(s)
Considerando as estatísticas descritivas (média e desvio- padrão) divulgadas na tabela, analise.
I. As mulheres são mais homogêneas na variável IMC do que na variável Colesterol Total.
II. Os homens são mais homogêneos na variável Peso do que na variável IMC.
III. Tanto para mulheres quanto para homens, a variável com medidas mais heterogêneas é o Colesterol Total.
Está(ão) correta(s) apenas a(s) afirmativa(s)
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452944
Estatística
A equipe de controle de qualidade de uma indústria metalúrgica suspeita que a produção de peças defeituosas esteja relacionada ao sistema de trabalho dos funcionários: com ou sem troca de turno (trabalho noturno ou diurno). Para um grupo de 180 funcionários com experiência similar na função, mas com sistemas de trabalho diferentes, cada funcionário teve registrado o percentual de peças defeituosas produzidas durante uma semana, sendo classificado como “aceitável”, se esse percentual fosse menor ou igual a 5%, e como “não aceitável”, caso contrário. Entre os 60 funcionários que não trocam turno e trabalham durante o dia, o número de funcionários classificados como “aceitável” foi 47. Entre os 60 funcionários que não trocam turno e trabalham durante a noite, o número de funcionários classificados como “aceitável” foi 40 e, para o grupo de 60 funcionários que trocam turnos, esse número foi 33. A estatística do teste apropriado foi calculada e o seu valor é 7.35. O quadro abaixo apresenta os valores dos percentis de ordem 95 e 97.5 para as distribuições de probabilidade gaussiana, t-Student e Qui-quadrado.
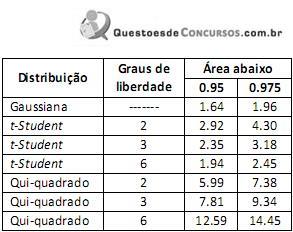
Considerando a descrição do problema e dos dados apre- sentados, analise.
I. A hipótese nula do teste é a de que as proporções de funcionários classificados como “aceitáveis” são homo- gêneas nos três grupos.
II. Se a hipótese nula for verdadeira, o número esperado de funcionários classificados como “aceitáveis” seria 40 em cada um dos três grupos.
III. A hipótese nula do teste pode ser rejeitada no nível de significância de 5%.
Está(ão) correta(s) a(s) afirmativa(s)
Considerando a descrição do problema e dos dados apre- sentados, analise.
I. A hipótese nula do teste é a de que as proporções de funcionários classificados como “aceitáveis” são homo- gêneas nos três grupos.
II. Se a hipótese nula for verdadeira, o número esperado de funcionários classificados como “aceitáveis” seria 40 em cada um dos três grupos.
III. A hipótese nula do teste pode ser rejeitada no nível de significância de 5%.
Está(ão) correta(s) a(s) afirmativa(s)
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452943
Estatística
O efeito de uma campanha publicitária para promoção do voluntariado nas eleições será avaliado por meio do seguinte experimento: antes do início da campanha, um grupo de 200 eleitores responderá à seguinte questão: “você gostaria de ser voluntário nas próximas eleições? (sim ou não)”. A campanha será lançada e, após três meses de veiculação em rádio e TV, o mesmo grupo de eleitores responderá à mesma questão. A campanha será reforçada com publicidade em outdoors nos próximos três meses e, após esse período, o mesmo grupo de eleitores responderá novamente à mesma questão. A equipe responsável pelo estudo deseja comparar o percentual de eleitores que desejam ser voluntários nas próximas eleições em cada etapa. Considerando o planejamento do experimento e o
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452942
Estatística
Para um conjunto de dados, utilizou-se um programa de computador para calcular o valor das médias aritméticas simples, harmônica e geométrica. No entanto, os valores resultantes dos cálculos foram impressos sem qualquer identificação sobre a qual medida-resumo eles se referiam. Os valores impressos foram 2.63, 2.46 e 2.25. Conhecendo as propriedades dessas medidas-resumo, é correto afirmar que os valores da média aritmética simples, harmônica e geométrica são, respectivamente,
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452941
Estatística
Os gastos mensais com merenda escolar de 200 municípios foram resumidos, chegando-se aos valores da média (aritmética simples), da mediana e do coeficiente de variação. Esses valores são, respectivamente, 50 mil reais, 60 mil reais e 0,20. No entanto, para fazer parte de um relatório para uma organização internacional, todos os valores monetários devem ser expressos em dólares. Na cotação oficial, um dólar vale 2 reais. Sendo assim, os valores da média, mediana e coeficiente de variação dos gastos mensais dos 200 municípios são, respectivamente,
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452940
Estatística
Um grupo de 100 alunos, sendo 50 meninos e 50 meninas, todos da mesma faixa etária e cursando o mesmo ano escolar, responderam a um questionário sobre métodos anticoncepcionais. O objetivo do estudo era verificar se a proporção de alunos com conhecimento adequado sobre anticoncepção é homogênea nos dois gêneros. Para ter um conhecimento considerado adequado, o aluno deveria acertar todas as questões. Ao final da correção de cada questionário, registrava-se o acerto ou não das perguntas. Os resultados foram resumidos e apresentados na tabela a seguir.
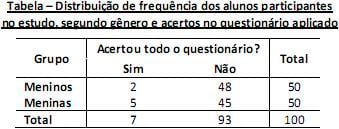
Considerando o desenho do estudo, o tipo de variável observada e os dados obtidos, o teste estatístico mais adequado para avaliar a hipótese de estudo é o
Considerando o desenho do estudo, o tipo de variável observada e os dados obtidos, o teste estatístico mais adequado para avaliar a hipótese de estudo é o
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452939
Estatística
Um analista dispõe dos valores da média aritmética simples, da mediana e do desvio-padrão da idade de dois grupos de 100 eleitores, um do sexo feminino e outro do sexo masculino. Para o grupo feminino, os valores são: média igual a 56 anos, mediana igual a 52 anos e desvio- padrão igual a 5 anos. Para o grupo do sexo masculino, os valores são: média igual a 60 anos, mediana igual a 58 anos e desvio-padrão igual a 7 anos. O analista gostaria de conhecer as estatísticas descritivas para a idade no grupo total de 200 eleitores, mas só dispõe das estatísticas separadas por sexo, cujos valores são os mencionados anteriormente. Sobre o problema citado anteriormente, analise as afirmativas.
I. A média da idade do grupo total de eleitores pode ser obtida a partir das médias de idades dos grupos separados por sexo e o seu valor é 58 anos.
II. O desvio-padrão da idade do grupo total de eleitores pode ser obtido a partir dos desvios-padrão das idades dos grupos separados por sexo e o seu valor é 6 anos.
III. A mediana da idade do grupo total de eleitores pode ser obtida a partir das medianas das idades dos grupos separados por sexo e o seu valor é 55 anos.
Está(ão) correta(s) a(s) afirmativa(s)
I. A média da idade do grupo total de eleitores pode ser obtida a partir das médias de idades dos grupos separados por sexo e o seu valor é 58 anos.
II. O desvio-padrão da idade do grupo total de eleitores pode ser obtido a partir dos desvios-padrão das idades dos grupos separados por sexo e o seu valor é 6 anos.
III. A mediana da idade do grupo total de eleitores pode ser obtida a partir das medianas das idades dos grupos separados por sexo e o seu valor é 55 anos.
Está(ão) correta(s) a(s) afirmativa(s)