Questões de Concurso
Foram encontradas 10.049 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Julgue o item a seguir, considerando o par de variáveis aleatórias contínuas (U,V), cuja função de densidade conjunta é dada por f(u,v) = 12/11 (u2 + uv + v2), em que c é uma constante positiva, 0 < u < 1 e 0 < v < 1, e u e v representam, respectivamente, os suportes de U e V.
A função de densidade de probabilidade de U, para
0< u < 1, é f(u) = 12u2 + 6u + 4/11.
Julgue o item a seguir, considerando o par de variáveis aleatórias contínuas (U,V), cuja função de densidade conjunta é dada por f(u,v) = 12/11 (u2 + uv + v2), em que c é uma constante positiva, 0 < u < 1 e 0 < v < 1, e u e v representam, respectivamente, os suportes de U e V.
Os valores esperados de U e de V são iguais a 7/11.
Julgue o item a seguir, considerando o par de variáveis aleatórias contínuas (U,V), cuja função de densidade conjunta é dada por f(u,v) = 12/11 (u2 + uv + v2), em que c é uma constante positiva, 0 < u < 1 e 0 < v < 1, e u e v representam, respectivamente, os suportes de U e V.
A variância de V é igual ou superior a 0,1.
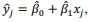 tem-se:
tem-se: 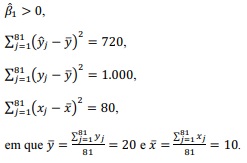
Com base nessas informações, julgue o seguinte item.
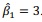
tem-se: Com base nessas informações, julgue o seguinte item.
A estimativa de δ2 é igual ou inferior a 3,5.
tem-se: Com base nessas informações, julgue o seguinte item.
A estimativa da variância de 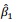 é igual ou superior a 0,05.
é igual ou superior a 0,05.
Considerando o modelo clássico de regressão linear e a importância das suas hipóteses no contexto de uso intensivo de dados, julgue o item a seguir.
Na presença de heterocedasticidade, os valores da
estatística t são maiores que o esperado.
Considerando o modelo clássico de regressão linear e a importância das suas hipóteses no contexto de uso intensivo de dados, julgue o item a seguir.
Quando se adicionam variáveis explicativas ao modelo,
espera-se redução da estatística R2
.
Considerando o modelo clássico de regressão linear e a importância das suas hipóteses no contexto de uso intensivo de dados, julgue o item a seguir.
Na presença de multicolinearidade perfeita, os estimadores
de mínimos quadrados ordinários não são únicos.
Considerando o modelo clássico de regressão linear e a importância das suas hipóteses no contexto de uso intensivo de dados, julgue o item a seguir.
Havendo heterocedasticidade, os estimadores de mínimos
quadrados ordinários serão ineficientes.
Acerca da avaliação de modelos de classificação, julgue o item que se segue.
A matriz de confusão, em problemas de classificação
multiclasses, é uma tabela com duas linhas e duas colunas;
na diagonal principal dessa matriz quadrada, estão os valores
corretos e, na matriz secundária, os erros cometidos pelo
modelo.
Julgue o próximo item, relativo a Naive Bayes e random forest.
Nas árvores de decisão e em random forest, são utilizadas
técnicas estatísticas com o objetivo de se produzir, a partir de
um conjunto de observações, uma predição de valores em
função de uma ou mais variáveis independentes contínuas
e(ou) binárias.
Julgue o próximo item, relativo a Naive Bayes e random forest.
O algoritmo de classificação Naive Bayes pode ser utilizado
para o cálculo da probabilidade de ocorrência de um evento,
com base em probabilidades obtidas em eventos numéricos
passados, e, por isso, não pode ser empregado em atividades
de classificação textual.
Julgue o próximo item, relativo a Naive Bayes e random forest.
Random forest é um algoritmo de classificação que permite a
realização de mineração dos dados por meio da criação de
estruturas de aprendizagem a partir de uma base de dados na
qual se utiliza uma única árvore de decisão para a
classificação dos dados.
Julgue o próximo item, relativo a Naive Bayes e random forest.
Naive Bayes é um algoritmo de classificação baseado na
aprendizagem por reforço, em que um agente realiza uma
ação e recebe uma recompensa de acordo com o resultado
dessa ação por meio da implementação do teorema de Bayes,
com o objetivo de encontrar a probabilidade a posteriori.
Julgue o próximo item, relativo a Naive Bayes e random forest.
Tamanho do nó, número de árvores e número de recursos
amostrados, ou número de preditores amostrados, são
parâmetros de algoritmos random forest.
No que diz respeito ao estimador hipotético Tn do parâmetro λ, julgue o seguinte item.
Tn é estimador consistente.
No que diz respeito ao estimador hipotético Tn do parâmetro λ, julgue o seguinte item.
O erro-padrão de Tn é igual a 1.
No que diz respeito ao estimador hipotético Tn do parâmetro λ, julgue o seguinte item.
Tn é estimador de λ assintoticamente não viciado.
No que diz respeito ao estimador hipotético Tn do parâmetro λ, julgue o seguinte item.
Se Tn seguir uma distribuição normal, então a razão nTn -(n+2)λ /√nλ será normal padrão.