Questões de Concurso
Comentadas para auditor interno (controladoria)
Foram encontradas 156 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387555
Programação
Sobre o conceito de abstração em POO, analise as afirmativas a
seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) O processo de abstração pode ser visto como a aplicação de um mapeamento muitos para um, o que permite esquecer informações redundantes e se concentrar nos atributos essenciais para entender o problema.
( ) Na abstração por parametrização, a identidade dos dados utilizados é abstraída. A abstração é caracterizada por parâmetros formais; quando a abstração é aplicada, os dados reais são associados a esses parâmetros formais.
( ) A abstração por especificação permite mudar para outra implementação, afetando levemente o significado de qualquer programa que utilize a abstração.
As afirmativas são, respectivamente,
( ) O processo de abstração pode ser visto como a aplicação de um mapeamento muitos para um, o que permite esquecer informações redundantes e se concentrar nos atributos essenciais para entender o problema.
( ) Na abstração por parametrização, a identidade dos dados utilizados é abstraída. A abstração é caracterizada por parâmetros formais; quando a abstração é aplicada, os dados reais são associados a esses parâmetros formais.
( ) A abstração por especificação permite mudar para outra implementação, afetando levemente o significado de qualquer programa que utilize a abstração.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387554
Arquitetura de Software
Padrões de projeto são soluções consagradas que se baseiam nas
estruturas da orientação a objetos para solucionar problemas
comuns em projetos de software. Os padrões são agrupados em
tipos.
Assinale a opção que indica apenas padrões do tipo comportamental.
Assinale a opção que indica apenas padrões do tipo comportamental.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387553
Engenharia de Software
Os benefícios da introdução do Behavior-Driven Development
(BDD) em uma organização são significativos, ainda que sua
implementação nem sempre ocorra sem dificuldades.
Com relação aos desafios da introdução do BDD, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
I. O BDD requer um alto envolvimento e colaboração empresarial. As práticas de BDD são baseadas em conversas e feedback dos usuários, que impulsionam e constroem a compreensão da equipe sobre os requisitos e sobre como eles podem agregar valor ao negócio com base nesses requisitos.
II. O BDD funciona melhor com a adoção de metodologias ágeis ou iterativa. As práticas de análise de requisitos do BDD mostram que é difícil, se não impossível, definir completamente os requisitos de modo antecipado, e que estes evoluirão à medida que a equipe aprenda mais sobre o projeto.
III. Os testes, mesmo que mal escritos, não ocasionam custos de manutenção elevados. A criação de testes automatizados, especialmente para aplicações web complexas, requer baixa habilidade, e as equipes que estão começando a adotar o BDD não consideram isso um desafio significativo.
As afirmativas são, respectivamente,
Com relação aos desafios da introdução do BDD, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
I. O BDD requer um alto envolvimento e colaboração empresarial. As práticas de BDD são baseadas em conversas e feedback dos usuários, que impulsionam e constroem a compreensão da equipe sobre os requisitos e sobre como eles podem agregar valor ao negócio com base nesses requisitos.
II. O BDD funciona melhor com a adoção de metodologias ágeis ou iterativa. As práticas de análise de requisitos do BDD mostram que é difícil, se não impossível, definir completamente os requisitos de modo antecipado, e que estes evoluirão à medida que a equipe aprenda mais sobre o projeto.
III. Os testes, mesmo que mal escritos, não ocasionam custos de manutenção elevados. A criação de testes automatizados, especialmente para aplicações web complexas, requer baixa habilidade, e as equipes que estão começando a adotar o BDD não consideram isso um desafio significativo.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387552
Arquitetura de Software
Assinale a opção que indica as vantagens que a adoção das
arquiteturas do tipo hexagonal apresenta para o
desenvolvimento de aplicações Java.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387541
Direito Penal
Sobre o dolo e a culpa na teoria do crime, assinale a afirmativa
correta.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387540
Direito Penal
Quanto ao conflito aparente de normas penais, analise as
disposições a seguir.
I. O princípio da especialidade determina que o tipo penal específico prevalece sobre o tipo penal de caráter geral.
II. O princípio da consunção implica na absorção de um delito por outro, não sendo aplicável aos casos de crime progressivo, crime complexo, progressão criminosa, fato posterior não punível e fato anterior não punível.
III. Os requisitos do conflito aparente de normas são os seguintes: pluralidade de condutas, relevância causal das condutas e liame subjetivo entre os agentes.
Está correto o que se afirma em
I. O princípio da especialidade determina que o tipo penal específico prevalece sobre o tipo penal de caráter geral.
II. O princípio da consunção implica na absorção de um delito por outro, não sendo aplicável aos casos de crime progressivo, crime complexo, progressão criminosa, fato posterior não punível e fato anterior não punível.
III. Os requisitos do conflito aparente de normas são os seguintes: pluralidade de condutas, relevância causal das condutas e liame subjetivo entre os agentes.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387537
Direito Penal
Sobre os crimes contra a ordem tributária (Lei nº 8.137/1990),
assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387529
Direito Administrativo
José é servidor público estável de certo ente federativo e, após o
respectivo processo administrativo disciplinar, foi demitido, em
decorrência da prática de falta funcional grave, punível com a
aludida sanção nos termos do respectivo estatuto.
Inconformado com a mencionada penalidade, José ajuizou ação com vistas a obter a sua anulação sob o fundamento de que houve excesso de prazo para a conclusão do processo administrativo disciplinar. Eventualmente, pleiteou aplicação de sanção mais branda, diante da possibilidade de o Poder Judiciário substituir a Administração na aplicação da penalidade, em decorrência de seu prévio histórico funcional.
Considerando as alegações formuladas por José, à luz do entendimento consolidado pelo Superior Tribunal de Justiça, assinale a afirmativa correta.
Inconformado com a mencionada penalidade, José ajuizou ação com vistas a obter a sua anulação sob o fundamento de que houve excesso de prazo para a conclusão do processo administrativo disciplinar. Eventualmente, pleiteou aplicação de sanção mais branda, diante da possibilidade de o Poder Judiciário substituir a Administração na aplicação da penalidade, em decorrência de seu prévio histórico funcional.
Considerando as alegações formuladas por José, à luz do entendimento consolidado pelo Superior Tribunal de Justiça, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387522
Direito Administrativo
No exercício de suas atribuições como agente da licitação,
Rosângela foi questionada acerca dos princípios elencados na
Lei nº 14.133/2021, bem como quanto aos objetivos do
procedimento licitatório, na forma do mencionado Diploma
Legal.
Diante de tal questionamento, Rosângela respondeu corretamente, que
Diante de tal questionamento, Rosângela respondeu corretamente, que
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387517
Direito Administrativo
Caso o Município de Belo Horizonte deseje realizar a locação de
um bem imóvel para o funcionamento de determinado órgão
administrativo que realizará atendimento ao público, a fim de
melhor atender às necessidades da coletividade, à luz do disposto
na Lei nº 14.133/2021, é correto afirmar que
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Direito - Manhã |
Q2387516
Direito Penal
No exercício de suas atribuições como Auditor de Controle
Interno do Município de Belo Horizonte, Bruno verificou que o
servidor Nelson praticou conduta tipificada como crime de abuso
de autoridade, nos termos da Lei nº 13.869/2019. Em razão
disso, há, em curso, um processo administrativo-disciplinar e uma
ação criminal para fins de responsabilização em decorrência do
mesmo fato.
Com relação à viabilidade de a sentença penal na situação descrita fazer coisa julgada na esfera administrativo-disciplinar, nos termos do mencionado Diploma Legal, assinale a afirmativa correta.
Com relação à viabilidade de a sentença penal na situação descrita fazer coisa julgada na esfera administrativo-disciplinar, nos termos do mencionado Diploma Legal, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366050
Administração Geral
Marcelo, atuando como gestor de processos de uma organização, adotou uma abordagem metódica diante dos problemas encontrados. Primeiro, ele realiza uma análise preliminar para avaliar o potencial impacto do problema na organização. Em seguida, ele considera o prazo disponível para sua possível resolução. Por fim, Marcelo analisa o padrão de evolução do problema, visando a entender sua trajetória. Só então, após essas avaliações, Marcelo decide o que fazer.
Assinale a opção que indica a ferramenta de gestão de qualidade que possui correlação com a análise realizada por Marcelo.
Assinale a opção que indica a ferramenta de gestão de qualidade que possui correlação com a análise realizada por Marcelo.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366049
Banco de Dados
Graças ao avanço tecnológico, a capacidade de armazenamento e produção de dados digitais cresceu de forma exponencial, alcançado níveis que superam significativamente as expectativas da sociedade de alguns anos atrás. Esses conjuntos de dados, que por sua grandeza e complexidade demandam nova técnicas e tecnologias para o seu processamento, são conhecidos como Big Data.
Sobre as características do Big Data, analise os itens a seguir.
I. Veracidade.
II. Valor.
III. Validade.
Está correto o que se afirma em
Sobre as características do Big Data, analise os itens a seguir.
I. Veracidade.
II. Valor.
III. Validade.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366046
Gerência de Projetos
O conceito de tailoring, abordado em profundidade na versão PMBOK (7ª ed.), entende que é necessário
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366045
Gerência de Projetos
No gerenciamento de projetos, de acordo com o PMBOK, as áreas de conhecimento são definidas como conjuntos específicos de atividades que possuem determinados conhecimentos comuns como requisitos. Paralelamente, os grupos de processos são classificados em categorias lógicas de atividades que percorrem as diferentes fases do ciclo de vida de um projeto, incluindo processos de iniciação, planejamento, execução, monitoramento e controle, além de encerramento.
Com base nesse entendimento, assinale a opção que indica a área de conhecimento que se destaca pela sua abrangência, envolvendo atividades presentes em todos os grupos de processos.
Com base nesse entendimento, assinale a opção que indica a área de conhecimento que se destaca pela sua abrangência, envolvendo atividades presentes em todos os grupos de processos.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366044
Administração Geral
A respeito dos conceitos sobre as técnicas de tomada de decisão, analise as afirmativas a seguir.
I. A abordagem que utiliza a técnica de Grupo Nominal favorece a igualdade de participação entre os integrantes.
II. A técnica Delphi prioriza a participação de pessoas com pouco conhecimento sobre o assunto debatido, com o intuito de promover ideias inovadoras.
III. O método da Árvore de Decisão se baseia no conceito de dúvida sistemática, criando um ambiente propício para decisões não estruturadas.
Está correto o que se afirma em
I. A abordagem que utiliza a técnica de Grupo Nominal favorece a igualdade de participação entre os integrantes.
II. A técnica Delphi prioriza a participação de pessoas com pouco conhecimento sobre o assunto debatido, com o intuito de promover ideias inovadoras.
III. O método da Árvore de Decisão se baseia no conceito de dúvida sistemática, criando um ambiente propício para decisões não estruturadas.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366043
Gerência de Projetos
Os Escritórios de Gerenciamento de Projetos (EGPs), estruturas fundamentais nas organizações, foram instituídos com o objetivo de facilitar o gerenciamento eficaz de projetos. Conforme previsto no Guia PMBOK (6ª ed.), principal referencial da área, essas estruturas podem ser de diferentes tipos, variando conforme o papel designado pela organização, em função de suas necessidades.
Com relação aos tipos possíveis de escritórios de projetos e respectivas atribuições, assinale a afirmativa correta.
Com relação aos tipos possíveis de escritórios de projetos e respectivas atribuições, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366042
Gerência de Projetos
Analise o gráfico a seguir, retirado do Guia PMBOK, representando o ciclo de vida genérico de um projeto.
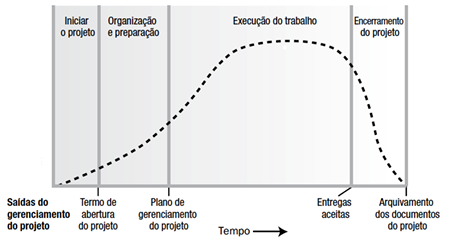
A linha pontilhada do gráfico, que percorre todas as fases do ciclo de vida do projeto, representa
A linha pontilhada do gráfico, que percorre todas as fases do ciclo de vida do projeto, representa
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366041
Gerência de Projetos
Acerca de situações que representam projetos, analise as afirmativas a seguir.
I. O desenvolvimento de uma nova vacina contra a dengue, para o mercado.
II. O atendimento diário dos contribuintes realizado por servidores públicos.
III. A construção de um edifício para abrigar os servidores de um órgão público.
Está correto o que se afirma em
I. O desenvolvimento de uma nova vacina contra a dengue, para o mercado.
II. O atendimento diário dos contribuintes realizado por servidores públicos.
III. A construção de um edifício para abrigar os servidores de um órgão público.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Administração - Manhã |
Q2366040
Administração Geral
A implementação da ferramenta Seis Sigma para o gerenciamento da qualidade dos produtos produzidos em uma fábrica visa a