Questões de Concurso
Comentadas para especialista em regulação
Foram encontradas 640 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
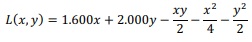
A partir dessas informações, julgue o próximo item, de acordo com o modelo apresentado.
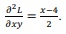
Acerca dos modelos econométricos de séries temporais, julgue o item seguinte.
Se houver autocorrelação dos resíduos, os estimadores de
mínimos quadrados ordinários serão ineficientes, viesados e
inconsistentes.
Acerca do fluxo de Big Data, julgue o item que se segue.
Na etapa de captura de Big Data, grandes volumes de dados
são armazenados em bancos de dados NoSQL, devido à sua
escalabilidade e à sua flexibilidade.
Acerca do fluxo de Big Data, julgue o item que se segue.
As funções do MapReduce transformam um volume grande
de dados em grupamentos segmentados, mantendo na saída
a mesma quantidade de dados da entrada.
Acerca do fluxo de Big Data, julgue o item que se segue.
O serviço ElasticSearch utiliza índices divididos em
fragmentos, de maneira que cada nó armazena diversos
fragmentos e atua na coordenação das operações nos vários
fragmentos.
Acerca do fluxo de Big Data, julgue o item que se segue.
Streaming processing é uma tecnologia de Big Data
exclusiva para atender processamentos de serviços de
streaming de áudio e vídeo.
Acerca do fluxo de Big Data, julgue o item que se segue.
Na apresentação de dados, a extração de subcoleções e a
consulta de parâmetros permitem a navegação em diversos
cenários da visualização.
A respeito de Big Data, julgue o próximo item.
No processamento ROLAP, bancos de dados relacionais são
utilizados como local de armazenamento para agregação,
enquanto, nos processamentos MOLAP e HOLAP,
utilizam-se bancos de dados multidimensionais.
A respeito de Big Data, julgue o próximo item.
O processo de ELT, devido às suas etapas, exige maior definição
de regras, estruturas e relações do que a abordagem ETL.
A respeito de Big Data, julgue o próximo item.
Subconjunto de um data warehouse, o data mart é
especializado em uma área específica de uma organização.
A respeito de Big Data, julgue o próximo item.
Em um data lake, os dados são depositados em estado bruto,
sem terem passado por qualquer análise e mesmo sem terem
uma governança.
A respeito de Big Data, julgue o próximo item.
No modelo SaaS (software as a service) da computação em
nuvem utilizado para Big Data, a aplicação e os dados são
gerenciados pelo provedor da nuvem.
A respeito de Big Data, julgue o próximo item.
O YARN (Yet Another Resource Negotiator) é um sistema
de arquivos distribuídos que faz parte do framework Hadoop.
A respeito de Big Data, julgue o próximo item.
A coleta de dados por meio de aplicativos é considerada
explícita, porque o usuário a autoriza.
A respeito de Big Data, julgue o próximo item.
Em Big Data, ruídos consistem em informações extras que
acabam deturpando as análises, enquanto overfitting designa
a interpretação equivocada dos ruídos como dados legítimos.
A respeito de Big Data, julgue o próximo item.
Pipelines de dados apresentam uma única estrutura para o
recebimento dos dados originados de uma fonte não
confiável.
Julgue o próximo item, referente ao processamento de linguagem natural.
Na redução de palavras ao radical, ocorre under-stemming
quando duas palavras separadas são reduzidas erroneamente
à mesma raiz e, com isso, ocorre a perda de distinção
semântica entre palavras com significados diferentes.
Julgue o próximo item, referente ao processamento de linguagem natural.
A lematização prescinde do POS tagging para que as
palavras sejam reduzidas corretamente, pois todas as
palavras são reduzidas ao mesmo lemma, independentemente
de sua classe gramatical.
Julgue o próximo item, referente ao processamento de linguagem natural.
A similaridade de cosseno é uma métrica pela qual se avalia
a similaridade entre dois vetores com base no ângulo entre
eles em um espaço vetorial, de forma que, à medida que os
vetores se aproximarem, aumentará a similaridade de
cosseno.
A respeito de técnicas de redução de dimensionalidade, julgue o item subsecutivo.
Para utilizar de forma adequada a análise de componentes
principais (PCA, na sigla em inglês), é essencial normalizar
os dados; se as variáveis não estiverem na mesma escala,
aquelas com maior variância terão maior impacto,
distorcendo o resultado da PCA.