Questões de Concurso
Comentadas para analista (superior)
Foram encontradas 9.595 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517650
Banco de Dados
Os Sistemas Gerenciadores de Banco de Dados (SGBD) comerciais
implementam internamente técnicas para processar, otimizar e
executar consultas de alto nível.
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517649
Banco de Dados
As transações em banco de dados possuem propriedades que
buscam proteger dados contra perdas ou danos.
A propriedade durabilidade tem relação com:
A propriedade durabilidade tem relação com:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517647
Banco de Dados
Observe o Modelo de Entidades e Relacionamentos a seguir.
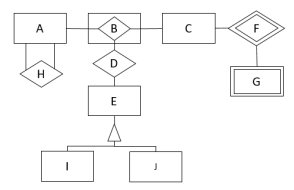
Com base nos relacionamentos apresentados, está explícito que:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517646
Banco de Dados
Documentos do Jupyter Notebook são salvos com a extensão
.ipynb, mas internamente eles são documentos do tipo:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517645
Programação
Igor, analista de dados da CVM, escreveu e rodou o código a
seguir.
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi:
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517643
Engenharia de Software
No método tensorflow.keras.layers.Dense(...), se nenhuma
função de ativação é especificada, é utilizada por padrão a
função:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517642
Programação
Considere o código python a seguir.
import spacy
nlp = spacy.load("pt_core_news_lg")
doc = nlp("O rato roeu a roupa do rei de Roma")
print(doc[2].pos_, doc[2].dep_)
Os valores exibidos pela última linha são:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517641
Banco de Dados
Uma certa organização gostaria de compartilhar dados com um
grupo de pesquisadores de uma universidade para a condução de
um estudo sobre problemas ergonômicos nos seus escritórios.
Entre os dados coletados, há informações sensíveis sobre seus
funcionários; portanto, o responsável pela coleta decidiu
anonimizar os dados. Isso foi feito removendo-se nomes e outros
campos identificadores e adicionando-se um número
identificador próprio a cada funcionário. Dessa forma, a
identidade dos funcionários seria preservada. Após a verificação
de uma amostra, o pesquisador responsável pelo estudo
recomendou medidas que deveriam ser aplicadas antes que os
dados pudessem ser aceitos para o estudo.
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517639
Programação
Um dos principais fatores que tornam viável a aplicação de
modelos grandes de linguagem (LLMs) é o controle do espaço de
probabilidade de tokens através da redução de dimensionalidade
do vocabulário, sem perda da capacidade de reconstruir qualquer
token válido da linguagem sendo modelada.
Considerando esse objetivo, dois algoritmos que podem ser utilizados para esse fim são:
Considerando esse objetivo, dois algoritmos que podem ser utilizados para esse fim são:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517637
Banco de Dados
Ao receber um conjunto de dados para elaborar um modelo
preditivo, uma equipe de analistas de dados percebeu que havia
uma quantidade significativa de dados faltantes em certos
atributos. Foi então debatido o uso de duas técnicas para lidar
com esse problema: (1) remoção de observações contendo dados
ausentes e (2) “inputação” multivariável, sendo que apenas uma
das duas seria aplicada.
Duas características do conjunto de dados que devem ser prioritariamente consideradas na escolha entre as duas técnicas são:
Duas características do conjunto de dados que devem ser prioritariamente consideradas na escolha entre as duas técnicas são:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517636
Banco de Dados
Para ser utilizado em um modelo neural de regressão, um
conjunto de dados precisa ser tratado de tal forma que todos os
atributos de entrada sejam representados como um ou mais
valores numéricos no intervalo [0, 1].
Os atributos de uma observação são: idade (inteiro >= 18), escolaridade (fundamental, médio, superior, pós-graduação), estado de residência (Acre, Alagoas, …, Tocantins, incluindo Distrito Federal) e local de trabalho (empresa, home office, misto).
O número mínimo de valores necessários para representar uma observação com os atributos acima descritos para o modelo de regressão, de forma que não ocorra perda de informação ordinal nem inserção de vieses nos dados, é:
Os atributos de uma observação são: idade (inteiro >= 18), escolaridade (fundamental, médio, superior, pós-graduação), estado de residência (Acre, Alagoas, …, Tocantins, incluindo Distrito Federal) e local de trabalho (empresa, home office, misto).
O número mínimo de valores necessários para representar uma observação com os atributos acima descritos para o modelo de regressão, de forma que não ocorra perda de informação ordinal nem inserção de vieses nos dados, é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517635
Banco de Dados
Visando a maximizar a eficiência de uma equipe de auditores
fiscais, um sistema de classificação de documentação foi
encomendado à equipe de ciência de dados, com o objetivo de
decidir, com base nos documentos obtidos durante uma
fiscalização, se um exame detalhado de documentação é ou não
necessário.
Idealmente, o sistema permitiria aos auditores direcionar mais tempo às auditorias complexas e agilizar a análise dos casos mais simples, otimizando o custo de pessoal e equipamento especializado. Contudo, não examinar detalhadamente um caso complexo pode custar muito caro ao governo, a ponto de anular quaisquer ganhos obtidos usando o sistema com um pequeno número de erros.
Considerando esse cenário, e o fato de o sistema de classificação responder apenas “sim” ou “não” quanto à necessidade de exame detalhado, a métrica de classificação a ser maximizada pela equipe que irá implementar o sistema é:
Idealmente, o sistema permitiria aos auditores direcionar mais tempo às auditorias complexas e agilizar a análise dos casos mais simples, otimizando o custo de pessoal e equipamento especializado. Contudo, não examinar detalhadamente um caso complexo pode custar muito caro ao governo, a ponto de anular quaisquer ganhos obtidos usando o sistema com um pequeno número de erros.
Considerando esse cenário, e o fato de o sistema de classificação responder apenas “sim” ou “não” quanto à necessidade de exame detalhado, a métrica de classificação a ser maximizada pela equipe que irá implementar o sistema é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517634
Banco de Dados
Uma equipe de analistas de dados preparou um modelo preditivo
cuja entrada consiste em planilhas contendo uma matriz de
valores reais entre 1 e 10. Tais planilhas são obtidas de um
sistema externo à equipe. O modelo foi treinado com um
conjunto de planilhas que foi coletado pelos analistas, de forma a
obter uma amostra representativa dos dados a serem utilizados.
A média e o desvio padrão de duas colunas importantes foram
calculados do conjunto de treinamento, como uma forma simples
de verificar a consistência da distribuição dos dados, sendo seus
valores 4,89 e 3,08, respectivamente. O modelo obteve bons
resultados durante sua etapa de testes, com uma precisão de
94%.
Ao iniciar a operação do modelo com planilhas atuais, entretanto, os analistas observaram que o modelo teve um desempenho muito inferior, com precisão de apenas 72%. Investigando as planilhas recebidas, obtiveram a média e o desvio padrão para as duas colunas importantes com valores 5,34 e 3,68, respectivamente.
A explicação mais adequada à situação descrita é:
Ao iniciar a operação do modelo com planilhas atuais, entretanto, os analistas observaram que o modelo teve um desempenho muito inferior, com precisão de apenas 72%. Investigando as planilhas recebidas, obtiveram a média e o desvio padrão para as duas colunas importantes com valores 5,34 e 3,68, respectivamente.
A explicação mais adequada à situação descrita é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517633
Algoritmos e Estrutura de Dados
Uma certa organização busca melhorar a qualidade e agilidade do
seu atendimento eletrônico. Para isso um projeto foi criado para
agrupar os e-mails recebidos de acordo com o tipo de problema a
ser resolvido e assim repassá-los para o setor mais apropriado.
A equipe responsável pela implementação do projeto resolveu utilizar um modelo de linguagem recente para representar o máximo possível de informação contida num e-mail em um vetor de dimensão 768. Entretanto, depararam-se com o seguinte problema: as distâncias entre os vetores se mostraram muito pequenas, tornando o agrupamento por diversos algoritmos muito pouco significativo.
Com esse último problema em mente, a sequência mais apropriada de algoritmos a ser aplicada sobre os vetores, de forma a obter um agrupamento significativo dos e-mails, é:
A equipe responsável pela implementação do projeto resolveu utilizar um modelo de linguagem recente para representar o máximo possível de informação contida num e-mail em um vetor de dimensão 768. Entretanto, depararam-se com o seguinte problema: as distâncias entre os vetores se mostraram muito pequenas, tornando o agrupamento por diversos algoritmos muito pouco significativo.
Com esse último problema em mente, a sequência mais apropriada de algoritmos a ser aplicada sobre os vetores, de forma a obter um agrupamento significativo dos e-mails, é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517632
Banco de Dados
Flávia, responsável pelo setor de análise de dados de uma rede
de concessionárias de carros, está realizando o pré-processamento dos dados dos clientes da rede. Entre os atributos
do conjunto de dados, estão os CPFs dos clientes, o seu sexo e a
quantidade de carros que eles já compraram na rede.
Esses três atributos podem ser classificados, respectivamente, como:
Esses três atributos podem ser classificados, respectivamente, como:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517631
Estatística
Alexandre recebe a tarefa de treinar um sistema de detecção de
fraudes no banco em que trabalha. Para isso, ele testa cinco
modelos, M1, M2, M3, M4 e M5, que possuem, respectivamente,
2, 2, 2, 3 e 3 parâmetros. Alexandre realiza uma seleção
bayesiana dos modelos, usando o critério de informação
bayesiano.
Sabendo que o tamanho da amostra é 200 e que os valores maximizados das funções de verossimilhança dos modelos são 0,3; 0,4; 0,5; 0,3 e 0,5, respectivamente, Alexandre seleciona o modelo:
(se necessário, use ln(2) = 0,7; ln(3) = 1,1 e ln(5) = 1,6)
Sabendo que o tamanho da amostra é 200 e que os valores maximizados das funções de verossimilhança dos modelos são 0,3; 0,4; 0,5; 0,3 e 0,5, respectivamente, Alexandre seleciona o modelo:
(se necessário, use ln(2) = 0,7; ln(3) = 1,1 e ln(5) = 1,6)
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517630
Banco de Dados
Texto associado
Texto 1
Aline, cientista de dados da CVM, foi designada para aferir a
reação à prova da CVM entre os usuários de uma rede social de
textos curtos usando técnicas de análise de sentimentos. Para
isso, ela realiza um processo de KDD. Nesse processo, Aline opta
por representar os textos obtidos da rede social no formato de
vetores reais de baixa dimensionalidade, calculados a partir das
representações das palavras obtidas de um modelo de
linguagem pré-treinado utilizando a técnica word2vec.
Considerando o texto 1, a fase do KDD em que Aline gera os
vetores a partir dos textos é chamada de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517629
Programação
Texto associado
Texto 1
Aline, cientista de dados da CVM, foi designada para aferir a
reação à prova da CVM entre os usuários de uma rede social de
textos curtos usando técnicas de análise de sentimentos. Para
isso, ela realiza um processo de KDD. Nesse processo, Aline opta
por representar os textos obtidos da rede social no formato de
vetores reais de baixa dimensionalidade, calculados a partir das
representações das palavras obtidas de um modelo de
linguagem pré-treinado utilizando a técnica word2vec.
Considerando o texto 1, a representação das palavras que será
utilizada por Aline é chamada de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517628
Banco de Dados
As informações são a base de toda tomada de decisão e gestão
de empresas, sendo um diferencial importante o uso de grandes
volumes de dados de diversas fontes.
Nesse contexto, as soluções de Big Data para análise de dados devem ter a capacidade de:
Nesse contexto, as soluções de Big Data para análise de dados devem ter a capacidade de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517626
Sistemas Operacionais
O cientista de dados Miguel decidiu buscar um serviço de nuvem
que forneça recursos de computação sob demanda, tais como
servidores, rede, armazenamento e outros, para construir seu
ambiente de análise e exploração de dados, podendo incorporar
sistemas operacionais e aplicativos.
Para isso, Miguel deve contratar o serviço de nuvem:
Para isso, Miguel deve contratar o serviço de nuvem: