Questões de Concurso
Comentadas para analista legislativo - desenvolvimento e manutenção de programas
Foram encontradas 128 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
O bloqueio em nível de linha ou registro, no PostgreSQL versão 11.x, é obtido automaticamente quando a linha é atualizada ou excluída. Os bloqueios em nível de linha não afetam a consulta aos dados, já que bloqueiam apenas gravações na mesma linha.
Para ‘forçar’ um bloqueio de linha em um comando SELECT, deve-se usar:
O uso impróprio de opções de inicialização pode afetar o desempenho do servidor e impedir o SQL Server, versão 2016, de iniciar. Eventualmente, pode ser preciso iniciar o SQL Server em modo de usuário único. Normalmente, essa opção será usada ao se perceber problemas com bancos de dados do sistema que devem ser corrigidos.
A opção de inicialização que deve ser especificada com o SQL Server Configuration Manager, para que uma instância do SQL Server seja iniciada em modo de usuário único, é:
No contexto de data mining, considere o caso hipotético a seguir:
Uma financeira possui o histórico de seus clientes e o comportamento destes em relação ao pagamento de empréstimos contraídos previamente. Existem dois tipos de clientes: adimplentes e inadimplentes. Estas são as categorias do problema (valores do atributo alvo). Uma aplicação de mining, neste caso, consiste em descobrir uma função que mapeie corretamente os clientes, a partir de seus dados (valores dos atributos previsores), em uma destas categorias. Tal função pode ser utilizada para prever o comportamento de novos clientes que desejem contrair empréstimos junto à financeira. Esta função pode ser incorporada a um sistema de apoio à decisão que auxilie na filtragem e na concessão de empréstimos somente a clientes classificados como bons pagadores.
Trata-se de uma atividade denominada
Duas definições de estruturas de dados estão determinadas para um projeto de datamart de uma loja de varejo: uma delas (tabela A) contém a data da venda, a identificação do produto vendido, a quantidade vendida do produto no dia e o valor total das vendas do produto no dia; a outra (tabela B) contém a identificação do produto, nome do produto, marca, modelo, unidade de medida de peso, largura, altura e profundidade da embalagem.
Considerando os conceitos de modelagem multidimensional de data warehouse, as tabelas A e B são, respectivamente:
Um conjunto de programas de computador está sendo executado em um conjunto de servidores conectados em rede local, para alimentar um data warehouse a partir dos bancos de dados transacionais de uma empresa, sendo que: um primeiro programa realiza uma cópia de dados transacionais selecionados em estruturas de dados que formam um staging area; um segundo programa faz a leitura dos dados na staging area e alimenta estruturas de bancos de dados em um Operational Data Storage (ODS), que consolida dados operacionais de diversas aplicações e complementa conteúdo. Por fim, outro programa de aplicação faz a leitura do ODS e carrega estruturas de dados em uma estrutura não relacional de tabelas em um data warehouse.
Esse processo para integrar os bancos de dados que são heterogêneos é denominado:
Atenção: A questão refere-se à Geografia do Amapá.
Considere o gráfico abaixo.
Amapá: Evolução da área plantada de X e Y (2013-2018)
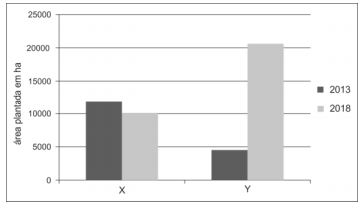
(Disponível em: https://cidades.ibge.gov.br/brasil/ap/pesquisa/14/10193)
Os produtos agrícolas X e Y são, respectivamente,