Questões de Concurso
Para tce-pa
Foram encontradas 4.504 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571748
Engenharia de Software
A análise de componentes principais (Principal Component
Analysis - PCA) é uma técnica de redução de dimensionalidade de
dados utilizada em diversas aplicações, tais como em compressão
de imagens e em processamento de linguagem natural.
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571747
Sistemas Operacionais
Alguns algoritmos de aprendizado de máquina servem para
agrupar instâncias de dados em clusters, podendo ser utilizados
para tarefas como segmentação de imagens, ou segmentação
social (por exemplo, para agrupamento de clientes em uma
mesma categoria.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571746
Estatística
Modelos de previsão podem ser obtidos a partir do uso detécnicas de regressão. Dentre essas técnicas, pode-se citar atécnica de regressão polinomial.
Considere o conjunto de dados e a informação a seguir:
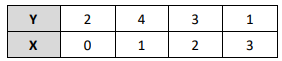
Informação: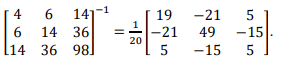
Deseja-se encontrar um modelo de regressão polinomial de 2ograu Y = α0 + α1 X + α2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores deα0, α1 e α2 serão dados, respectivamente, por
Considere o conjunto de dados e a informação a seguir:
Informação:
Deseja-se encontrar um modelo de regressão polinomial de 2ograu Y = α0 + α1 X + α2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores deα0, α1 e α2 serão dados, respectivamente, por
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571744
Engenharia de Software
Modelos de aprendizagem de máquina são, em geral, avaliados
com métricas que indicam os quão poderosos e relevantes eles
são. Entre exemplos de métricas de avaliação utilizadas para
modelos de classificação binária, podemos citar:
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571743
Estatística
Sobre a Análise Exploratória de Dados (AED), avalie as afirmativas
a seguir.
I. A AED permite a obtenção do entendimento sobre os dados coletados. II. A AED fornece uma ideia de como os dados se distribuem e sua forma de apresentação. III. Algoritmos de Machine Learning são as principais ferramentas utilizadas na AED.
Está correto o que se afirma em
I. A AED permite a obtenção do entendimento sobre os dados coletados. II. A AED fornece uma ideia de como os dados se distribuem e sua forma de apresentação. III. Algoritmos de Machine Learning são as principais ferramentas utilizadas na AED.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571742
Banco de Dados
Associe os conceitos a seguir às respectivas características.
1. Data Lake 2. Data Mart
( ) Surgiu como uma alternativa aos armazéns de dados tradicionais, permitindo o armazenamento de grandes volumes de dados de qualquer tipo e tamanho. ( ) São criados para tornar os dados mais facilmente acessíveis para geração de relatórios, além de fornecer um estágio adicional de transformação além das tubulações ETL iniciais. ( ) Tipo de armazenamento de dados frequentemente usado para suportar camadas de apresentação do ambiente de data warehouse. ( ) Fornece um local central de armazenamento para dados brutos, com o mínimo de transformação, se houver.
A associação correta, na ordem dada, é:
1. Data Lake 2. Data Mart
( ) Surgiu como uma alternativa aos armazéns de dados tradicionais, permitindo o armazenamento de grandes volumes de dados de qualquer tipo e tamanho. ( ) São criados para tornar os dados mais facilmente acessíveis para geração de relatórios, além de fornecer um estágio adicional de transformação além das tubulações ETL iniciais. ( ) Tipo de armazenamento de dados frequentemente usado para suportar camadas de apresentação do ambiente de data warehouse. ( ) Fornece um local central de armazenamento para dados brutos, com o mínimo de transformação, se houver.
A associação correta, na ordem dada, é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571741
Banco de Dados
O conceito de Big Data engloba não apenas o volume de dados,
mas também a variedade e a velocidade com que são produzidos
os chamados 3Vs, os principais desafios ou dimensões do Big
Data.
Posteriormente, de acordo com o DAMA-DBOK, aos 3Vs iniciais foram adicionados outros 3Vs aos principais desafios ou dimensões do Big Data. São eles:
Posteriormente, de acordo com o DAMA-DBOK, aos 3Vs iniciais foram adicionados outros 3Vs aos principais desafios ou dimensões do Big Data. São eles:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571740
Banco de Dados
Analise o trecho a seguir:
É um padrão de transformação de dados em lote que foi introduzido como uma alternativa para lidar com grandes volumes de dados. Consiste em tarefas de mapa que leem blocos de dados individuais espalhados pelos nós, seguidas por uma etapa de shuffle que redistribui os dados de resultado e uma etapa de redução que agrega os dados em cada nó. Seu paradigma foi construído em torno da ideia de que a capacidade e largura de banda do disco magnético eram tão baratas que fazia sentido simplesmente usar uma enorme quantidade de disco para realizar consultas ultrarrápidas.
A tecnologia em questão é:
É um padrão de transformação de dados em lote que foi introduzido como uma alternativa para lidar com grandes volumes de dados. Consiste em tarefas de mapa que leem blocos de dados individuais espalhados pelos nós, seguidas por uma etapa de shuffle que redistribui os dados de resultado e uma etapa de redução que agrega os dados em cada nó. Seu paradigma foi construído em torno da ideia de que a capacidade e largura de banda do disco magnético eram tão baratas que fazia sentido simplesmente usar uma enorme quantidade de disco para realizar consultas ultrarrápidas.
A tecnologia em questão é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571739
Banco de Dados
Sobre o processo de ingestão de dados, avalie se as afirmativas a
seguir são verdadeiras (V) ou falsas (F).
( ) Dados não estruturados podem incluir arquivos de texto, logs e outras formas de informação não padronizada. ( ) A ingestão de dados em lote pode ser iniciada mediante agendamento ou quando os dados atingem um limite de tamanho predeterminado. ( ) Apesar de ser mais simples de implementar, a ingestão de dados incremental ou diferencial é ideal para minimizar o tráfego na rede e o uso do storage. ( ) É mais comum adicionar etapas adicionais de transformação e limpeza dos dados em dados estruturados do que em não estruturados.
As afirmativas são, respetivamente,
( ) Dados não estruturados podem incluir arquivos de texto, logs e outras formas de informação não padronizada. ( ) A ingestão de dados em lote pode ser iniciada mediante agendamento ou quando os dados atingem um limite de tamanho predeterminado. ( ) Apesar de ser mais simples de implementar, a ingestão de dados incremental ou diferencial é ideal para minimizar o tráfego na rede e o uso do storage. ( ) É mais comum adicionar etapas adicionais de transformação e limpeza dos dados em dados estruturados do que em não estruturados.
As afirmativas são, respetivamente,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571738
Governança de TI
O crescimento na quantidade e complexidade dos dados
disponíveis para as empresas torna imprescindível que a
Governança de Dados seja estruturada com documentos que
circulem em vários níveis da empresa de acordo com as suas
respectivas finalidades, contribuindo para colimar os esforços de
todos os membros para obter os resultados esperados.
Com relação aos documentos da Governança de Dados, avalie as afirmativas a seguir.
I. As políticas de dados são regras pormenorizadas do que pode ser feito e o que não pode ser feito, devendo ser conhecidas por todos os profissionais da empresa. II. As normas são documentos que indicam as práticas recomendadas, mas não obrigatórias, que devem ser adotadas pelas pessoas que trabalham com os dados. III. Os procedimentos têm por finalidade orientar as pessoas na execução de tarefas específicas visando atingir determinado objetivo, ou seja, documentos que indicam o “como fazer” determinada tarefa.
Está correto o que se afirma em
Com relação aos documentos da Governança de Dados, avalie as afirmativas a seguir.
I. As políticas de dados são regras pormenorizadas do que pode ser feito e o que não pode ser feito, devendo ser conhecidas por todos os profissionais da empresa. II. As normas são documentos que indicam as práticas recomendadas, mas não obrigatórias, que devem ser adotadas pelas pessoas que trabalham com os dados. III. Os procedimentos têm por finalidade orientar as pessoas na execução de tarefas específicas visando atingir determinado objetivo, ou seja, documentos que indicam o “como fazer” determinada tarefa.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571735
Banco de Dados
Com o aumento do volume e da complexidade dos dados gerados
em sistemas de informação atuais, cresce a necessidade de
eficiência no armazenamento, segurança, recuperação de dados
e disponibilidade.
Nesse contexto, o algoritmo HNSW (Hierarchical Navigable Small World) busca, ao ser aplicado em bases de dados de vetores,
Nesse contexto, o algoritmo HNSW (Hierarchical Navigable Small World) busca, ao ser aplicado em bases de dados de vetores,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571734
Banco de Dados
A eficiência no armazenamento de dados é crucial para muitas
organizações. Tecnologias como Amazon S3, CEPH e HDFS
apresentam soluções adequadas a diferentes necessidades.
Sobre esses modelos de armazenamento, avalie as afirmativas a seguir.
I. O Amazon Simple Storage Service utiliza um sistema de arquivos distribuídos, o que proporciona uma escalabilidade praticamente ilimitada. II. O modelo CEPH é indicado para organizações que lidam com dados altamente sensíveis, como informações financeiras, jurídicas ou dados governamentais. III. Dividir arquivos grandes em blocos de tamanho fixo aumenta a eficiência do HDFS no processamento de grandes volumes de dados, ou Big Data.
Está correto o que se afirma em
Sobre esses modelos de armazenamento, avalie as afirmativas a seguir.
I. O Amazon Simple Storage Service utiliza um sistema de arquivos distribuídos, o que proporciona uma escalabilidade praticamente ilimitada. II. O modelo CEPH é indicado para organizações que lidam com dados altamente sensíveis, como informações financeiras, jurídicas ou dados governamentais. III. Dividir arquivos grandes em blocos de tamanho fixo aumenta a eficiência do HDFS no processamento de grandes volumes de dados, ou Big Data.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571733
Arquitetura de Computadores
O armazenamento de objetos é projetado para guardar grandes
volumes de dados de maneira eficiente.
Uma de suas características principais é
Uma de suas características principais é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571732
Engenharia de Software
Ao se utilizar bancos de dados reais no treinamento de métodos
de aprendizado de máquina é normal se deparar com entradas
que possuem um ou mais parâmetros (campos) ausentes.
Com relação às estratégias para lidar com dados ausentes, analise as afirmativas a seguir.
I. Só é possível realizar imputation quando o atributo (feature) ausente é numérico. II. Ao utilizar o k-nearest neighbors (KNN) para fazer o imputation é uma boa estratégia primeiro fazer a normalização ou padronização dos dados. III. Ao se trabalhar com bancos de dados com poucas amostras (itens), uma estratégia usualmente utilizada para lidar com as amostras) que possuem valores ausentes é a remoção.
Está correto o que se afirma em
Com relação às estratégias para lidar com dados ausentes, analise as afirmativas a seguir.
I. Só é possível realizar imputation quando o atributo (feature) ausente é numérico. II. Ao utilizar o k-nearest neighbors (KNN) para fazer o imputation é uma boa estratégia primeiro fazer a normalização ou padronização dos dados. III. Ao se trabalhar com bancos de dados com poucas amostras (itens), uma estratégia usualmente utilizada para lidar com as amostras) que possuem valores ausentes é a remoção.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571731
Engenharia de Software
O tratamento dos dados influencia diretamente no desempenho
de muitos algoritmos de aprendizado de máquina.
A respeito de métodos de normalização e padronização numéricos é correto afirmar que
A respeito de métodos de normalização e padronização numéricos é correto afirmar que
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571730
Engenharia de Software
Alguns algoritmos de aprendizado de máquina foram
desenvolvidos para trabalhar com atributos discretos. Porém,
dados coletados no mundo real muitas vezes são contínuos.
Nesses casos, podemos usar métodos de discretização no tratamento dos dados. Um desses métodos de discretização consiste em estabelecer os limites das partições de forma que cada partição tenha aproximadamente o mesmo número de elementos.
O método acima descrito é o
Nesses casos, podemos usar métodos de discretização no tratamento dos dados. Um desses métodos de discretização consiste em estabelecer os limites das partições de forma que cada partição tenha aproximadamente o mesmo número de elementos.
O método acima descrito é o
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571729
Estatística
Os candidatos de um concurso público realizaram um teste de
redação que vale até 1000 pontos. 5000 candidatos realizaram o
teste, o que gerou uma distribuição das notas cuja média foi de
600 pontos e cujo desvio padrão foi de 90 pontos.
Dessa distribuição são retiradas 40 novas amostras, com 100
notas em cada amostra, sem reposição.
Dados: √4999 = 70,7; 100/101 = 0,99
O desvio-padrão da distribuição das 40 médias obtidas a partir das novas amostras (de 100 notas) retiradas é igual a
Dados: √4999 = 70,7; 100/101 = 0,99
O desvio-padrão da distribuição das 40 médias obtidas a partir das novas amostras (de 100 notas) retiradas é igual a
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571728
Estatística
Testes de hipóteses são ferramentas estatísticas que viabilizam a
tomada de decisões com base em dados, mesmo quando há
incerteza.
A respeito dessas ferramentas, relacione cada definição com as características a que elas mais se adequam:
1. Teste-z 2. Teste-t 3. ANOVA 4. Teste chi-quadrado (χ2)
( ) Usado(a) para comparar as médias de duas amostras independentes, com amostragens suficientemente grandes e desvios-padrão conhecidos. ( ) Usado(a) para comparar as médias de duas ou mais amostras independentes, normalmente distribuídas. ( ) Usado(a) para comparar as médias de duas amostras independentes, com pequeno número de amostras ou com desvio-padrão desconhecido. ( ) Usado(a) para verificar a normalidade de uma amostra.
A relação correta, na ordem apresentada, é
A respeito dessas ferramentas, relacione cada definição com as características a que elas mais se adequam:
1. Teste-z 2. Teste-t 3. ANOVA 4. Teste chi-quadrado (χ2)
( ) Usado(a) para comparar as médias de duas amostras independentes, com amostragens suficientemente grandes e desvios-padrão conhecidos. ( ) Usado(a) para comparar as médias de duas ou mais amostras independentes, normalmente distribuídas. ( ) Usado(a) para comparar as médias de duas amostras independentes, com pequeno número de amostras ou com desvio-padrão desconhecido. ( ) Usado(a) para verificar a normalidade de uma amostra.
A relação correta, na ordem apresentada, é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571727
Matemática
Considere a existência de duas caixas idênticas A e B. Na caixa A
são colocadas duas bolinhas de cor verde e duas bolinhas cor-de-rosa. Na caixa B são colocadas quatro bolinhas de cor verde.
Em seguida, executam-se sequencialmente os passos a seguir:
1. Escolhe-se, aleatoriamente, uma das caixas, sem, no entanto, identificá-la. 2. Retira-se uma bolinha da caixa escolhida, que revela possuir a cor verde. 3. Retira-se uma segunda bolinha da caixa escolhida, que também acaba por possuir a cor verde.
A sequência que indica a evolução das probabilidades de que a caixa inicialmente escolhida seja a caixa A ou a caixa B, respectivamente, imediatamente após os passos 1, 2, e 3, é dada por:
Em seguida, executam-se sequencialmente os passos a seguir:
1. Escolhe-se, aleatoriamente, uma das caixas, sem, no entanto, identificá-la. 2. Retira-se uma bolinha da caixa escolhida, que revela possuir a cor verde. 3. Retira-se uma segunda bolinha da caixa escolhida, que também acaba por possuir a cor verde.
A sequência que indica a evolução das probabilidades de que a caixa inicialmente escolhida seja a caixa A ou a caixa B, respectivamente, imediatamente após os passos 1, 2, e 3, é dada por:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571726
Estatística
Num pote foram colocadas 8 bolas, sendo 2 amarelas, 2 azuis, 2
vermelhas e 2 brancas. Ao se retirar do pote uma amostra
aleatória simples de 4 bolas, a probabilidade de que ela contenha
apenas uma bola de cada cor é