Questões de Concurso
Para tcu
Foram encontradas 3.450 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q1892821
Auditoria Governamental
A materialidade está entre os princípios norteadores da
elaboração e divulgação da prestação de contas no âmbito da
Administração Pública Federal. Trata-se de um aspecto utilizado
para determinar a importância relativa de uma distorção ou
irregularidade, nível a partir do qual estas são consideradas
relevantes.
Nos termos da Instrução Normativa TCU nº 84/2020, para fins de autuação de processo de tomada de contas, é necessário avaliar o nível de materialidade.
Considere os dados do quadro a seguir relativos à execução orçamentária hipotética de uma autarquia federal no exercício financeiro de 2021.

O limite mínimo para que um conjunto de irregularidades detectadas na autarquia no referido exercício seja considerado materialmente relevante, para fins de autuação de processo de tomada de contas, é, em milhões de reais, de:
Nos termos da Instrução Normativa TCU nº 84/2020, para fins de autuação de processo de tomada de contas, é necessário avaliar o nível de materialidade.
Considere os dados do quadro a seguir relativos à execução orçamentária hipotética de uma autarquia federal no exercício financeiro de 2021.
O limite mínimo para que um conjunto de irregularidades detectadas na autarquia no referido exercício seja considerado materialmente relevante, para fins de autuação de processo de tomada de contas, é, em milhões de reais, de:
Q1892820
Auditoria Governamental
Durante um trabalho de auditoria, um dos procedimentos
previstos na matriz de planejamento era um teste de
conformidade (para controle de qualidade) em uma população
finita superior a 500 elementos. Para que a população testada
fosse aprovada, foi definido como critério que a proporção
máxima de erros admitidos seria de 3%. Foi considerado ainda
um nível de confiança de 95% e que a amostra conteria no
máximo um único erro.
Considere ainda a tabela a seguir, que contém índices calculados de confiabilidade para quantidades previstas de erros e níveis de confiança.
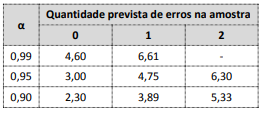
A partir dos dados apresentados e para cumprir os critérios previamente definidos, o tamanho da amostra para o teste na população indicada deve ser de:
Considere ainda a tabela a seguir, que contém índices calculados de confiabilidade para quantidades previstas de erros e níveis de confiança.
A partir dos dados apresentados e para cumprir os critérios previamente definidos, o tamanho da amostra para o teste na população indicada deve ser de:
Q1892819
Auditoria Governamental
O Tribunal de Contas da União adotou de forma adaptada
algumas ferramentas de auditoria utilizadas pelo U.S.
Government Accountability Office (U.S. GAO), a exemplo da
matriz de planejamento, que é uma ferramenta importante na
definição do escopo do trabalho de auditoria.
Na situação hipotética de um trabalho de auditoria que tem por objeto a concessão de auxílio financeiro emergencial a pessoas que perderam renda em decorrência de uma epidemia que atingiu o país e afetou a economia, a matriz de planejamento:
Na situação hipotética de um trabalho de auditoria que tem por objeto a concessão de auxílio financeiro emergencial a pessoas que perderam renda em decorrência de uma epidemia que atingiu o país e afetou a economia, a matriz de planejamento:
Q1892818
Auditoria Governamental
Nos trabalhos de auditoria, é necessária a definição de critérios,
que consistem em referências para avaliar o objeto auditado. Tais
referências são previamente determinadas pelo auditor.
No contexto das entidades públicas, conforme a ISSAI 100, a
definição desses critérios:
Q1892817
Engenharia de Software
Durante o treinamento de uma rede neural artificial para
classificação de imagens, foi observado o comportamento
descrito pelo gráfico abaixo, que mostra a evolução do erro
conforme o número de iterações.
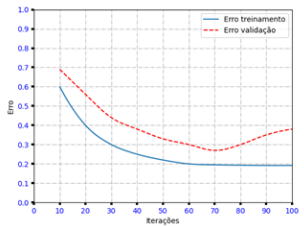
O classificador em questão foi treinado em um conjunto de dados particionado (holdout) em 60%/30%/10% (treinamento/validação/ teste). Entretanto, os especialistas envolvidos consideraram o modelo obtido insatisfatório após analisarem o gráfico.
Considerando essas informações, duas técnicas que poderiam ser utilizadas para contornar o problema encontrado são:
O classificador em questão foi treinado em um conjunto de dados particionado (holdout) em 60%/30%/10% (treinamento/validação/ teste). Entretanto, os especialistas envolvidos consideraram o modelo obtido insatisfatório após analisarem o gráfico.
Considerando essas informações, duas técnicas que poderiam ser utilizadas para contornar o problema encontrado são:
Q1892816
Engenharia de Software
Uma organização está implementando um sistema de busca de
informações interno, e a equipe de desenvolvimento resolveu
avaliar diferentes modelos de linguagem vetoriais que ajudariam
a conectar melhor documentos e consultas em departamentos
que usam terminologias distintas em áreas de negócio que se
sobrepõem. Um dos analistas ressaltou que seria interessante
guardar os vetores de todo o vocabulário do modelo em um
cache, de forma a aumentar a eficiência de acesso e reduzir
certos custos de implantação.
Das alternativas abaixo, aquela que lista apenas os modelos compatíveis com essa estratégia de caching é:
Das alternativas abaixo, aquela que lista apenas os modelos compatíveis com essa estratégia de caching é:
Q1892815
Direito Digital
Conjuntos de dados identificados de pessoas são úteis em
pesquisas, ao mesmo tempo que são motivo de preocupação em
relação à privacidade das pessoas naturais envolvidas. A
classificação de atributos identificadores ajuda a priorizar
atividades de desidentificação para alavancar a pesquisa sob a
observância da LGPD.
São exemplos: a) de identificadores explícitos, b) de identificadores sensíveis e c) de quasi identificadores:
São exemplos: a) de identificadores explícitos, b) de identificadores sensíveis e c) de quasi identificadores:
Q1892813
Algoritmos e Estrutura de Dados
Considere os documentos A e B a seguir.
A = “Há pessoas que choram por saber que as rosas têm espinho” B = “Há outras que sorriem por saber que os espinhos têm rosas”
A submatriz da matriz de TF-IDF desses dois documentos correspondente aos termos “Rosas”, “Choram” e “Sorriem”, nessa ordem, é:
A = “Há pessoas que choram por saber que as rosas têm espinho” B = “Há outras que sorriem por saber que os espinhos têm rosas”
A submatriz da matriz de TF-IDF desses dois documentos correspondente aos termos “Rosas”, “Choram” e “Sorriem”, nessa ordem, é:
Q1892812
Programação
A tabela presente no código em R abaixo apresenta a quantidade
de processos analisados por três analistas (denotados por A1, A2
e A3) em diferentes anos.
dados = tibble::tibble(Analista=c(“A1”, “A1”, “A1”, “A2”, “A2”, “A3”, “A3”, “A3”),
Ano=c(2018,2019,2020,2019,2020,2018,2019,2020), Processos=c(10,15,20,25,20,8,7,12))
Um programador roda o código abaixo em R.
tidyr::pivot_wider(data=dados, names_from=”Analista”, values_from=”Processos”)
Os valores esperados na primeira linha do objeto resultante do comando acima são:
dados = tibble::tibble(Analista=c(“A1”, “A1”, “A1”, “A2”, “A2”, “A3”, “A3”, “A3”),
Ano=c(2018,2019,2020,2019,2020,2018,2019,2020), Processos=c(10,15,20,25,20,8,7,12))
Um programador roda o código abaixo em R.
tidyr::pivot_wider(data=dados, names_from=”Analista”, values_from=”Processos”)
Os valores esperados na primeira linha do objeto resultante do comando acima são:
Q1892811
Banco de Dados
Um analista do TCU gostaria de aplicar um modelo de Latent
Dirichlet Allocation (LDA) em um conjunto de textos. A alternativa que melhor descreve o resultado do modelo é:
Q1892810
Banco de Dados
Um analista de dados deseja criar um modelo para classificação
de documentos em duas categorias: sigilosos e públicos. À sua
disposição, existe um conjunto de dados com N documentos, dos
quais uma fração α deles é sigilosa. O analista quer escolher uma
fração β dos N documentos para pertencer ao conjunto de teste.
O objetivo é garantir que cada uma das classes (documentos
sigilosos e públicos) seja responsável, em média, por ao menos
10% do total de documentos. Essa restrição precisa ser válida
tanto no conjunto de treino quanto no conjunto de teste.
Um par (α,β) que satisfaz as restrições do analista é:
Q1892809
Engenharia de Software
Seja uma rede neural com camada de entrada com dimensão dois
que recebe dados (x1
, x2
). Essa rede aplica pesos w1 em x1
, w2 em
x2 e adiciona um viés w0
. A função de ativação é dada pela função
sinal s(z) = +1, se z ≥ 0, e s(z) = -1, se z < 0. Essa rede não tem
nenhuma camada oculta e será utilizada para classificar
observações em y=+1 ou y=-1.
Para pesos w1 = 2, w2 = 3 e viés w0 = 1, a região de classificação é uma reta que passa nos pontos:
Para pesos w1 = 2, w2 = 3 e viés w0 = 1, a região de classificação é uma reta que passa nos pontos:
Q1892808
Algoritmos e Estrutura de Dados
Em um problema de classificação é entregue ao cientista de
dados um par de covariáveis, (x1
, x2
), para cada uma das quatro
observações a seguir: (6,4), (2,8), (10,6) e (5,2). A variável
resposta observada nessa amostra foi “Sim”, “Não”, “Sim”,
“Não”, respectivamente.
A partição que apresenta o menor erro de classificação quando feita na raiz (primeiro nível) de uma árvore de decisão é:
A partição que apresenta o menor erro de classificação quando feita na raiz (primeiro nível) de uma árvore de decisão é:
Q1892807
Banco de Dados
Um analista do TCU recebe o conjunto de dados com
covariáveis e a classe a que cada amostra pertence na tabela a
seguir.
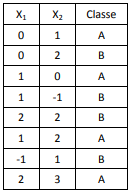
Esse analista gostaria de prever a classe dos pontos (1,1), (0,0) e (-1,2) usando o algoritmo de k-vizinhos mais próximos com k=3 e usando a distância euclidiana usual.
Suas classes previstas são, respectivamente:
Esse analista gostaria de prever a classe dos pontos (1,1), (0,0) e (-1,2) usando o algoritmo de k-vizinhos mais próximos com k=3 e usando a distância euclidiana usual.
Suas classes previstas são, respectivamente:
Q1892806
Banco de Dados
Texto associado
ATENÇÃO!
Para a questão a seguir, considere uma tabela relacional R, com atributos W, X, Y, Z, e o conjunto de dependências funcionais identificadas para esses atributos.
X → Y
X → Z
Z → X
Z → W
Com referência à tabela R, definida anteriormente, considere o
esboço de um comando SQL para a criação da tabela.
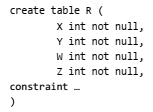
De acordo com as dependências funcionais de R, e com a Forma Normal de Boyce-Codd, a definição correta das chaves (por meio de constraints) aplicáveis e necessárias para essa tabela deveria ser:
De acordo com as dependências funcionais de R, e com a Forma Normal de Boyce-Codd, a definição correta das chaves (por meio de constraints) aplicáveis e necessárias para essa tabela deveria ser:
Q1892805
Banco de Dados
Texto associado
ATENÇÃO!
Para a questão a seguir, considere uma tabela relacional R, com atributos W, X, Y, Z, e o conjunto de dependências funcionais identificadas para esses atributos.
X → Y
X → Z
Z → X
Z → W
Analise o conjunto de dependências funcionais inferidas abaixo
a partir do conjunto de atributos e dependências funcionais
presentes na tabela R, como descrita anteriormente.
(1) X → Y Z W (2) X → W (3) X W → Y W (4) X Y Z W → X Y (5) Y → Z
À luz dos axiomas da teoria de projeto de bancos de dados aplicáveis nesse caso, é correto concluir que, dentre essas dependências inferidas:
(1) X → Y Z W (2) X → W (3) X W → Y W (4) X Y Z W → X Y (5) Y → Z
À luz dos axiomas da teoria de projeto de bancos de dados aplicáveis nesse caso, é correto concluir que, dentre essas dependências inferidas:
Q1892804
Programação
Natasha, uma cientista de dados, está trabalhando com um
conjunto de dados sobre carros para fazer um modelo preditivo
para uma companhia de seguros. A primeira versão do modelo
utiliza apenas informações básicas sobre os carros: a marca e a
cor.
Como esses dados são categóricos, Natasha faz um pré-processamento usando a biblioteca scikit-learn. Em um ambiente interativo, ela executa os comandos a seguir.
>>> from sklearn.preprocessing import OneHotEncoder >>> enc = OneHotEncoder() >>> X = [['Toyota', 'vermelho'], ['Toyota', 'verde'], ['BMW', 'vermelho']]
>>> enc.fit(X) >>> enc.get_feature_names() array(['x0_BMW', 'x0_Toyota', 'x1_verde', 'x1_vermelho'], dtype=object)
>>> X_prime = enc.transform(X).toarray() >>> X_prime array([[0., 1., 0., 1.], [0., 1., 1., 0.], [1., 0., 0., 1.]])
Para contar o número de carros da marca Toyota no conjunto de dados, obtendo corretamente o resultado 2, Natasha pode usar a seguinte linha de código:
Como esses dados são categóricos, Natasha faz um pré-processamento usando a biblioteca scikit-learn. Em um ambiente interativo, ela executa os comandos a seguir.
>>> from sklearn.preprocessing import OneHotEncoder >>> enc = OneHotEncoder() >>> X = [['Toyota', 'vermelho'], ['Toyota', 'verde'], ['BMW', 'vermelho']]
>>> enc.fit(X) >>> enc.get_feature_names() array(['x0_BMW', 'x0_Toyota', 'x1_verde', 'x1_vermelho'], dtype=object)
>>> X_prime = enc.transform(X).toarray() >>> X_prime array([[0., 1., 0., 1.], [0., 1., 1., 0.], [1., 0., 0., 1.]])
Para contar o número de carros da marca Toyota no conjunto de dados, obtendo corretamente o resultado 2, Natasha pode usar a seguinte linha de código:
Q1892803
Programação
Considere o código Python a seguir.

A execução desse código na IDLE Shell produz, na ordem e exclusivamente, os números:
A execução desse código na IDLE Shell produz, na ordem e exclusivamente, os números:
Q1892802
Banco de Dados
Texto associado


DUAL

ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T
TX
Nas colunas das três tabelas, o tipo é o de número inteiro. Em
todos os comandos SQL, considera-se o NULL como um valor
desconhecido (unknown).
Analise os cinco comandos SQL exibidos abaixo, utilizando a
tabela DUAL apresentada anteriormente.
(1) select * from dual where x = null (2) select * from dual where x <> null (3) select * from dual where x > 10 (4) select * from dual where not x > 10 (5) select * from dual where x > 10 union select * from dual where x <= 10
Se os resultados desses comandos fossem separados em grupos homogêneos, de modo que em cada grupo todos sejam idênticos e distintos dos elementos dos demais grupos, haveria:
(1) select * from dual where x = null (2) select * from dual where x <> null (3) select * from dual where x > 10 (4) select * from dual where not x > 10 (5) select * from dual where x > 10 union select * from dual where x <= 10
Se os resultados desses comandos fossem separados em grupos homogêneos, de modo que em cada grupo todos sejam idênticos e distintos dos elementos dos demais grupos, haveria:
Q1892801
Banco de Dados
Texto associado
DUAL
ATENÇÃO!
Na próxima questão, considere as tabelas de banco de dados T, TX e DUAL, exibidas com suas respectivas instâncias a seguir.
T
TX
Nas colunas das três tabelas, o tipo é o de número inteiro. Em
todos os comandos SQL, considera-se o NULL como um valor
desconhecido (unknown).
Supondo que a coluna sequencia da tabela T, anteriormente
definida, deveria conter números inteiros em sequência
contínua, seria preciso descobrir os intervalos de valores
faltantes. Um valor é considerado faltante quando a) é um
número inteiro n entre o menor e o maior valor da tabela, tal
que n não esteja presente na tabela, ou b) é um número
presente na tabela T, com valor nulo na coluna caracteristica.
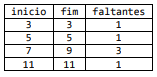
O comando SQL que produz o resultado acima, a partir da instância inicialmente definida para a tabela T, é:
O comando SQL que produz o resultado acima, a partir da instância inicialmente definida para a tabela T, é: