Questões de Concurso
Para analista - ciências sociais
Foram encontradas 403 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048126
Engenharia de Software
Em aplicações modernas de Processamento de Linguagem Natural, usando Grandes Modelos de Linguagem
(Large Language Models – LLM) é comum a necessidade de usar informações relevantes que estão em documentos novos e privados, que não foram usados no pré-treinamento dos modelos de LLM. Considerando que esses documentos podem ser longos e em grande quantidade, que o tamanho do contexto usado na chamada à
Application Programming Interface (API) da LLM é limitado, e ainda pensando que os custos de processar
são muitas vezes calculados por quantidade de tokens, foi desenvolvida a técnica conhecida como Retrieval
Augmented Generation (RAG).
Considerando-se esse contexto, qual é a característica da técnica RAG?
Considerando-se esse contexto, qual é a característica da técnica RAG?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048123
Estatística
Um cientista de dados está utilizando SHapley Additive
exPlanations (SHAP) para entender a importância das variáveis em um modelo de aprendizado de máquina que
prevê a probabilidade de um cliente deixar de ser assinante de um serviço (churn). Considere o seguinte conjunto
de dados simplificado com três características para um
cliente específico:
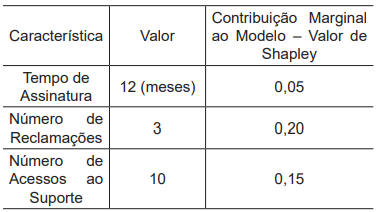
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048122
Engenharia de Software
Um pesquisador de ciência de dados foi encarregado de
analisar a capacidade de um modelo de aprendizado de
máquina em prever se um cliente é bom pagador. Para
isso, possuía um conjunto de dados de testes rotulado,
sobre o qual aplicou o modelo e obteve a matriz de confusão a seguir:
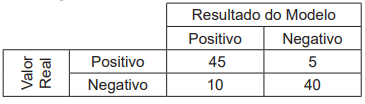
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048121
Engenharia de Software
Um programador estava trabalhando no branch
solvebugio e acabou o serviço. Após fazer o commit
final nesse branch, ele deseja passar todas as mudanças
feitas no branch solvebugio para o branch main, fazendo a
integração correta de mudanças.
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Considerando-se esse contexto e as melhores práticas de controle de versão, quais comandos Git esse programador deve usar para realizar essa tarefa?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048120
Engenharia de Software
Uma equipe de desenvolvimento de Inteligência Artificial
(IA) em uma empresa de tecnologia está implementando
um sistema de recomendação baseado em aprendizado
de máquina. Durante o processo de implementação, a
equipe precisa estar atenta aos potenciais riscos e vulnerabilidades associados ao uso da IA. O sistema utiliza
grandes volumes de dados históricos de clientes para treinar seus modelos. Há uma preocupação com a possibilidade de invasores manipularem a entrada de dados para
enganar o modelo e gerar saídas indesejadas ou incorretas. A equipe deve também garantir que o modelo não
exponha dados sensíveis dos clientes.
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048119
Comunicação Social
Uma narrativa visual apresentada durante uma comunicação corporativa pode utilizar várias estratégias para assegurar
que o storytelling seja eficaz.
Como funciona a prática conhecida como ‘lógica horizontal’?
Como funciona a prática conhecida como ‘lógica horizontal’?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048117
Banco de Dados
Uma empresa está desenvolvendo um dashboard interativo para monitorar o desempenho das vendas em tempo real. O
objetivo é fornecer uma visão clara e acessível para diferentes níveis de usuários, desde gerentes executivos até analistas
de dados. Foram definidos os seguintes requisitos:
1. Os dados de vendas precisam ser visualizados por região, produto e período de tempo.
2. O dashboard deve permitir aos usuários explorar dados específicos por meio de interações como filtros e drill-downs.
3. A organização dos elementos visuais deve ser intuitiva, priorizando informações críticas e mantendo um layout claro e acessível.
Com base nas boas práticas de design de dashboards, qual abordagem deve ser adotada para garantir que o dashboard seja eficaz e acessível para todos os usuários?
1. Os dados de vendas precisam ser visualizados por região, produto e período de tempo.
2. O dashboard deve permitir aos usuários explorar dados específicos por meio de interações como filtros e drill-downs.
3. A organização dos elementos visuais deve ser intuitiva, priorizando informações críticas e mantendo um layout claro e acessível.
Com base nas boas práticas de design de dashboards, qual abordagem deve ser adotada para garantir que o dashboard seja eficaz e acessível para todos os usuários?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048116
Engenharia de Software
Ao avaliar a performance de diversos modelos preditivos para um problema de regressão e outro de classificação, várias
métricas podem ser utilizadas para determinar qual modelo oferece o melhor desempenho. Considere as métricas para
regressão e classificação, bem como as técnicas de detecção de overfitting e underfitting.
Nesse contexto, quais métricas devem ser utilizadas para determinar qual modelo oferece o melhor desempenho?
Nesse contexto, quais métricas devem ser utilizadas para determinar qual modelo oferece o melhor desempenho?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048115
Estatística
Uma equipe precisa apresentar os resultados de diversas análises para diferentes públicos. Cada visualização deve ser
escolhida e projetada de forma a comunicar claramente os insights obtidos, considerando as boas práticas de design e de
acessibilidade.
Serão apresentados, em momentos diferentes, os seguintes dados:
1. Distribuição de idades de uma pesquisa populacional, que possui um grande número de participantes.
2. Comparação de receitas mensais de diferentes setores de uma empresa ao longo de um ano.
3. Proporção de vendas de diferentes produtos de uma loja durante o último trimestre.
4. Análise de correlação entre as variáveis “horas de estudo” e “nota final” de estudantes.
Considerando-se as boas práticas de design e acessibilidade, quais tipos de gráficos devem ser utilizados para a visualização dessas quatro situações?
Serão apresentados, em momentos diferentes, os seguintes dados:
1. Distribuição de idades de uma pesquisa populacional, que possui um grande número de participantes.
2. Comparação de receitas mensais de diferentes setores de uma empresa ao longo de um ano.
3. Proporção de vendas de diferentes produtos de uma loja durante o último trimestre.
4. Análise de correlação entre as variáveis “horas de estudo” e “nota final” de estudantes.
Considerando-se as boas práticas de design e acessibilidade, quais tipos de gráficos devem ser utilizados para a visualização dessas quatro situações?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048114
Governança de TI
Uma empresa está implementando um programa de governança de dados para melhorar a qualidade e a integridade dos
dados que utiliza em suas operações diárias. As seguintes diretrizes foram passadas ao time de implantação:
1. Garantir que os dados sejam precisos, completos e atualizados em tempo real, para apoiar a tomada de decisões estratégicas.
2. Implementar políticas que assegurem a conformidade com regulamentos de privacidade de dados, como a Lei Geral de Proteção de Dados Pessoais (LGPD).
3. Adotar as melhores práticas do Data Management Body of Knowledge (DMBOK) para estruturar seu programa de governança de dados.
Com base nos conceitos de governança de dados do DMBOK, quais ações são necessárias para implementar as diretrizes mencionadas?
1. Garantir que os dados sejam precisos, completos e atualizados em tempo real, para apoiar a tomada de decisões estratégicas.
2. Implementar políticas que assegurem a conformidade com regulamentos de privacidade de dados, como a Lei Geral de Proteção de Dados Pessoais (LGPD).
3. Adotar as melhores práticas do Data Management Body of Knowledge (DMBOK) para estruturar seu programa de governança de dados.
Com base nos conceitos de governança de dados do DMBOK, quais ações são necessárias para implementar as diretrizes mencionadas?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048113
Engenharia de Software
Como parte do processo de desenvolvimento de uma aplicação para analisar grandes volumes de textos, diversas tarefas
de Processamento de Linguagem Natural (NLP, sigla em inglês) estão sendo implementadas para melhorar a eficácia e a
precisão dessa aplicação.
Diante disso, para a aplicação dessas tarefas, é necessário
Diante disso, para a aplicação dessas tarefas, é necessário
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048112
Engenharia de Software
Uma equipe de cientistas de dados está desenvolvendo um modelo preditivo e deseja otimizar seus hiperparâmetros para
maximizar a performance do modelo.
Considerando-se as técnicas de otimização de hiperparâmetros, para encontrar a configuração de hiperparâmetros, essa equipe de cientistas deverá
Considerando-se as técnicas de otimização de hiperparâmetros, para encontrar a configuração de hiperparâmetros, essa equipe de cientistas deverá
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048111
Banco de Dados
Uma equipe de ciência de dados está trabalhando na construção de um modelo preditivo utilizando um grande conjunto de
dados. Durante esse processo, os cientistas de dados estão realizando o feature engineering para criar e selecionar as variáveis mais relevantes, além de aplicar técnicas de divisão de dados para garantir a eficácia e a generalização do modelo.
Considerando-se esse contexto, qual combinação de técnicas maximizará a performance do modelo?
Considerando-se esse contexto, qual combinação de técnicas maximizará a performance do modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048110
Estatística
Uma equipe de análise de riscos de um banco de investimentos precisa avaliar o risco de diferentes carteiras de clientes, que possuem ativos em escalas variadas. Para isso, ela decidiu utilizar modelos de aprendizado de máquina, a fim
de auxiliar o seu processo de tomada de decisão. Os analistas da equipe perceberam que parte dos ativos disponíveis
poderia influenciar desproporcionalmente a análise de risco. Assim, decidiram aplicar a técnica de normalização z-score.
Com essa medida, pretendem reduzir a influência de uma variação abrupta no treinamento dos modelos de aprendizado
de máquina, promovendo uma comparação justa entre os ativos e uma avaliação mais precisa do risco em cada carteira.
Considere que W seja o conjunto de todos os valores em reais dos ativos de carteiras de investimentos que a equipe de
analistas precisa avaliar.
Uma das características da normalização z-score é que, em sua definição original (clássica), essa normalização
Uma das características da normalização z-score é que, em sua definição original (clássica), essa normalização
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048109
Banco de Dados
Um conjunto de dados numéricos com significativa diversidade foi apresentado à equipe de análise de dados de uma empresa. Como parte do processo decisório, os analistas necessitavam transformar um dos atributos numéricos em faixas
de valores, a fim de permitir classificá-los em um universo de possibilidades. Para isso, decidiram, na etapa de enriquecimento de dados, criar um atributo, derivado do atributo numérico supracitado, em um processo de transformação de dados
conhecido por discretização.
Uma das características das técnicas de discretização é que
Uma das características das técnicas de discretização é que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048108
Arquitetura de Software
O Microsoft Team Data Science Process (TDSP) é uma metodologia que define, entre outros conceitos, um ciclo de vida
para projetos de ciência de dados.
A TDSP possui cinco estágios principais, de modo que na etapa de
A TDSP possui cinco estágios principais, de modo que na etapa de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048107
Banco de Dados
Em um Sistema Gerenciador de Banco de Dados (SGBD), os índices são estruturas de dados que têm por objetivo tornar
mais rápido o acesso aos dados. Índices são utilizados tanto em SGBD relacionais quanto em SGBD NoSQL.
Considerando-se uma tabela T1 em um SGBD relacional, quanto a esses índices, verifica-se que
Considerando-se uma tabela T1 em um SGBD relacional, quanto a esses índices, verifica-se que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048106
Banco de Dados
O modelo relacional de dados é amplamente utilizado em
bancos de dados. A organização de dados em tabelas (relações), com suas respectivas linhas (tuplas) e colunas
(atributos), é de fácil compreensão. Os Sistemas Gerenciadores de Bancos de Dados Relacionais (SGBDR) tornam possível persistir dados em tabelas com qualidade
e recuperar esses mesmos dados de forma rápida e eficiente.
Segundo o modelo relacional de dados, uma tabela pode ter
Segundo o modelo relacional de dados, uma tabela pode ter
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048105
Banco de Dados
Data warehouses (DW) e data lakes (DL) são repositórios
de dados especializados, com objetivos distintos dos bancos de dados relacionais e NoSQL.
Nesse contexto, ao comparar DW a DL, verifica-se que
Nesse contexto, ao comparar DW a DL, verifica-se que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
BNDES
Prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados (Manhã) |
Q3048104
Banco de Dados
Os bancos de dados relacionais permitem a modelagem e
a persistência de dados estruturados. Uma característica
de tais bancos de dados é que eles possuem metadados.
Considere que um banco de dados possui uma tabela relacional chamada PRODUTO e que essa tabela possui
atributos, tais como a identificação do produto, o nome do
produto e o seu valor de venda.
Nesse cenário, os metadados relativos à tabela PRODUTO são utilizados pelo seu respectivo Sistema Gerenciador de Banco de Dados Relacionais (SGBDR) para
Nesse cenário, os metadados relativos à tabela PRODUTO são utilizados pelo seu respectivo Sistema Gerenciador de Banco de Dados Relacionais (SGBDR) para