Questões de Concurso
Para auditor de controle externo
Foram encontradas 4.156 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571226
Enfermagem
O principal objetivo do Protocolo para Cirurgia Segura da
Organização Mundial da Saúde (OMS) é garantir a segurança dos
pacientes durante procedimentos cirúrgicos, minimizando
complicações e erros médicos. Esse protocolo inclui uma lista de
verificação a ser utilizada antes, durante e após a cirurgia,
assegurando que todos os passos necessários sejam seguidos.
Sobre esse tema, analise as afirmativas a seguir.
I. Antes da indução anestésica o condutor da lista de verificação deve confirmar que o procedimento e o local da cirurgia estão corretos. II. Antes da incisão cirúrgica deve ser realizada a apresentação de cada membro da equipe pelo nome e função. III. As compressas e os instrumentais cirúrgicos devem ser contados logo após a saída do paciente da sala cirúrgica.
Está correto o que se afirma em
Sobre esse tema, analise as afirmativas a seguir.
I. Antes da indução anestésica o condutor da lista de verificação deve confirmar que o procedimento e o local da cirurgia estão corretos. II. Antes da incisão cirúrgica deve ser realizada a apresentação de cada membro da equipe pelo nome e função. III. As compressas e os instrumentais cirúrgicos devem ser contados logo após a saída do paciente da sala cirúrgica.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571225
Enfermagem
Senhor M. Z., 78 anos, sexo masculino, proveniente de uma casa
de repouso para idosos, encontra-se acamado no leito,
respondendo aos estímulos verbais. No exame físico o
enfermeiro observou uma hiperemia não branqueável em região
sacral.
De acordo com a classificação de lesões da National Pressure Injury Advisory Panel (NPIAP), o exame físico indica haver lesão
De acordo com a classificação de lesões da National Pressure Injury Advisory Panel (NPIAP), o exame físico indica haver lesão
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571224
Enfermagem
O derrame pleural é caracterizado pelo acúmulo anormal de
líquido na cavidade pleural, o espaço entre as membranas que
revestem os pulmões e a parede torácica. Esse acúmulo pode
exercer pressão sobre os pulmões, levando à dificuldade
respiratória e desconforto. Nos procedimentos técnicos que
fazem parte do exame físico do tórax, o enfermeiro poderá
identificar algumas alterações.
Sobre esse tema, analise as afirmativas a seguir.
I. Na ausculta dos pulmões, o enfermeiro poderá notar diminuição ou ausência de murmúrios vesiculares sobre a área afetada. II. A percussão do tórax pode revelar um som abafado ou maciço sobre a área onde o derrame está presente, em contraste com o som timpânico normal sobre áreas pulmonares saudáveis. III. Na ausculta dos pulmões, o enfermeiro poderá notar a presença de sibilos sobre a área afetada.
Está correto o que se afirma em
Sobre esse tema, analise as afirmativas a seguir.
I. Na ausculta dos pulmões, o enfermeiro poderá notar diminuição ou ausência de murmúrios vesiculares sobre a área afetada. II. A percussão do tórax pode revelar um som abafado ou maciço sobre a área onde o derrame está presente, em contraste com o som timpânico normal sobre áreas pulmonares saudáveis. III. Na ausculta dos pulmões, o enfermeiro poderá notar a presença de sibilos sobre a área afetada.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571223
Enfermagem
A quimioterapia é um tratamento sistêmico que utiliza
medicamentos chamados quimioterápicos (ou antineoplásicos),
administrados em intervalos regulares. De acordo com a cartilha
"ABC do Câncer", publicada em 2020 pelo Ministério da Saúde, a
quimioterapia possui várias finalidades.
A esse respeito, analise as afirmativas a seguir.
I. Quimioterapia prévia, neoadjuvante ou citorredutora: indicada para a redução de tumores locais e regionalmente avançados que, no momento, são irressecáveis ou não. Tem a finalidade de tornar os tumores ressecáveis ou de melhorar o prognóstico do paciente. II. Quimioterapia adjuvante ou profilática: indicada após o tratamento cirúrgico curativo, quando o paciente não apresenta qualquer evidência de neoplasia maligna detectável por exame físico e exames complementares. III. Quimioterapia curativa: tem a finalidade de curar pacientes com neoplasias malignas para os quais representa o principal tratamento (podendo ou não estar associada à cirurgia e à radioterapia). Alguns tipos de tumores no adulto, assim como vários tipos de tumores que acometem crianças e adolescentes, são curáveis com a quimioterapia. IV. Quimioterapia paliativa: indicada para a paliação de sinais e sintomas que comprometem a capacidade funcional do paciente, mas não repercute, obrigatoriamente, na sua sobrevida. Independente da via de administração, é de duração limitada, tendo em vista a incurabilidade do tumor (doença avançada, recidivada ou metastática), que tende a evoluir a despeito do tratamento aplicado.
Está correto o que se afirma em
A esse respeito, analise as afirmativas a seguir.
I. Quimioterapia prévia, neoadjuvante ou citorredutora: indicada para a redução de tumores locais e regionalmente avançados que, no momento, são irressecáveis ou não. Tem a finalidade de tornar os tumores ressecáveis ou de melhorar o prognóstico do paciente. II. Quimioterapia adjuvante ou profilática: indicada após o tratamento cirúrgico curativo, quando o paciente não apresenta qualquer evidência de neoplasia maligna detectável por exame físico e exames complementares. III. Quimioterapia curativa: tem a finalidade de curar pacientes com neoplasias malignas para os quais representa o principal tratamento (podendo ou não estar associada à cirurgia e à radioterapia). Alguns tipos de tumores no adulto, assim como vários tipos de tumores que acometem crianças e adolescentes, são curáveis com a quimioterapia. IV. Quimioterapia paliativa: indicada para a paliação de sinais e sintomas que comprometem a capacidade funcional do paciente, mas não repercute, obrigatoriamente, na sua sobrevida. Independente da via de administração, é de duração limitada, tendo em vista a incurabilidade do tumor (doença avançada, recidivada ou metastática), que tende a evoluir a despeito do tratamento aplicado.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571222
Enfermagem
O Processo de Enfermagem deve estar fundamentado em
suportes teóricos que podem estar associados entre si, como
Teorias e Modelos de Cuidado, Sistemas de Linguagens
Padronizadas, instrumentos de avaliação de predição de risco
validados, Protocolos baseados em evidências e outros
conhecimentos correlatos, como estruturas teóricas conceituais e
operacionais que fornecem propriedades descritivas, explicativas,
preditivas e prescritivas que lhe servem de base.
A respeito das taxonomias de enfermagem, analise as afirmativas a seguir.
I. Na Classificação de Resultados de Enfermagem NOC (Nursing Outcomes Classification), cada resultado de enfermagem tem uma definição, uma escala de mensuração e uma lista de indicadores associados ao conceito. II. Na Classificação de Intervenções de Enfermagem NIC (Nursing Intervention Classification) são apresentadas intervenções que podem ser definidas como qualquer tratamento, com base no julgamento e no conhecimento clínico realizado por um enfermeiro para melhorar os resultados do paciente. III. Na utilização do modelo de sete eixos da Classificação Internacional para a Prática de Enfermagem (CIPE), devem-se incluir apenas os termos do eixo da ação na elaboração do diagnóstico. IV. Na classificação de diagnóstico NANDA-Internacional (NANDA-I) todos os diagnósticos de enfermagem possuem o indicador diagnóstico “fatores de risco”. V. O SNOMED CT (Systematized Nomenclature of Medicine - Clinical Terms) é uma terminologia clínica e sistema de codificação que abrange uma ampla gama de conceitos clínicos, permitindo a padronização da terminologia utilizada em registros de saúde eletrônicos, pesquisas biomédicas e comunicação de informações de saúde.
Está correto o que se afirma em
A respeito das taxonomias de enfermagem, analise as afirmativas a seguir.
I. Na Classificação de Resultados de Enfermagem NOC (Nursing Outcomes Classification), cada resultado de enfermagem tem uma definição, uma escala de mensuração e uma lista de indicadores associados ao conceito. II. Na Classificação de Intervenções de Enfermagem NIC (Nursing Intervention Classification) são apresentadas intervenções que podem ser definidas como qualquer tratamento, com base no julgamento e no conhecimento clínico realizado por um enfermeiro para melhorar os resultados do paciente. III. Na utilização do modelo de sete eixos da Classificação Internacional para a Prática de Enfermagem (CIPE), devem-se incluir apenas os termos do eixo da ação na elaboração do diagnóstico. IV. Na classificação de diagnóstico NANDA-Internacional (NANDA-I) todos os diagnósticos de enfermagem possuem o indicador diagnóstico “fatores de risco”. V. O SNOMED CT (Systematized Nomenclature of Medicine - Clinical Terms) é uma terminologia clínica e sistema de codificação que abrange uma ampla gama de conceitos clínicos, permitindo a padronização da terminologia utilizada em registros de saúde eletrônicos, pesquisas biomédicas e comunicação de informações de saúde.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571221
Enfermagem
Na interseção entre teoria e prática, o Processo de Enfermagem é
um elemento central na atuação profissional da enfermagem.
Este processo é embasado por teorias que moldam e influenciam
a Ciência da Enfermagem.
Considerando os conceitos metaparadigmáticos essenciais para a enfermagem, os elementos que compõem o núcleo da profissão são:
Considerando os conceitos metaparadigmáticos essenciais para a enfermagem, os elementos que compõem o núcleo da profissão são:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571220
Enfermagem
A Resolução COFEN nº 736/2024 esclarece as atribuições que
competem à equipe de enfermagem. Com base nessa Resolução,
assinale a opção que se refere corretamente às atividades
atribuídas exclusivamente ao enfermeiro e às responsabilidades
dos técnicos e auxiliares de enfermagem no processo,
respectivamente.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571219
Enfermagem
Processo de Enfermagem é o instrumento metodológico que
orienta o cuidado profissional de enfermagem e a documentação
clínica. De acordo com a Resolução COFEN nº 736/2024, a etapa
do Processo de Enfermagem em que o enfermeiro faz a
identificação de problemas existentes, condições de
vulnerabilidades ou disposições para melhorar comportamentos
de saúde é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571218
Enfermagem
De acordo com a Resolução COFEN nº 736/2024, que dispõe
sobre a implementação do Processo de Enfermagem (PE) em
todos os contextos socioambientais onde ocorre o cuidado de
enfermagem, o PE organiza-se em cinco etapas interrelacionadas, interdependentes, recorrentes e cíclicas.
Assinale a opção que apresenta, na sequência correta, as cinco etapas do Processo de Enfermagem.
Assinale a opção que apresenta, na sequência correta, as cinco etapas do Processo de Enfermagem.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Enfermagem |
Q2571217
Enfermagem
O Capítulo III do Título V da Lei n° 8.080/90 se refere ao
planejamento e ao orçamento do SUS.
Avalie, com base na referida Lei, se as afirmativas a seguir são falsas (F) ou verdadeiras (V).
( ) O processo de planejamento e orçamento do Sistema Único de Saúde (SUS) será descendente, do nível federal até o local, ouvidos seus órgãos deliberativos, compatibilizando-se as necessidades da política de saúde com a disponibilidade de recursos em planos de saúde dos Municípios, dos Estados, do Distrito Federal e da União. ( ) Os planos de saúde serão a base das atividades e programações de cada nível de direção do SUS, e seu financiamento será previsto na respectiva proposta orçamentária. ( ) É vedada a transferência de recursos para o financiamento de ações não previstas nos planos de saúde, exceto em situações emergenciais ou de calamidade pública, na área de saúde. ( ) O Conselho Nacional de Saúde estabelecerá as diretrizes a serem observadas na elaboração dos planos de saúde, em função das características epidemiológicas e da organização dos serviços em cada jurisdição administrativa.
As afirmativas são, respectivamente,
Avalie, com base na referida Lei, se as afirmativas a seguir são falsas (F) ou verdadeiras (V).
( ) O processo de planejamento e orçamento do Sistema Único de Saúde (SUS) será descendente, do nível federal até o local, ouvidos seus órgãos deliberativos, compatibilizando-se as necessidades da política de saúde com a disponibilidade de recursos em planos de saúde dos Municípios, dos Estados, do Distrito Federal e da União. ( ) Os planos de saúde serão a base das atividades e programações de cada nível de direção do SUS, e seu financiamento será previsto na respectiva proposta orçamentária. ( ) É vedada a transferência de recursos para o financiamento de ações não previstas nos planos de saúde, exceto em situações emergenciais ou de calamidade pública, na área de saúde. ( ) O Conselho Nacional de Saúde estabelecerá as diretrizes a serem observadas na elaboração dos planos de saúde, em função das características epidemiológicas e da organização dos serviços em cada jurisdição administrativa.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570833
Contabilidade Pública
De acordo com o Manual de Demonstrativos Fiscais, a Lei de
Responsabilidade Fiscal determina que o Anexo de Metas Fiscais
conterá, entre outros, a evolução do patrimônio líquido, nos
últimos três exercícios, destacando a origem e a aplicação dos
recursos obtidos com a alienação de ativos.
No Demonstração de Origem e Aplicação dos Recursos Obtidos com a Alienação de Ativos, na linha “Alienação de Bens Móveis”, consta o valor da arrecadação da receita de
No Demonstração de Origem e Aplicação dos Recursos Obtidos com a Alienação de Ativos, na linha “Alienação de Bens Móveis”, consta o valor da arrecadação da receita de
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570830
Contabilidade de Custos
Em março de 2024, uma fábrica de tijolos aumentou a produção
de 1.000 unidades para 1.200 unidades de tijolos. Toda a sua
estrutura permaneceu igual.
No mês houve
No mês houve
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570827
Contabilidade Geral
Uma sociedade empresária presta serviços de consultoria
ambiental.
Em julho de 2024, a sociedade empresária reconheceu R$340.000 a título de salários, do seguinte modo: Jurídico: R$15.000; Secretárias: R$20.000; Auditoria Interna: R$30.000; Recursos Humanos: R$35.000; Contadores: R$40.000; Consultores ambientais : R$200.000.
A sociedade empresária elabora a sua Demonstração do Resultado do Exercício de acordo com o método da função da despesa.
Assinale a opção que indica as despesas de salários reconhecidas como Despesas Gerais e Administrativas no mês.
Em julho de 2024, a sociedade empresária reconheceu R$340.000 a título de salários, do seguinte modo: Jurídico: R$15.000; Secretárias: R$20.000; Auditoria Interna: R$30.000; Recursos Humanos: R$35.000; Contadores: R$40.000; Consultores ambientais : R$200.000.
A sociedade empresária elabora a sua Demonstração do Resultado do Exercício de acordo com o método da função da despesa.
Assinale a opção que indica as despesas de salários reconhecidas como Despesas Gerais e Administrativas no mês.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570826
Contabilidade Geral
Em dezembro de 2023, um restaurante entrou na justiça contra
um fornecedor, que entregou uma encomenda com atraso.
O restaurante pedia R$10.000, por danos materiais.
Em 2024, os advogados do restaurante passaram a considerar a causa como ativo contingente.
Assinale a opção que indica o impacto na Demonstração do Resultado do Exercício do restaurante.
Em 2024, os advogados do restaurante passaram a considerar a causa como ativo contingente.
Assinale a opção que indica o impacto na Demonstração do Resultado do Exercício do restaurante.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570825
Contabilidade Geral
Uma loja de móveis opera em dois segmentos distintos, a venda
de móveis e o financiamento das vendas a prazo. A loja considera
que o ajuste a valor presente é relevante, assim como os efeitos
de sua evidenciação.
Em 31/12/2022, a loja havia reconhecido ajuste a valor presente de R$5.000.
Em 31/12/2023, ela reconheceu, em sua Demonstração do Resultado do Exercício, reversão do ajuste, em decorrência do prazo.
A reversão deve ser reconhecida como
Em 31/12/2022, a loja havia reconhecido ajuste a valor presente de R$5.000.
Em 31/12/2023, ela reconheceu, em sua Demonstração do Resultado do Exercício, reversão do ajuste, em decorrência do prazo.
A reversão deve ser reconhecida como
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570823
Contabilidade Geral
No Balanço Patrimonial de uma sociedade empresária, os direitos
derivados de vendas, adiantamentos ou empréstimos a
sociedades coligadas ou controladas, diretores acionistas ou
participantes no lucro da companhia não são classificados como
ativo realizável a longo prazo quando
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570822
Contabilidade Geral
Em relação ao Balanço Patrimonial de uma sociedade empresária,
assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570821
Contabilidade de Custos
Leia o fragmento a seguir em relação à valoração do estoque.
O custo dos estoques de itens que não são normalmente ______ e de bens ou serviços produzidos e segregados para projetos ______ deve ser atribuído pelo uso da identificação específica dos seus custos individuais.
Assinale a opção cujos itens completam corretamente as lacunas do fragmento acima.
O custo dos estoques de itens que não são normalmente ______ e de bens ou serviços produzidos e segregados para projetos ______ deve ser atribuído pelo uso da identificação específica dos seus custos individuais.
Assinale a opção cujos itens completam corretamente as lacunas do fragmento acima.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570820
Contabilidade Geral
Uma loja de canetas usa o método do custo médio ponderado
fixo para avaliar os seus estoques.
Em maio de 2024, o estoque era avaliado por R$200 e era formado por 20 canetas.
No mês, aconteceram as seguintes movimentações no estoque de canetas:
• 05/05: Compra de 10 canetas por R$12,00 cada. • 10/05: Venda de 15 canetas por R$20,00 cada. • 15/05: Compra de 12 canetas por R$14,00 cada. • 22/05: Venda de 8 canetas por R$25,00 cada. • 25/05: Compra de 4 canetas por R$16,00 cada.
Assinale a opção que indica o lucro bruto apurado com a venda de canetas em 31/05/2024.
Em maio de 2024, o estoque era avaliado por R$200 e era formado por 20 canetas.
No mês, aconteceram as seguintes movimentações no estoque de canetas:
• 05/05: Compra de 10 canetas por R$12,00 cada. • 10/05: Venda de 15 canetas por R$20,00 cada. • 15/05: Compra de 12 canetas por R$14,00 cada. • 22/05: Venda de 8 canetas por R$25,00 cada. • 25/05: Compra de 4 canetas por R$16,00 cada.
Assinale a opção que indica o lucro bruto apurado com a venda de canetas em 31/05/2024.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Contabilidade |
Q2570819
Contabilidade de Custos
Uma loja vende mochilas personalizadas.
Em 02/01/2024, seu estoque tinha a seguinte composição.
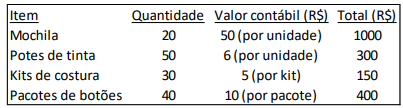
Cada pacote de botões continha 20 botões.
Para personalizar uma mochila eram necessários, além da mochila, 2 potes e meio de tinta, 1 kit de costura e 30 botões. Depois que o material tinha sido utilizado, os botões que sobravam poderiam ser aproveitados para a personalização de outra mochila, mas o pote com a tinta que sobrava era jogado fora.
Cada mochila personalizada era vendida por R$120.
O lucro bruto com a venda de cada mochila era de