Questões de Concurso Para ciência da informação
Foram encontradas 170 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
A entropia de uma árvore de decisão aborda o aspecto da quantidade de informações que está associada às respostas que podem ser obtidas às perguntas formuladas, representando o grau de incerteza associado aos dados.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).
 respectivamente, as médias amostrais das variáveis x e y.
respectivamente, as médias amostrais das variáveis x e y.
Com base nos dados dessa tabela, julgue o próximo item.
Pelo modelo de regressão linear simples, a equação que
expressa o relacionamento ajustado entre a variável y em função de x é 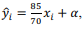 em que α é uma constante.
em que α é uma constante.
respectivamente, as médias amostrais das variáveis x e y.Com base nos dados dessa tabela, julgue o próximo item.
Uma forma de melhorar o modelo de regressão linear para a
situação em questão é utilizar o modelo de regressão
logística, uma vez que a variável dependente se apresenta de
forma quantitativa.