Questões de Concurso
Para tecnologia da informação
Foram encontradas 162.391 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
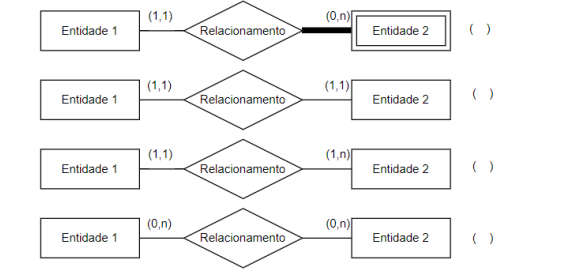
Na modelagem de banco de dados, os mapeamentos de um modelo conceitual de entidade e relacionamento para o modelo lógico seguem alguns princípios e técnicas para manter a integridade dos relacionamentos. Esses mapeamentos podem ser implementados por 3 regras numeradas abaixo:
1. Tabela Própria (Cria-se outra tabela que representará o relacionamento)
2. Adição de Coluna (Cria-se uma coluna adicional em uma das entidades como Chave Estrangeira)
3. Fusão de Tabelas (As duas entidades do relacionamento são fundidas em uma única tabela)
Considere os exemplos de possíveis relacionamentos conceituais, nas opções abaixo, e indique
o número da regra de implementação mais recomendada em cada um dos casos, assinalando
a alternativa que melhor corresponde às regras de implementação indicadas, na ordem de cima
para baixo.

O computador moderno possui vários dispositivos e recursos de memórias para
armazenamento de dados e informação que tradicionalmente podem ser representados em
uma hierarquia de memórias, através da figura abaixo. Sobre a hierarquia de memórias, analise
as seguintes alternativas, assinalando a alternativa ERRADA.
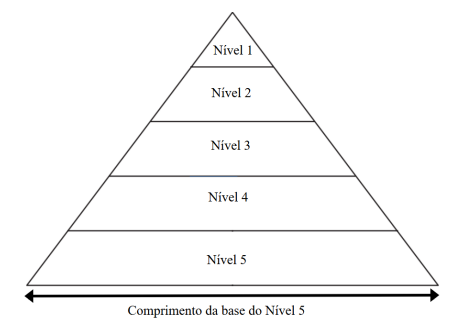
Figura adaptada de TANENBAUM, A. Organização Estruturada de Computadores. 6ª edição. Pearson, 2013
Considere as funções abaixo e determine a complexidade do algoritmo de ordenação da
função “ordena”, usando a notação Big-O;

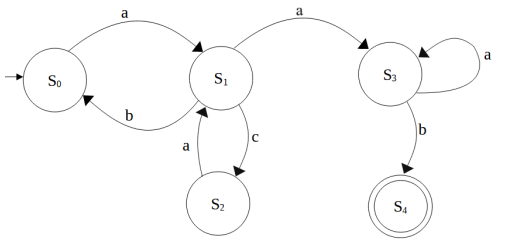
Considerando a Teoria da Computação para expressões regulares, qual expressão pode ser utilizada para representar o seguinte Autômato Finito Determinístico (AFD):´
Obs: para essa questão, foi utilizada a notação de teoria da computação no estudo das propriedades de linguagens regulares:
● União: U
● Estrela: *
● Concatenação: ° (que pode estar implícito)

Acerca do fluxo de Big Data, julgue o item que se segue.
Na etapa de captura de Big Data, grandes volumes de dados
são armazenados em bancos de dados NoSQL, devido à sua
escalabilidade e à sua flexibilidade.
Acerca do fluxo de Big Data, julgue o item que se segue.
As funções do MapReduce transformam um volume grande
de dados em grupamentos segmentados, mantendo na saída
a mesma quantidade de dados da entrada.
Acerca do fluxo de Big Data, julgue o item que se segue.
O serviço ElasticSearch utiliza índices divididos em
fragmentos, de maneira que cada nó armazena diversos
fragmentos e atua na coordenação das operações nos vários
fragmentos.
Acerca do fluxo de Big Data, julgue o item que se segue.
Streaming processing é uma tecnologia de Big Data
exclusiva para atender processamentos de serviços de
streaming de áudio e vídeo.
Acerca do fluxo de Big Data, julgue o item que se segue.
Na apresentação de dados, a extração de subcoleções e a
consulta de parâmetros permitem a navegação em diversos
cenários da visualização.
A respeito de Big Data, julgue o próximo item.
No processamento ROLAP, bancos de dados relacionais são
utilizados como local de armazenamento para agregação,
enquanto, nos processamentos MOLAP e HOLAP,
utilizam-se bancos de dados multidimensionais.
A respeito de Big Data, julgue o próximo item.
O processo de ELT, devido às suas etapas, exige maior definição
de regras, estruturas e relações do que a abordagem ETL.
A respeito de Big Data, julgue o próximo item.
Subconjunto de um data warehouse, o data mart é
especializado em uma área específica de uma organização.
A respeito de Big Data, julgue o próximo item.
Em um data lake, os dados são depositados em estado bruto,
sem terem passado por qualquer análise e mesmo sem terem
uma governança.
A respeito de Big Data, julgue o próximo item.
Projetos de Big Data, quando necessário, crescem
horizontalmente, com a inclusão de novos nodos, e
verticalmente, com o acréscimo de mais memória.
A respeito de Big Data, julgue o próximo item.
No modelo SaaS (software as a service) da computação em
nuvem utilizado para Big Data, a aplicação e os dados são
gerenciados pelo provedor da nuvem.
A respeito de Big Data, julgue o próximo item.
O YARN (Yet Another Resource Negotiator) é um sistema
de arquivos distribuídos que faz parte do framework Hadoop.
A respeito de Big Data, julgue o próximo item.
A coleta de dados por meio de aplicativos é considerada
explícita, porque o usuário a autoriza.
A respeito de Big Data, julgue o próximo item.
Em Big Data, ruídos consistem em informações extras que
acabam deturpando as análises, enquanto overfitting designa
a interpretação equivocada dos ruídos como dados legítimos.
A respeito de Big Data, julgue o próximo item.
Pipelines de dados apresentam uma única estrutura para o
recebimento dos dados originados de uma fonte não
confiável.
Julgue o próximo item, referente ao processamento de linguagem natural.
Na redução de palavras ao radical, ocorre under-stemming
quando duas palavras separadas são reduzidas erroneamente
à mesma raiz e, com isso, ocorre a perda de distinção
semântica entre palavras com significados diferentes.