Questões de Concurso
Comentadas sobre amostragem em estatística
Foram encontradas 213 questões
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
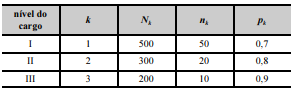
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
Com relação ao grupo k = 2, o erro padrão da estimativa da
proporção dos servidores satisfeitos no ambiente de trabalho
foi inferior a 0,1.
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
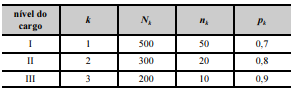
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
O desenho amostral empregado nessa pesquisa foi a
amostragem aleatória estratificada com alocação proporcional
aos tamanhos dos estratos.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
Para a estimação do tempo médio de espera, a fração amostral
adotada na referida situação será superior a 0,12.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
A situação em tela descreve uma amostragem sistemática.
Um pesquisador deseja comparar a diferença entre as médias de duas amostras independentes oriundas de uma ou duas populações gaussianas. Considerando essa situação hipotética, julgue o próximo item.
Caso o pesquisador realize um teste t de Student e encontre
um valor de p = 0,95, considerando-se α = 0,05, será correto
concluir que ambas as amostras provêm da mesma população.
Acerca de métodos usuais de estimação intervalar, julgue o item subsecutivo.
É possível calcular intervalos de confiança para a estimativa
da média de uma distribuição normal, representativa de uma
amostra aleatória
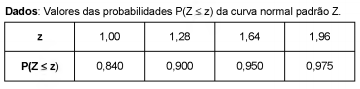
Um curso de treinamento é ministrado para os profissionais de determinado ramo de atividade. A população das notas de
avaliação no curso, que é considerada de tamanho infinito e normalmente distribuída, apresenta uma média μ igual a 7 e variância σ2 igual a 4. Acredita-se que mediante um processo de aperfeiçoamento no curso, essa média tenha sido aumentada. Para
analisar a eficácia desse processo foi extraída uma amostra aleatória de tamanho 64 da população após o processo de
aperfeiçoamento e foram formuladas as hipóteses H0: μ = 7 (hipótese nula) e H1: μ > 7 (hipótese alternativa). O valor encontrado
para a média amostral ( ) foi o maior valor tal que, ao nível de significância de 5%, H0 não foi rejeitada. Tem-se que
) foi o maior valor tal que, ao nível de significância de 5%, H0 não foi rejeitada. Tem-se que  é igual a
é igual a
Sobre população e amostras, assinale a alternativa que completa correta e respectivamente as lacunas do texto.
“A _______________ pode ser definida como um subconjunto, uma parte selecionada da totalidade de observações abrangidas pela_______________ através da qual se faz um juízo ou inferências sobre a característica da população.” (Toledo, G. L., 1985). Já a_______________ congrega todas as observações que sejam relevantes para o estudo da uma ou mais característica dos indivíduos.
Assinale a alternativa que traga, de cima para baixo, a sequência correta.
Em uma espécie de inseto, a probabilidade de um filhote ser do sexo masculino é a mesma de ser do sexo feminino, independentemente dos demais fatores envolvidos.
Uma amostra de filhotes recém-nascidos dessa espécie será utilizada em uma pesquisa e, para que essa amostra seja adequada, ela não pode conter mais que 80% de filhotes do mesmo sexo.
A probabilidade de uma amostra de 6 filhotes não ser adequada para a pesquisa é igual a

Tendo em vista que, diariamente, a Polícia Federal apreende uma quantidade X, em kg, de drogas em determinado aeroporto do Brasil, e considerando os dados hipotéticos da tabela precedente, que apresenta os valores observados da variável X em uma amostra aleatória de 5 dias de apreensões no citado aeroporto, julgue o próximo item.
A tabela em questão descreve a distribuição de frequências da
quantidade de drogas apreendidas nos cinco dias que
constituem a amostra.
Tendo em vista que a abordagem da população sobre o conjunto de unidades amostrais pode ser aleatória, sistemática ou mista, e que, entre esses arranjos estruturais, situam-se os processos de amostragem mais usuais em inventários florestais — amostragem aleatória simples, amostragem estratificada, amostragem sistemática, amostragem em dois estágios e amostragem em conglomerados —, julgue o próximo item, relativo a esses processos de amostragem.
O coeficiente de correlação intraconglomerados (r) é definido
como o grau de similaridade entre subunidades dentro do
conglomerado, podendo assumir valores no intervalo 0 ≤ r ≤ 1;
logo, quando r for igual a 1, não haverá variância entre as
subunidades dos conglomerados, e a variância total será
explicada apenas pela variância entre conglomerados.
Tendo em vista que a abordagem da população sobre o conjunto de unidades amostrais pode ser aleatória, sistemática ou mista, e que, entre esses arranjos estruturais, situam-se os processos de amostragem mais usuais em inventários florestais — amostragem aleatória simples, amostragem estratificada, amostragem sistemática, amostragem em dois estágios e amostragem em conglomerados —, julgue o próximo item, relativo a esses processos de amostragem.
A amostragem em dois estágios é incluída entre os processos
aleatórios irrestritos, pois, nessa amostragem, o segundo
estágio pode ocorrer independentemente do primeiro.
Tendo em vista que a abordagem da população sobre o conjunto de unidades amostrais pode ser aleatória, sistemática ou mista, e que, entre esses arranjos estruturais, situam-se os processos de amostragem mais usuais em inventários florestais — amostragem aleatória simples, amostragem estratificada, amostragem sistemática, amostragem em dois estágios e amostragem em conglomerados —, julgue o próximo item, relativo a esses processos de amostragem.
Comparativamente ao processo de amostragem aleatória
simples, o processo de amostragem estratificada só aumentará
a precisão das estimativas quando houver diferença
significativa entre as médias dos estratos.
O processo de amostragem aleatória simples requer que todas as combinações possíveis de n unidades amostrais da população tenham igual chance de participar da amostra; que a área florestal a ser inventariada seja tratada como uma população única; e que a seleção das amostras possa ser realizada com ou sem reposição.