Questões de Concurso
Sobre gráficos estatísticos - barras ou colunas e histograma em estatística
Foram encontradas 227 questões

O gráfico ilustra cinco possibilidades de fundos de investimento
com suas respectivas rentabilidades. Considerando que as
probabilidades de investimento para os fundos A, B, C e D
sejam, respectivamente, P(A) = 0,182; P(B) = 0,454; P(C) = 0,091;
e P(D) = 0,182, julgue o item subsequente.
O gráfico ilustra cinco possibilidades de fundos de investimento
com suas respectivas rentabilidades. Considerando que as
probabilidades de investimento para os fundos A, B, C e D
sejam, respectivamente, P(A) = 0,182; P(B) = 0,454; P(C) = 0,091;
e P(D) = 0,182, julgue o item subsequente.
O gráfico ilustra cinco possibilidades de fundos de investimento
com suas respectivas rentabilidades. Considerando que as
probabilidades de investimento para os fundos A, B, C e D
sejam, respectivamente, P(A) = 0,182; P(B) = 0,454; P(C) = 0,091;
e P(D) = 0,182, julgue o item subsequente.
O gráfico ilustra cinco possibilidades de fundos de investimento
com suas respectivas rentabilidades. Considerando que as
probabilidades de investimento para os fundos A, B, C e D
sejam, respectivamente, P(A) = 0,182; P(B) = 0,454; P(C) = 0,091;
e P(D) = 0,182, julgue o item subsequente.

Uma empresa coletou e armazenou em um banco de dados diversas informações sobre seus clientes, entre as quais estavam o valor da última fatura vencida e o pagamento ou não dessa fatura. Analisando essas informações, a empresa concluiu que 15% de seus clientes estavam inadimplentes. A empresa recolheu ainda dados como a unidade da Federação (UF) e o CEP da localidade em que estão os clientes. Do conjunto de todos os clientes, uma amostra aleatória simples constituída por 2.175 indivíduos prestou também informações sobre sua renda domiciliar mensal, o que gerou o histograma apresentado.
O CEP da localidade dos clientes e o valor da última fatura vencida são variáveis quantitativas.
Uma empresa coletou e armazenou em um banco de dados diversas informações sobre seus clientes, entre as quais estavam o valor da última fatura vencida e o pagamento ou não dessa fatura. Analisando essas informações, a empresa concluiu que 15% de seus clientes estavam inadimplentes. A empresa recolheu ainda dados como a unidade da Federação (UF) e o CEP da localidade em que estão os clientes. Do conjunto de todos os clientes, uma amostra aleatória simples constituída por 2.175 indivíduos prestou também informações sobre sua renda domiciliar mensal, o que gerou o histograma apresentado.
Na amostra aleatória mencionada, o número de clientes inadimplentes é a realização de uma variável aleatória com distribuição binomial (n = 2.175; p = 0,15).
Uma empresa coletou e armazenou em um banco de dados diversas informações sobre seus clientes, entre as quais estavam o valor da última fatura vencida e o pagamento ou não dessa fatura. Analisando essas informações, a empresa concluiu que 15% de seus clientes estavam inadimplentes. A empresa recolheu ainda dados como a unidade da Federação (UF) e o CEP da localidade em que estão os clientes. Do conjunto de todos os clientes, uma amostra aleatória simples constituída por 2.175 indivíduos prestou também informações sobre sua renda domiciliar mensal, o que gerou o histograma apresentado.
Se for elaborado um histograma com classes de larguras variáveis para representar a distribuição dos valores das últimas faturas vencidas, então a classe com maior altura no histograma será, necessariamente, aquela com maior frequência no banco de dados.
Uma empresa coletou e armazenou em um banco de dados diversas informações sobre seus clientes, entre as quais estavam o valor da última fatura vencida e o pagamento ou não dessa fatura. Analisando essas informações, a empresa concluiu que 15% de seus clientes estavam inadimplentes. A empresa recolheu ainda dados como a unidade da Federação (UF) e o CEP da localidade em que estão os clientes. Do conjunto de todos os clientes, uma amostra aleatória simples constituída por 2.175 indivíduos prestou também informações sobre sua renda domiciliar mensal, o que gerou o histograma apresentado.
Considerando-se a semelhança de comportamento entre clientes novos e clientes atuais já registrados no banco de dados e a invariabilidade da distribuição dos valores das faturas entre UFs, é correto afirmar que a empresa pode identificar as UFs nas quais deve investir para atrair novos clientes pela análise da porcentagem e não do número absoluto de inadimplência por UF.
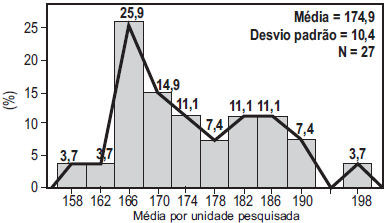
Considerando as informações estatísticas apresentadas no
histograma, conclui-se que o(a)

Com base nas informações fornecidas acima, julgue o próximo item.

coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07

coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07
coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07
coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07
coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07
coeficientes de regressão:
estimate std. error t value Pr(>|t|)(intercept) 11,6624 1,8222 6,400 6,28e-07 ***
tempo 2,1936 0,3347 6,553 4,19e-07 ***---
signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘ * ’ 0,05 ‘ .’ 0,1 ‘ ’ 1
residual standard error: 5,036 on 28 degrees of freedom
multiple R-squared: 0,6053, adjusted R-squared: 0,5912
F-statistic: 42,94 on 1 and 28 DF, p-value: 4,186e-07

AR1 intercepto
0,5217 -0,0589
e.p. 0,0363 0,2309
σ2 = 6,738: logaritmo da verossimilhança = -1305,2,
AIC = 2616,39

AR1 AR2 intercepto
0,9969 -0,9077 -0,0612e.p. 0,0175 0,0173 0,0503
σ2 = 1,149: logaritmo da verossimilhança = -820,46,AIC = 1648,91

São Paulo: Ed. Edgard Blücher, 2004.
Com base nas informações e nas figuras apresentadas, julgue o item seguinte.