Questões de Concurso
Sobre programação linear em estatística
Foram encontradas 76 questões
1 > x <- c(2,1,3,5,6)
2 > y <- matrix(1:25, nrow = 5)
Com base no código precedente, escrito em R, em que os números à esquerda do sinal “>” indicam o número da linha do código, julgue o item a seguir, assumindo que a tecla Enter foi pressionada após cada linha de comando do código.
O comando x == 1:5 produzirá uma lista de valores, dos quais apenas um é TRUE.
Maximizar: Z = 3x1 + x2
Sujeito a
x1 + 2x2 ≤ 24
-x1 + x2 ≤ 6
x1 ≥ 0, x2 ≥ 0
Agora, assinale a função objetivo do dual deste problema
Maximizar: Z = α x1 + βx2
x1<=5
x2<=4
2x1 + 6x2 >=28
x1, x2 >=0
Quais os valores de α e β devem assumir no problema de programação linear acima de forma que este apresente múltiplas soluções possíveis.
Maximizar Z=3x1 + x2
Sujeito as restrições
5x1 + 3x2>=6
4x1 + 2x2>=12
3x1 + 6x2<=30
6x1 + 7x2<=50
x1, x2 >=0
Após observar o problema acima, assinale a solução ótima.
Acerca da Teoria da dualidade, assinale a afirmativa CORRETA:
Considere o conjunto de dados e a informação a seguir:
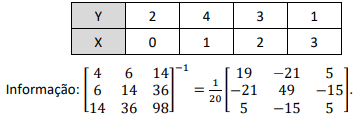
Deseja-se encontrar um modelo de regressão polinomial de 2º grau Y = a0 + a1 X + a2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores de a0, a1 e a2 serão dados, respectivamente, por
A Razão das Chances é definida pela razão entre a probabilidade de sucesso e a probabilidade de insucesso, ou seja, p/1–p. Então, assumindo y = β0 + β1X1 + ... + βp-1Xp-1 = X' β , tem-se no Modelo Logístico p = p(X) = p(X1, X2, ... , Xp-1) = ey/ey+1 = 1/1+e-y= 1/1+e-x'β. Portanto, a Razão das Chances no Modelo Logístico é
Considerando os modelos de otimização de Programação Linear para tomada de decisão, marque a alternativa incorreta.
I Z - 20X - 30Y = 0
II 3X + 2Y - W = 200
III X + 2Y - V = 100
IV X, Y, W, V ≥ 0.
Nessa situação, o valor ótimo de Z e a quantidade ótima de X são, respectivamente, iguais a
Atenção: Para responder à questão, considere o código na linguagem R.
Y<-c(2,3,2,4,3,5,6,3,4) #1
X1<-c(10,13,9,18,12,22,27,13,21) #2
X2<-c(6,10,4,10,10,17,16,9,13) #3
dados<-data.frame(cbind(Y,X1,X2)) #4
modelo <- lm(Y ~ X1 + X2, data = dados) #5
summary(modelo) #6
coef(modelo) #7
formula(modelo) #8
plot(modelo) #9
p <- as.data.frame(cbind(13,4)) #10
colnames(p) <- cbind("X1","X2") #11
predict(modelo, newdata=p) #12
vcov(modelo) #13
Intercept<-rep(1,times=9) #14
X<-cbind(Intercept,X1,X2) #15
t(solve(t(X)%*%X)%*%t(X)%*%Y) #16
residuals(modelo) #17
Atenção: Para responder à questão, considere o código na linguagem R.
Y<-c(2,3,2,4,3,5,6,3,4) #1
X1<-c(10,13,9,18,12,22,27,13,21) #2
X2<-c(6,10,4,10,10,17,16,9,13) #3
dados<-data.frame(cbind(Y,X1,X2)) #4
modelo <- lm(Y ~ X1 + X2, data = dados) #5
summary(modelo) #6
coef(modelo) #7
formula(modelo) #8
plot(modelo) #9
p <- as.data.frame(cbind(13,4)) #10
colnames(p) <- cbind("X1","X2") #11
predict(modelo, newdata=p) #12
vcov(modelo) #13
Intercept<-rep(1,times=9) #14
X<-cbind(Intercept,X1,X2) #15
t(solve(t(X)%*%X)%*%t(X)%*%Y) #16
residuals(modelo) #17
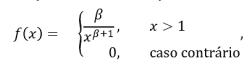
em que β > 1. Se uma amostra aleatória X1, X2, X3, ..., Xn de tamanho n for observada a partir da variável X, o estimador de momentos de β, denotado por FOTO, é dado por:
install.packages(c("readxl","tidyverse","expm","matlib")) #linha 1
lapply(c("readxl","tidyverse","expm","matlib"),require,character.only = TRUE) #linha 2
DADOS <- data.frame(read_excel("C:/Users/fulano/Documents/dados.xlsx")) #linha 3
Modelo <- lm(Altura~Peso,DADOS) #linha 4
predict(Modelo, data.frame(Peso = c(70, 80, 90))) #linha 5
M1<-matrix(c(1,-0.3,-0.3,1.1,0,1,3,4,1,0,-1,4,-6,2),nrow=7,ncol=2,byrow=TRUE) #linha 6
M2 <- matrix(c(1,-0.3,1,3),nrow=2,ncol=2,byrow=TRUE) #linha 7
Matriz_Final<-M1%*%M2 #linha 8
setwd('C:/Users/fulano/Documents/dados') #linha 9
write.csv(Matriz_Final, "Matriz_Final.csv", row.names = FALSE) #linha 10
A respeito das linhas de comando, executadas na sequência das linhas enumeradas, é correto afirmar que o comando da linha
Quando queremos entender a associação de um fator com um evento de interesse, em geral computamos a razão de chances, r = c_0/c_1, onde c_0 é a chance sem a exposição e c_1 é a chance com a exposição.
Suponha que um analista dispõe de um conjunto de dados binários Y = (Y_1,..., Y_n), com Y_i tomando valores em {0, 1} contendo o resultado de um teste de Covid-19 em n pacientes e que X = (X_1, ..., X_n) é um conjunto de covariáveis também binárias que indicam se o indivíduo foi (X_i = 1) ou não (X_i = 0) a uma festa nos últimos dez dias.
O analista quer determinar se a variável X está significativamente associada com o resultado do teste, Y.
Para tanto, ajusta um modelo de regressão logística utilizando Y como variável resposta, um termo de intercepto e X como covariável.
Ele obtém uma estimativa b0 para o intercepto, com erro padrão s0 e, para o coeficiente de X, uma estimativa b1 erro padrão s1.
O intervalo de confiança de 90% para a razão de chances é:
I. Vetores (vectors) são listas de itens que devem ter o mesmo tipo.
II. R trabalha com vários tipos de dados (data types), numéricos, lógicos e textuais, mas as variáveis podem mudar de tipo mesmo depois da instanciação.
III. Os itens de uma lista (list) não podem ser substituídos. São permitidas apenas a inserção e a remoção de itens.
Está correto somente o que se afirma em: