Questões de Concurso Comentadas sobre estatística
Foram encontradas 2.002 questões
Para cada uma das amostras, foram coletadas informações sobre três impostos estaduais, quais sejam, Imposto 1, Imposto 2 e Imposto 3.As hipóteses foram:
H0 : μImposto j;1= μImposto j;2; H1: μImposto j;1 ≠ μImposto j;2
sendo µ a arrecadação média de impostos, j = 1, 2, 3, representando os diferentes impostos e 1 e 2 para os municípios.
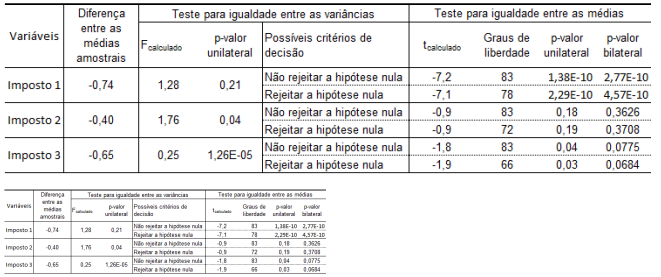
Considere o nível de 7% de significância para todos os testes. Assinale a opção que lista as arrecadações médias que apresentam diferenças significativas.
A série selecionada para o teste não atende à condição supra, pois possui média 66 e variância 144.
Para alterar linearmente a referida série, tornando-a apta a testar o algoritmo, é necessário que cada observação seja:
Lembre que se Z tem distribuição normal padrão então P[Z < 1,64] = 0,95, P[Z < 1,96] = 0,975.
Um intervalo de 95% de confiança para a média populacional será dado aproximadamente por
Se uma amostra aleatória simples de 5 pessoas adultas dessa população for observada, a probabilidade de que mais de 3 tenham sido vacinadas é aproximadamente igual a
Assim, a probabilidade de que A ou B ocorram é igual a
Todos os participantes de um curso foram divididos em 3 grupos (I, II e III). No final de um período, decide-se testar a hipótese, a um determinado nível de significância α, da igualdade das médias das notas dos grupos obtidas em um teste aplicado para todos os participantes. Como o número de participantes era muito grande, optou-se por extrair aleatoriamente de cada grupo 10 observações apurando-se o quadro de análise de variância abaixo, sendo que somente foram fornecidos a “Soma de quadrados Total” e o valor da estatística F utilizada para a tomada de decisão.

Conclui-se que o valor de X é igual a
Atenção: Para responder à questão considere os dados da tabela a seguir, que dá os valores das probabilidades P(Z ≤ z) para a distribuição normal padrão (Z).

Uma variável aleatória X tem uma distribuição normal com média μ e variância 100. Uma amostra aleatória de tamanho n é extraída da respectiva população, com reposição, obtendo-se uma média amostral 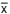 . O valor de n tal que a probabilidade
P( |
. O valor de n tal que a probabilidade
P( |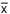 − μ| ≤ 0,656) = 90% é
− μ| ≤ 0,656) = 90% é
Uma indústria vende um equipamento eletrônico que ela produz ao preço unitário de venda de R$ 1.000,00. O custo para a fabri-
cação de cada equipamento é de R$ 400,00 e o tempo (T), em anos, de duração da vida do equipamento é considerado como
uma variável aleatória com uma função densidade de probabilidade igual a 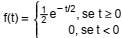 . A indústria garante a
devolução do aparelho caso ele apresente um defeito se t < m/2. O parâmetro real m corresponde à média da duração de vida do
equipamento. O lucro esperado por equipamento, considerando e−0,5 = 0,61, e−1 = 0,37 e e−2 = 0,14, é de
. A indústria garante a
devolução do aparelho caso ele apresente um defeito se t < m/2. O parâmetro real m corresponde à média da duração de vida do
equipamento. O lucro esperado por equipamento, considerando e−0,5 = 0,61, e−1 = 0,37 e e−2 = 0,14, é de
Considere a tabela de renda mensal da Figura 8 abaixo:
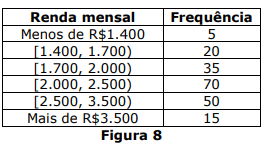
A partir da tabela, calcule o intervalo modal.
I. Em modelos de aprendizado de máquina do tipo classificação a ideia é prever variáveis categóricas, e numéricas.
II. Um exemplo básico de aprendizado de máquina supervisionado por classificação é o uso da regressão logística.
III. Os modelos de regressão não buscam encontrar como uma variável se comporta na medida em que outra variável sofre oscilações.
IV. Nos modelos de aprendizagem de máquina supervisionado, não temos uma variável específica a ser respondida, pois estamos apenas buscando encontrar os indivíduos, itens ou elementos semelhantes.