Questões de Concurso Comentadas sobre estatística
Foram encontradas 2.000 questões
Em determinado município brasileiro, realizou-se um levantamento para estimar o percentual P de pessoas que conhecem o programa justiça itinerante. Para esse propósito, foram selecionados 1.000 domicílios por amostragem aleatória simples de um conjunto de 10 mil domicílios. Nos domicílios selecionados, foram entrevistados todos os residentes maiores de idade, que totalizaram 3.000 pessoas entrevistadas, entre as quais 2.250 afirmaram conhecer o programa justiça itinerante.
De acordo com essa situação hipotética, julgue o seguinte item.
O tamanho da amostra foi igual a 3 mil pessoas maiores de
idade.
Em determinado município brasileiro, realizou-se um levantamento para estimar o percentual P de pessoas que conhecem o programa justiça itinerante. Para esse propósito, foram selecionados 1.000 domicílios por amostragem aleatória simples de um conjunto de 10 mil domicílios. Nos domicílios selecionados, foram entrevistados todos os residentes maiores de idade, que totalizaram 3.000 pessoas entrevistadas, entre as quais 2.250 afirmaram conhecer o programa justiça itinerante.
De acordo com essa situação hipotética, julgue o seguinte item.
O desenho amostral em tela para a estimação do percentual P
denomina-se amostragem por conglomerados na qual a unidade
amostral é o domicílio.
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
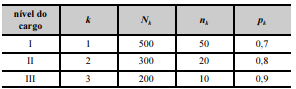
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
A variância da estimativa da proporção populacional de
servidores satisfeitos no ambiente de trabalho foi inferior a
0,004.
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
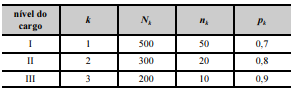
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
Nessa pesquisa, o nível do cargo corresponde à unidade
amostral primária; o servidor representa a unidade amostral
secundária
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
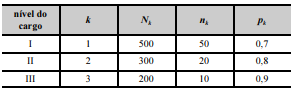
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
Com relação ao grupo k = 2, o erro padrão da estimativa da
proporção dos servidores satisfeitos no ambiente de trabalho
foi inferior a 0,1.
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
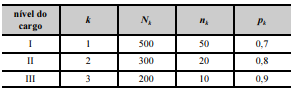
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
O desenho amostral empregado nessa pesquisa foi a
amostragem aleatória estratificada com alocação proporcional
aos tamanhos dos estratos.
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
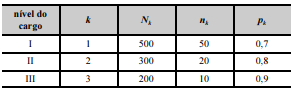
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
A estimativa da proporção populacional de servidores que
estão satisfeitos no ambiente de trabalho foi igual ou superior
a 0,80.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
Se a variância amostral dos tempos de espera for igual a
200 min2
, então a estimativa da variância do tempo médio
amostral será inferior a 2 min².
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
Para a estimação do tempo médio de espera, a fração amostral
adotada na referida situação será superior a 0,12.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
A situação em tela descreve uma amostragem sistemática.
Para estimar a proporção de menores infratores reincidentes em determinado município, foi realizado um levantamento estatístico. Da população-alvo desse estudo, constituída por 10.050 menores infratores, foi retirada uma amostra aleatória simples sem reposição, composta por 201 indivíduos. Nessa amostra foram encontrados 67 reincidentes.
Com relação a essa situação hipotética, julgue o seguinte item.
A estimativa do erro padrão da proporção amostral foi inferior
a 0,04.
No modelo de regressão linear simples na forma matricial Y = Xβ + ε , Y denota o vetor de respostas, X representa a matriz de delineamento (ou matriz de desenho), β é o vetor de coeficientes do modelo e ε é o vetor de erros aleatórios independentes e identicamente distribuídos. Tem-se também que X´Y =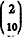 e (X´X) -1 =
e (X´X) -1 =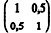 em que X´ é a matriz transposta de X. Com base nessas informações, julgue o próximo item, considerando que a variância do erro aleatório é
em que X´ é a matriz transposta de X. Com base nessas informações, julgue o próximo item, considerando que a variância do erro aleatório é 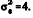
A estimativa do vetor de coeficientes é 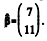
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk ≠ 0.
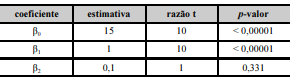
Com base nessas informações e no quadro apresentado, julgue o próximo item.
A hipótese nula H0 : β2 = 0 é rejeitada para o nível
de significância do teste α = 5%.
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk … 0.
Com base nessas informações e no quadro apresentado, julgue o próximo item.
Retirando-se a variável X2, o modelo ajustado é uma reta
de regressão na forma 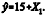
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk … 0.
Com base nessas informações e no quadro apresentado, julgue o próximo item.
A razão t referente à estimativa do coeficiente β2 possui
20 graus de liberdade.
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk … 0.
Com base nessas informações e no quadro apresentado, julgue o próximo item.
A correlação linear entre X1 e X2 é positiva.
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk … 0.
Com base nessas informações e no quadro apresentado, julgue o próximo item.
A estimativa do coeficiente β0, com base no método
de mínimos quadrados ordinários, foi igual a 15.
Um modelo de regressão linear múltipla tem a forma y = β0 + β1X1 + β2X2 + ε, em que β0, β1 e β2 são os coeficientes do modelo e ε denota o erro aleatório normal com média nula e desvio padrão σ. As variáveis regressoras X1 e X2 são ortogonais. O quadro a seguir mostra as estimativas dos coeficientes do modelo obtidas pelo método da máxima verossimilhança a partir de uma amostra de tamanho n = 20. Nesse quadro, para cada coeficiente βk, k = 0, 1, 2, a razão t refere-se ao seu teste de significância H0 : βk = 0 versus H1 : βk … 0.
Com base nessas informações e no quadro apresentado, julgue o próximo item.
O erro padrão da estimativa do coeficiente β1 foi superior
a 0,3
Um estudo considerou um modelo de regressão linear simples na forma y = 0,8x + b + ε, em que y é a variável dependente, x representa a variável explicativa do modelo, o coeficiente b denomina-se intercepto e ε é um erro aleatório que possui média nula e desvio padrão σ. Sabe-se que a variável y segue a distribuição normal padrão e que o modelo apresenta coeficiente de determinação R2 igual a 85%. Com base nessas informações, julgue o item que se segue.
O intercepto do referido modelo é igual ou superior a 0,8
Um estudo considerou um modelo de regressão linear simples na forma y = 0,8x + b + ε, em que y é a variável dependente, x representa a variável explicativa do modelo, o coeficiente b denomina-se intercepto e ε é um erro aleatório que possui média nula e desvio padrão σ. Sabe-se que a variável y segue a distribuição normal padrão e que o modelo apresenta coeficiente de determinação R2 igual a 85%. Com base nessas informações, julgue o item que se segue
O desvio padrão de x é superior a 1.