Questões de Concurso Sobre estatística
Foram encontradas 11.338 questões
Seja o modelo autorregressivo integrado médias móveis ARIMA(2,1,0) representado pela equação
Xt = (1+Ø1 )Xt-1 + (Ø2 - Ø1 )Xt-2 - Ø2 Xt-3 +εt , onde εt ~RB(0, σ2ε ).
O valor da função de autocorrelação no lag 1 da forma estacionária de Xt é dada por
Considere o modelo de séries temporais cuja equação é dada por (1- L)(1+0,4L7 ) Xt =(1-0,3L+1,2L2 )εt , εt ~N(0, σ2ε ), levando em conta polinômios autoregressivos e médias móveis, ambos completos.
Tal modelo é um
Uma empresa de marketing contrata um estatístico para analisar a eficiência de uma propaganda de TV na divulgação de um novo sorvete. O estatístico mostra a propaganda em um bairro específico, por um período de tempo. Após este período, ele escolhe adultos, aleatoriamente, quando saem de um supermercado local, para perguntar se eles “viram a propaganda” e se “compraram o novo sorvete”. O consultor também pergunta qual a “renda familiar anual” e se eles “tinham filhos”. O estatístico precisa determinar como a propaganda, o ter filhos e a renda anual estão relacionadas à compra do sorvete pelos adultos amostrados. Um primeiro modelo de regressão logística binária foi estimado e apresentou os seguintes resultados.
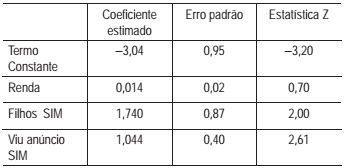
Considerando a Tabela da distribuição normal e um nível
de significância de 5%, verifica-se que as variáveis preditoras
Numa indústria de medicamentos, o processo de envase
de certo medicamento está sob controle. O processo segue
uma distribuição normal centrada com limite superior
de especificação de 12,4 e inferior de 7,0. O desvio padrão
observado é 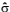 = 0,5.
= 0,5.
Com base na Capacidade do processo, qual o percentual aproximado da amplitude especificada que é utilizada pelo processo?
Uma loja de conveniência, num posto de gasolina, tem um horário peculiar: das 0 horas às 8h da manhã. As chegadas dos clientes seguem um processo de Poisson com taxa de chegada variável segundo a função Λ(t)= t(t +1),t ≥ 0.
O número esperado de clientes que chegam até as 3 horas é, aproximadamente,
Um vendedor de uma determinada empresa pode visitar duas cidades A e B para vender o seu produto. Para ir a essas cidades, ele segue algumas regras: caso ele esteja na cidade A, ele escolhe ir, no dia seguinte, para a cidade B com probabilidade 0,7; se ele estiver na cidade B, ele vai para cidade A com probabilidade 0,6.
A matriz de transição da cadeia de Markov é dada por:
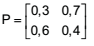
Sabendo-se que a probabilidade de ele estar hoje nas cidades
A e B são iguais, então a probabilidade de ele estar
na cidade B amanhã é
Suponha que os clientes de um supermercado cheguem a um dos caixas de acordo com um processo de Poisson com taxa média λ=4 clientes/hora.
Se o supermercado abre às 7h, a probabilidade de que tenha 5 clientes até as 09h 30min é
Um modelo de regressão linear simples, Y = β0 + β1 X + ε, foi aplicado para explicar o consumo de um certo bem em função da taxa de desemprego. Uma amostra aleatória de tamanho 40 foi selecionada e forneceu a informação de que, para cada elevação de 1% na taxa de desemprego, a demanda diminui em 1.000 unidades. A tabela de ANOVA apresenta informações para testar a significância do modelo, fornecendo a estatística do teste F = 400 com Fsig = 9,0 × 10-22.
O valor da estatística t de Student para o teste da significância de β1 é
Considere o modelo de regressão linear múltipla com intercepto, da variável dependente Y sobre as p variáveis independentes (X1 , X2 , ..., Xp ), na forma matricial:
E(Y) = X.β
Utilizando uma amostra de tamanho n, obtemos o estimador
dos mínimos quadrados ordinários  =(XTX)-1
XTY. Os
valores estimados de Y,
=(XTX)-1
XTY. Os
valores estimados de Y, 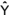 =X
=X , podem ser expressos por
meio de
, podem ser expressos por
meio de 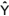 = X.(XTX)-1
XTY.
= X.(XTX)-1
XTY.
Fazendo H = X.(XTX)-1
XT, tem-se 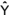 =H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados
=H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados 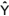 .
.
Diante das considerações feitas acima, observe as afirmações a seguir.:
I - H é uma matriz idempotente.
II -
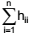 = rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
= rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
III - H.(I – H) = O, onde I é a matriz identidade e O, a matriz nula.
IV - e = (I – H).Y, onde e é o vetor dos resíduos amostrais.
Está correto o que se afirma em:
Uma amostra aleatória simples de tamanho n foi extraída
de modo independente de uma população com distribuição
normal com parâmetros μ e σ, ambos desconhecidos,
a fim de se estimar a variância, σ2
, da característica de
interesse, Y. O estimador de máxima verossimilhança da amostra foi obtido e expresso por 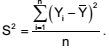
Se 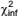 e
e 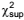 são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
Testes estatísticos de hipóteses constituem modelos probabilísticos de decisão sobre a veracidade de uma afirmativa inicial contraposta à sua alternativa. As decisões sobre a veracidade, ou não, de uma hipótese inicial, podem ser corretas, ou não. Logo, o modelo considera um quadro de diferentes probabilidades.
No que concerne a tais testes, tem-se que a(o)
Uma amostra aleatória de tamanho n deve ser extraída
de uma população infinita a fim de se estimar a proporção
da população, 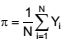 , por meio da estatística
Proporção da Amostra,
, por meio da estatística
Proporção da Amostra, 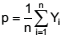 , sendo Yi
uma variável aleatória Bernoulli (π).
, sendo Yi
uma variável aleatória Bernoulli (π).
Na falta de conhecimento prévio da variância do estimador, optou-se por calcular o tamanho da amostra conservador, considerando uma variância máxima, para um nível de confiança de aproximadamente 95%, e um erro amostral absoluto máximo de um ponto percentual.
Com esses parâmetros, o valor mais aproximado para o
tamanho final da amostra é
Uma amostra aleatória de tamanho n > 1 foi extraída independentemente,
sem reposição, de uma população de
tamanho N com distribuição Bernoulli (π ), a fim de se estimar
o total,  , de unidades na população com a característica
A.
, de unidades na população com a característica
A.
Um estimador não tendencioso de  é definido como:
é definido como:
Seja (Y1 , Y2 , Y3 ) uma amostra aleatória simples extraída de modo independente de uma população com média μ e variância σ2 , ambas desconhecidas. Considere os dois estimadores da média da população definidos abaixo:
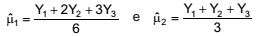
Relativamente a esses dois estimadores, conclui-se que
Uma amostra aleatória de tamanho n deve ser particionada entre L estratos para a estimativa da média populacional μ. O tamanho da amostra para o estrato h, nh , e a respectiva variância do estimador da média, quando o inverso do tamanho do estrato for desprezível, podem ser obtidos por meio de:
I – Amostra Aleatória Simples para cada estrato, com 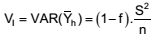
II – repartição proporcional do tamanho final da amostra por 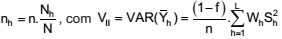
III – repartição segundo Neyman-Tschuprow do tamanho
final da amostra por 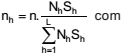
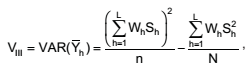
onde f = n/N é a fração amostral, Wh = Nh /N é o tamanho relativo do estrato na população, e Sh é o desvio padrão do estrato h na população.
De acordo com os três critérios de partição da amostra,
podemos inferir que:
Considere um modelo de regressão linear simples de Y, expressa em 1.000 habitantes, e em X, expressa em US$, na forma Y = β0 + β1 X + ε, e suponha que se queira mudar a escala de X para R$ ao câmbio de US$1 = R$ 3,00, mas deixando Y na escala original.
Assim sendo, a repercussão dessa mudança para os valores estimados dos coeficientes linear e angular, bo e b1 , respectivamente, para a variância residual do modelo, S2 , e para o valor da estatística t do teste Ho : β1 = 0 será:
Você dispõe de um montante para investir em ações e precisa decidir em que empresa(s) vai alocar esse montante. Três empresas lhe parecem interessantes, e você resolve consultar o desempenho delas nos últimos sessenta meses para minimizar possíveis riscos da sazonalidade no movimento da Bolsa de Valores. Os dados revelaram a seguinte distribuição, em %, das rentabilidades mensais das ações:
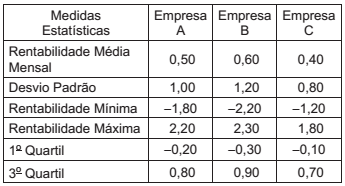
A alocação dos recursos vai ser feita de acordo com a atitude conservadora de não investir em empresa com rentabilidade considerada outlier, entendendo como tal aquela que apresentar valor além de 1,5 desvio quartílico abaixo ou acima dos quartis 1 e 3.
Com base nesse critério, a escolha do investimento deve
recair sobre a(s)
Seja X = (X1 X2 X3
)
t
, com função de densidade 
A densidade condicional de X1
dado X2
é
Seja X uma variável aleatória contínua com função de densidade de probabilidade
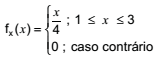
Se Y = X2/ 2 , a função de densidade de probabilidade gY (y) é