Questões de Concurso Sobre estatística
Foram encontradas 11.503 questões
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
STF
Prova:
CESPE - 2013 - STF - Analista Judiciário - Estatística |
Q398076
Estatística
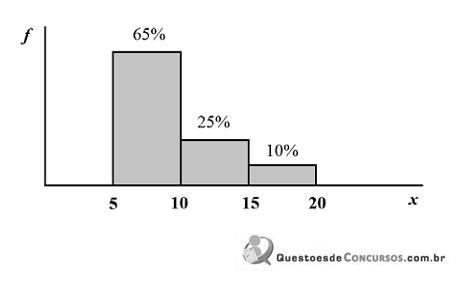
Com referência à figura acima, que mostra a distribuição da renda mensal — x, em quantidades de salários mínimos (sm) — das pessoas que residem em determinada região, julgue o item subsequente.
A variável x, por possuir quatro níveis de respostas, é do tipo qualitativa ordinal.
Ano: 2013
Banca:
CESPE / CEBRASPE
Órgão:
STF
Prova:
CESPE - 2013 - STF - Analista Judiciário - Estatística |
Q398075
Estatística
Com referência à figura acima, que mostra a distribuição da renda mensal — x, em quantidades de salários mínimos (sm) — das pessoas que residem em determinada região, julgue o item subsequente.
Considerando a forma de cálculo para dados agrupados, a distribuição da renda mensal x possui média igual a 9,75 sm.
Q397459
Estatística
Julgue os itens a seguir, relativos às técnicas de amostragem.
Uma dúvida comum entre as pessoas ao observarem os resultados de uma pesquisa eleitoral é acerca da validade dos resultados obtidos com base em uma amostra muito menor frente ao tamanho da população. De fato, essa dúvida procede, pois o tamanho populacional é um dado relevante no cálculo do tamanho mínimo de uma amostra.
Uma dúvida comum entre as pessoas ao observarem os resultados de uma pesquisa eleitoral é acerca da validade dos resultados obtidos com base em uma amostra muito menor frente ao tamanho da população. De fato, essa dúvida procede, pois o tamanho populacional é um dado relevante no cálculo do tamanho mínimo de uma amostra.
Q397458
Estatística
Julgue os itens a seguir, relativos às técnicas de amostragem.
Na amostragem estratificada, a variância dentro dos estratos deve ser pequena, enquanto a variância entre os estratos deve ser grande. Na amostragem por conglomerados, por outro lado, é regra geral que a variância dentro dos conglomerados seja maior que a variância entre os conglomerados.
Na amostragem estratificada, a variância dentro dos estratos deve ser pequena, enquanto a variância entre os estratos deve ser grande. Na amostragem por conglomerados, por outro lado, é regra geral que a variância dentro dos conglomerados seja maior que a variância entre os conglomerados.
Q397457
Estatística
Julgue os itens a seguir, relativos às técnicas de amostragem.
Na amostragem aleatória simples sem reposição (AASc), a probabilidade de seleção de elementos é praticamente igual à probabilidade de seleção caso a amostragem seja com reposição.
Na amostragem aleatória simples sem reposição (AASc), a probabilidade de seleção de elementos é praticamente igual à probabilidade de seleção caso a amostragem seja com reposição.
Q397456
Estatística
Julgue os itens a seguir, relativos às técnicas de amostragem.
No cálculo do tamanho amostral para a comparação de proporções através da expressão
n ≥ 1/4 (z/m)2 em que m é a margem máxima de erro pretendida e z é o quantil da normal padrão que define a significância do teste, a tendência é que as amostras sejam maiores que aquelas calculadas considerando uma abordagem não conservativa.
No cálculo do tamanho amostral para a comparação de proporções através da expressão
n ≥ 1/4 (z/m)2 em que m é a margem máxima de erro pretendida e z é o quantil da normal padrão que define a significância do teste, a tendência é que as amostras sejam maiores que aquelas calculadas considerando uma abordagem não conservativa.
Q397452
Estatística
A respeito dos métodos de análise de resíduos do modelo de regressão, julgue os itens subsequentes.
Na análise de resíduos de um modelo de regressão, o diagrama de dispersão entre os resíduos do modelo ajustado e os valores preditos para a variável resposta permitem avaliar a ocorrência de heterocedasticidade.
Na análise de resíduos de um modelo de regressão, o diagrama de dispersão entre os resíduos do modelo ajustado e os valores preditos para a variável resposta permitem avaliar a ocorrência de heterocedasticidade.
Q397450
Estatística
Com relação à análise de variância para verificação da qualidade de ajuste de um modelo de regressão, julgue os itens seguintes.
Considerando um modelo de regressão no qual a média da variável resposta é aproximadamente zero, se o coeficiente de correlação múltipla (R2 ) tende a 1, então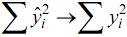
Considerando um modelo de regressão no qual a média da variável resposta é aproximadamente zero, se o coeficiente de correlação múltipla (R2 ) tende a 1, então
Q397449
Estatística
Com relação à análise de variância para verificação da qualidade de ajuste de um modelo de regressão, julgue os itens seguintes.
O coeficiente de correlação múltipla R2 pode ser calculado dividindo a soma de quadrados do resíduo pela soma de quadrado total.
O coeficiente de correlação múltipla R2 pode ser calculado dividindo a soma de quadrados do resíduo pela soma de quadrado total.
Q397448
Estatística
Com relação à análise de variância para verificação da qualidade de ajuste de um modelo de regressão, julgue os itens seguintes.
Em um modelo de regressão linear simples, o quadrado médio associado ao modelo é menor que a respectiva soma de quadrados. O mesmo ocorre com o quadrado médio dos resíduos em comparação com a soma de quadrado dos resíduos.
Em um modelo de regressão linear simples, o quadrado médio associado ao modelo é menor que a respectiva soma de quadrados. O mesmo ocorre com o quadrado médio dos resíduos em comparação com a soma de quadrado dos resíduos.
Q397447
Estatística
Com relação à análise de variância para verificação da qualidade de ajuste de um modelo de regressão, julgue os itens seguintes.
Em uma tabela de análise de variância para a qualidade de ajuste do seguinte modelo de regressão
Yi = β0 + β1 X1 + β2 X2 + ∈i, ∈ i ~N ( 0; σ2 ) se a hipótese nula for rejeitada, então β0 = 0 mas β1 ≠ 0, β2 ≠ 0
Em uma tabela de análise de variância para a qualidade de ajuste do seguinte modelo de regressão
Yi = β0 + β1 X1 + β2 X2 + ∈i, ∈ i ~N ( 0; σ2 ) se a hipótese nula for rejeitada, então β0 = 0 mas β1 ≠ 0, β2 ≠ 0
Q397445
Estatística
Considerando os métodos de inferência para os parâmetros do modelo de regressão, julgue os próximos itens.
Uma medida de alavanca de um modelo de regressão é tal que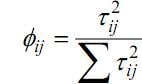 em que tij é o resíduo do modelo de regressão da variável Xi explicada pelas demais variáveis independentes do modelo para a observação j. Supondo um modelo de regressão com 2 variáveis dependentes, no qual apenas k-ésima observação amostral seja influente, se Ø1k > Ø2k então o valor X2k tem um impacto maior que o valor X1k na influência da k-ésima observação.
em que tij é o resíduo do modelo de regressão da variável Xi explicada pelas demais variáveis independentes do modelo para a observação j. Supondo um modelo de regressão com 2 variáveis dependentes, no qual apenas k-ésima observação amostral seja influente, se Ø1k > Ø2k então o valor X2k tem um impacto maior que o valor X1k na influência da k-ésima observação.
Uma medida de alavanca de um modelo de regressão é tal que
em que tij é o resíduo do modelo de regressão da variável Xi explicada pelas demais variáveis independentes do modelo para a observação j. Supondo um modelo de regressão com 2 variáveis dependentes, no qual apenas k-ésima observação amostral seja influente, se Ø1k > Ø2k então o valor X2k tem um impacto maior que o valor X1k na influência da k-ésima observação.
Q397440
Estatística
Com relação aos estimadores de mínimos quadrados e de máxima verossimilhança, julgue os itens seguintes.
Não há garantias de que o estimador de máxima verossimilhança seja não viesado.
Não há garantias de que o estimador de máxima verossimilhança seja não viesado.
Q397438
Estatística
Com relação aos estimadores de mínimos quadrados e de máxima verossimilhança, julgue os itens seguintes.
Se o estimador de mínimos quadrados para os coeficientes de um modelo linear coincidir com o respectivo estimador de máxima verossimilhança, então a distribuição da variável resposta será Normal.
Se o estimador de mínimos quadrados para os coeficientes de um modelo linear coincidir com o respectivo estimador de máxima verossimilhança, então a distribuição da variável resposta será Normal.
Q397437
Estatística
Julgue o item abaixo, sobre a relação entre intervalo de confiança e teste de hipóteses.
Considere que o intervalo de confiança [3, 8] seja usado para testar as hipóteses H0: μ = μ0 versus H1: μ > μ0 Nesse cenário, a hipótese nula será rejeitada somente se μ0 > 8.
Considere que o intervalo de confiança [3, 8] seja usado para testar as hipóteses H0: μ = μ0 versus H1: μ > μ0 Nesse cenário, a hipótese nula será rejeitada somente se μ0 > 8.
Q397436
Estatística
No que se refere a testes de hipóteses, julgue os itens subsecutivos.
O poder de um teste de hipóteses tende a diminuir à medida que o nível de significância decresce.
O poder de um teste de hipóteses tende a diminuir à medida que o nível de significância decresce.
Q397435
Estatística
No que se refere a testes de hipóteses, julgue os itens subsecutivos.
O teste de razão de verossimilhanças generalizadas (TRVG) é uma alternativa ao teste qui-quadrado de Pearson para a avaliação da independência em tabelas de contingência. Sabendo-se que o TRVG considera uma distribuição multinomial, é correto afirmar que a distribuição assintótica da sua estatística do teste possui número de graus de liberdade diferente do número de graus de liberdade da distribuição do teste de Pearson.
O teste de razão de verossimilhanças generalizadas (TRVG) é uma alternativa ao teste qui-quadrado de Pearson para a avaliação da independência em tabelas de contingência. Sabendo-se que o TRVG considera uma distribuição multinomial, é correto afirmar que a distribuição assintótica da sua estatística do teste possui número de graus de liberdade diferente do número de graus de liberdade da distribuição do teste de Pearson.
Q397434
Estatística
No que se refere a testes de hipóteses, julgue os itens subsecutivos.
O tamanho amostral influencia o poder do teste e o nível de significância.
O tamanho amostral influencia o poder do teste e o nível de significância.
Q397433
Estatística
Acerca de intervalos de confiança e de credibilidade, julgue os itens subsequentes.
Em geral, os intervalos de confiança são obtidos com base em uma quantidade pivotal apropriada que segue uma distribuição normal padrão.
Em geral, os intervalos de confiança são obtidos com base em uma quantidade pivotal apropriada que segue uma distribuição normal padrão.
Q397432
Estatística
Acerca de intervalos de confiança e de credibilidade, julgue os itens subsequentes.
Se J1 for o intervalo de confiança de tamanho 1 – α para o parâmetro θ e, se J2 for o intervalo de credibilidade 1 - α para o mesmo parâmetro, então, após selecionar a amostra,P(θ ∈ J1) = P(θ ∈ J2)
Se J1 for o intervalo de confiança de tamanho 1 – α para o parâmetro θ e, se J2 for o intervalo de credibilidade 1 - α para o mesmo parâmetro, então, após selecionar a amostra,P(θ ∈ J1) = P(θ ∈ J2)