Questões de Algoritmos e Estrutura de Dados - Conceitos Básicos de Estrutura de Dados para Concurso
Foram encontradas 271 questões
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
Entre as vantagens do EnKF com relação ao KF e ao EKF, destaca-se a
Com relação a essas dificuldades, analise as afirmativas a seguir.
I. O EKF é o método otimizado para a assimilação de dados sequencial de um modelo dinâmico linear n-dimensional, sendo o KF apropriado apenas para sistemas unidimensionais.
II. O uso do KF e do EKF em modelos dinâmicos que contam com vetores de estados com muitas dimensões requer alta capacidade computacional e de armazenamento, tornando-os práticos apenas para modelos simplificados, de baixa dimensionalidade.
III. A linearização de modelos não lineares envolve a aproximação de funções matemáticas com o truncamento de séries, o que pode gerar erros de propagação de covariâncias, especialmente em modelos de alta dimensionalidade.
Está correto o que se afirma em
Nesse contexto, assinale a opção que indica uma das características do Filtro de Kalman clássico.
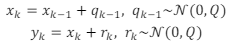
Há dois passos fundamentais para a estimação de estados, onde o primeiro passo está associado ao modelo dinâmico do sistema ou processo, enquanto o segundo passo está associado ao modelo de observações ou sensoriamento.
Neste contexto, os passos são denominados, respectivamente,
Sobre esse método de estimação, assinale a opção correta.
Nesse contexto, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Tanto as Árvores-B+ quanto as Árvores-R são árvores balanceadas. ( ) Em uma Árvore-B+, uma busca por um valor de chave iniciada pelo nó raiz percorre apenas um único caminho até um nó folha (ou terminal). ( ) Em uma Árvore-R, uma busca iniciada pelo nó raiz pode exigir a verificação de mais de uma sub-árvore desse nó raiz para selecionar os itens que satisfazem o critério de busca. ( ) Uma quad-tree sempre é uma árvore balanceada. ( ) Uma das desvantagens de um Árvore-k-d (k-d-tree) é que ela é uma estrutura sensível à ordem nos quais os pontos são inseridos.
As afirmativas são, respectivamente,
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
O método de funcionamento de uma estrutura de dados do tipo pilha, no qual só podem ser retirados os elementos na ordem inversa da ordem em que foram inseridos, é conhecido como:
Estruturas de dados são elementos essenciais no desenvolvimento de soluções, pois permitem dispor e manipular conjuntos de dados de modo específico, permitindo o processamento de dados adequado. Dentre as diversas estruturas de dados existentes, uma delas caracteriza-se por representar um conjunto de objetos e as relações existentes entre eles de modo abstrato, sendo definido por um conjunto de nós ou vértices, e pelas ligações ou arestas, que ligam pares de nós. Assinale a alternativa que apresenta o nome desta estrutura de dados.
As Estruturas de Dados definem a forma como os dados serão armazenados na memória do computador. Duas das estruturas de dados mais utilizadas na computação são a Pilha e a Fila. Considere as afirmativas abaixo que comparam as estruturas de Pilha e Fila:
I - A estrutura chamada Pilha é descrita como uma estratégia LIFO - last in, first out (o último que entra é o primeiro que sai), isto é, os elementos da pilha só podem ser retirados na ordem inversa à ordem que foram introduzidos.
II - A estrutura chamada Fila é descrita como uma estratégia FIFO - first in, first out (o primeiro que entra é o primeiro que sai), isto é, os elementos da pilha só podem ser retirados na mesma ordem em que foram inseridos.
III - Uma estrutura que recebe dos dados 10, 20, 30, 40 e 50 nessa ordem e só permite a sua retirada na ordem 50, 40, 30, 20 e 10 é um exemplo de uma Pilha.
IV - Uma estrutura que recebe dos dados 10, 20, 30, 40 e 50 nessa ordem e só permite a sua retirada na ordem 50, 40, 30, 20 e 10 é um exemplo de uma Fila.
V - Um programa que usa apenas estruturas de Pilha recebe os dados 1, 2, 3, 4 e 5 nessa ordem e imprime os dados na ordem 1, 2, 3, 4 e 5 pode ter sido implementado com duas estruturas de Pilha consecutivas.
As afirmativas CORRETAS são:
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.