Questões de Concurso
Sobre conceitos básicos e algoritmos em algoritmos e estrutura de dados
Foram encontradas 779 questões
Coluna 1
1. Fluxograma. 2. Descrição narrativa. 3. Pseudocódigo ou portugol.
Coluna 2
( ) Consiste em analisar o enunciado do problema e escrever, utilizando uma linguagem natural, os passos a serem seguidos para sua resolução.
( ) Analisa-se o enunciado do problema e se escreve por meio de regras predefinidas os passos a serem seguidos para sua resolução.
( ) Consiste em escrever os passos a serem seguidos para a resolução utilizando símbolos gráficos predefinidos, após analisar o enunciado do problema.
( ) Sua vantagem é que não é necessário aprender nenhum conceito novo, pois uma linguagem já é bem conhecida. Mas a desvantagem é que abre espaço para várias interpretações.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Analise o algoritmo abaixo, o qual foi escrito no software VisuAlg 3.0.

Ao final da execução do algoritmo, qual será o valor da variável “resultado”?
O K-Means, em sua versão original, é classificado como um tipo de algoritmo
algoritmo "Caixa_Registradora" var preco, pagamentoRecebido, total, troco: real quantidadeItens, i: inteiro
inicio // Inicialização das variáveis total <- 0 pagamentoRecebido <- 0 troco <- 0
// Entrada de dados escreva("Digite a quantidade de itens a serem registrados: ") leia(quantidadeItens)
// Loop para ler o preço de cada item para i de 1 ate quantidadeItens faca escreva("Digite o preço do item ", i, ": ") leia(preco) total <- total + preco fimpara
// Exibir o total a ser pago escreva("Total a ser pago: R$", total:0:2)
// Entrada do pagamento recebido escreva("Digite o pagamento recebido: R$") leia(pagamentoRecebido)
// Calcular o troco troco <- pagamentoRecebido - total
// Exibir o troco se troco >= 0 entao escreva("Troco: R$", troco:0:2) senao escreva("Dinheiro insuficiente.") fimse fimalgoritmo
O operador que utiliza a caixa registradora contendo o algoritmo acima registrará os itens listados abaixo, e receberá como pagamento o valor de R$ 200.
• 1 pacote de arroz 5 Kg custando R$ 31,55 a unidade. • 1 pacote de arroz 1 Kg custando R$ 8,19 a unidade. • 2 pacotes de feijão 1 Kg custando R$ 7,39 a unidade.
Na implementação de modelos de interação assíncrona (offline/batch) em processamento de dados, indique a característica principal que os distingue dos modelos síncronos.
O resultado, em binário, encontrado por Daniel é:
Analise o algoritmo abaixo:
ALGORITMO “TESTE”
VAR
X,Y:INTEIRO
INICIO
LEIA(X)
ESCREVA(X)
LEIA(Y)
ESCREVA(Y)
SE (X > Y) ENTAO
ESCREVA(X)
SENAO
ESCREVA(Y)
FIMSE
FIMALGORITMO
Se os valores lidos forem, respectivamente, 7 e 7, quantas vezes o número 7 será escrito pelo
algoritmo?
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

Ao final da execução do algoritmo, qual será o valor da variável "soma"?
( ) Fluxograma e pseudocódigo são formas de representação de algoritmos.
( ) Uma variável do tipo lógico pode assumir um valor verdadeiro ou falso.
( ) Uma atribuição é representada pelo sinal de igual (=).
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
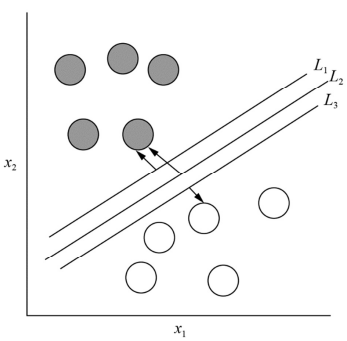
Considerando a figura precedente, assinale a opção correta em
relação ao algoritmo de SVM (support vector machine).
Relacione os métodos de agrupamento hierárquico e o K-means às suas principais características.
1. Agrupamento Hierárquico 2. K-means
( ) Seus resultados são altamente sensíveis ao número de clusters que deve ser pré-definido pelo usuário do algoritmo.
( ) Baseia-se em abordagens top-down ou bottom-up, isto é, com a divisão ou com a união sucessiva de clusters.
( ) Seus resultados costumam ser graficamente visualizados por dendrogramas, que podem ser seccionados de acordo com o número de clusters determinado pelo usuário do algoritmo.
( ) Avalia distâncias entre as instâncias de dados e os centroides dos clusters e atualiza a posição dos centroides dos clusters sucessivamente, até a convergência.
Assinale a opção que indica a relação correta, na ordem apresentada.

Qual forma de representação de algoritmos foi utilizada?

Considerando que o valor lido para a variável Z, no início do algoritmo, tenha sido 7, então o valor impresso de Z, ao final da execução desse algoritmo, será:
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0.

Ao ser executado no VisuAlg 3.0, o algoritmo apresentará um aviso de problema. O que precisará ser
modificado para que o problema seja corrigido?
Abaixo está representada a declaração de uma variável em pseudocódigo (Portugol).
Notas: Vetor [1..10,1..3] de Real
Na declaração acima, quantas posições possui a variável Notas?
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

Ao final da execução do algoritmo acima, qual variável conterá o maior valor numérico?