Questões de Concurso Sobre algoritmos e estrutura de dados
Foram encontradas 3.143 questões
De acordo com a imagem, é correto afirmar:
I. O MD5 não é propriamente um modelo criptográfico, existindo limitações até mesmo de segurança. Seu hash é constituído por uma estrutura hexadecimal de 32 caracteres.
II. O AES (Advanced Encryption Standard) é um algoritmo de criptografia, porém é unidirecional, não permitindo a descriptografia.
III. O RSA (Rivest-Shamir-Adleman) é um algoritmo de criptografia assimétrica bidirecional.
Conforme as assertivas, responda a alternativa verdadeira:
1. (__) Vetores (arrays bidimensionais) e matrizes (arrays unidimensionais) são estruturas de dados que permitem armazenar e manipular coleções de dados de forma eficiente.
2. (__) Fluxogramas são representações gráficas de algoritmos, utilizando símbolos padronizados para denotar diferentes tipos de instruções ou operações (como processos, decisões, entrada/saída de dados, entre outros).
3. (__) Ao utilizar uma sintaxe simplificada e próxima da língua nativa do aprendiz, o Portugol permite uma compreensão mais intuitiva dos conceitos fundamentais de programação, como variáveis, estruturas de controle e lógica de programação.
A sequência CORRETA é:
I - É estável, ou seja, não altera a ordem relativa dos elementos que possuem o mesmo valor de chave de ordenação.
II - Percorre repetidamente a lista a ser ordenada, comparando o elemento corrente com o seguinte e, se necessário, trocando os seus valores.
III - Divide a lista a ser ordenada em duas partes: uma sublista ordenada de elementos, que é construída da esquerda para a direita (ordem crescente), à frente de uma sublista referente aos elementos não ordenados, sendo que, inicialmente, a primeira lista é vazia, enquanto a segunda contém todos os elementos a serem ordenados.
Essas características se aplicam, respectivamente, aos seguintes métodos de ordenação:
A Figura a seguir exibe uma árvore binária.
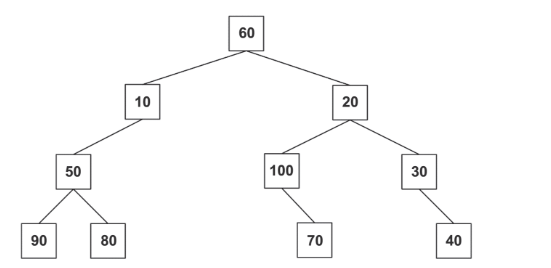
Suponha que uma função percorra essa árvore em ordem simétrica e exiba os valores de seus nós no console.
Um dos possíveis somatórios do 2º , do 3º e do 4º valores exibidos por essa função é
Considerando os algoritmos de substituição de cache mais comuns, Marcos resolverá o problema de desempenho do servidor com o algoritmo:
O algoritmo implementado é o:
O quinto elemento da árvore a ser visitado, quando é realizada uma busca em pré-ordem, é o número:
Em relação a sistemas de gerenciamento de banco de dados não relacionais NoSQL, julgue o item que se segue.
Hashes Redis são coleções não ordenadas de strings
exclusivas que agem como os conjuntos de uma linguagem
de programação; como tal, os hashes Redis assemelham-se
aos dicionários Python, Java HashMaps e Ruby hashes.
Levando em conta os critérios de acesso, busca, inserção e ordenação nas estruturas de dados, Micael identifica que a melhor opção para cumprir esses requisitos é a(o):
Levando em consideração esses requisitos, Gabriel identifica que a estrutura adequada para cumprir tais exigências é a:
É um algoritmo de ordenação simples. Realiza pelo menos n2 comparações para ordenar n elementos. É considerado ineficiente na ordenação de um conjunto muito grande de itens. Pode ser resumido em algumas etapas:
1 - compara dois elementos adjacentes e, quando o primeiro for maior que o segundo, ambos são trocados;
2 - realiza a troca definida em 1 para todos os pares de elementos adjacentes, começando com os dois primeiros e terminando com os dois últimos (n-1 e n). Assim, o último elemento será o maior. 3 - repete o passo 2 para todos os elementos, com exceção do último, sucessivamente.
Relacione os algoritmos populares listados a seguir, às suas respectivas definições.
1. Algoritmos de classificação
2. Algoritmos de clustering
3. Algoritmos de gradient boosting
4. Algoritmos de regressão linear
( ) Usam cálculos preditivos para atribuir dados a categorias
predefinidas.
( ) mostram ou preveem a relação entre duas variáveis ou dois
fatores ajustando uma linha reta contínua aos dados.
( ) Produzem um modelo de previsão que agrupa modelos de
previsão fracos por meio de um processo de ensembling que
aprimora o desempenho geral do modelo
( ) Dividem os dados em vários grupos determinando o nível de
similaridade entre os pontos de dados.
Assinale a opção que indica a relação correta, segundo a ordem
apresentada.

Considere que foram elaboradas duas implementações algorítmicas definidas em linguagem Python (CODIGO-01 e CODIGO-02).
CODIGO-01

CODIGO-02

Quanto às implementações, assinale a afirmativa correta.