Questões de Concurso Sobre algoritmos e estrutura de dados
Foram encontradas 3.208 questões
Ano: 2023
Banca:
FUNDATEC
Órgão:
PROCERGS
Prova:
FUNDATEC - 2023 - PROCERGS - ANC - Analista em Computação - Ênfase em Administração de Dados |
Q2176931
Algoritmos e Estrutura de Dados
Considerando uma tabela hash com fator de carga X, qual é a probabilidade de colisão
em uma inserção, utilizando a função de hash universal?
Ano: 2023
Banca:
FUNDATEC
Órgão:
PROCERGS
Prova:
FUNDATEC - 2023 - PROCERGS - ANC - Analista em Computação - Ênfase em Administração de Dados |
Q2176929
Algoritmos e Estrutura de Dados
Qual é a altura máxima de uma árvore vermelha e preta com N chaves?
Ano: 2023
Banca:
FUNDATEC
Órgão:
PROCERGS
Prova:
FUNDATEC - 2023 - PROCERGS - ANC - Analista em Computação - Ênfase em Administração de Dados |
Q2176928
Algoritmos e Estrutura de Dados
Qual a complexidade de tempo assintótica para buscar um registro em uma árvore
B+ com X chaves e altura Y?
Q2176538
Algoritmos e Estrutura de Dados
A Figura 2, abaixo, apresenta um algoritmo escrito no software VisuAlg 3.0.

Qual será o valor da variável "retorno" ao final da execução do algoritmo da Figura 2?
Q2176537
Algoritmos e Estrutura de Dados
Avalie o trecho de algoritmo abaixo, escrito em pseudocódigo (Portugol), cujo objetivo
é a ordenação de um vetor em ordem crescente. Considere que "v" é um vetor de números inteiros
com 5 posições que foi declarado e preenchido anteriormente, e que “t” é uma variável inteira que
também foi preenchida anteriormente com o tamanho desse vetor.
para j de 1 até t faça para i de 1 até t faça se v[i] > v[i+1] então aux ← v[i] v[i] ← v[i+1] v[i+1] ← aux fimse fimpara fimpara
Caso o operador relacional ">" (maior) fosse trocado pelo operador ">=" (maior ou igual), mais quantas linhas do algoritmo teriam que ser alteradas para que o resultado esperado (ordenação do vetor em ordem crescente) continuasse a ser o mesmo?
para j de 1 até t faça para i de 1 até t faça se v[i] > v[i+1] então aux ← v[i] v[i] ← v[i+1] v[i+1] ← aux fimse fimpara fimpara
Caso o operador relacional ">" (maior) fosse trocado pelo operador ">=" (maior ou igual), mais quantas linhas do algoritmo teriam que ser alteradas para que o resultado esperado (ordenação do vetor em ordem crescente) continuasse a ser o mesmo?
Q2176536
Algoritmos e Estrutura de Dados
Assinale a alternativa que apresenta o tipo de estrutura de dados caracterizada por
um conjunto de dados dispostos por uma sequência de nós, em que a relação de sucessão desses
elementos é determinada por um ponteiro que indica a posição do próximo elemento.
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Laboratório: Área: Informática |
Q2175438
Algoritmos e Estrutura de Dados
Analise, abaixo, as estruturas de dados do tipo árvore, identificadas por A, B e C.
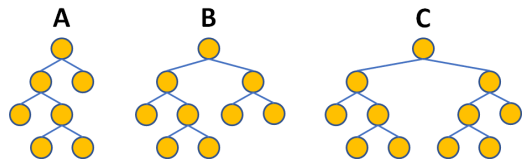
Quais podem ser consideradas árvores balanceadas?
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Tecnologia da Informação |
Q2175404
Algoritmos e Estrutura de Dados
Avalie a estrutura de dados do tipo árvore abaixo:
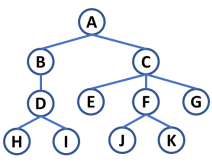
O nó C possui, respectivamente, grau e nível:
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Tecnologia da Informação |
Q2175403
Algoritmos e Estrutura de Dados
Assinale a alternativa que apresenta uma estrutura de dados onde cada nó possui
um elemento com informações, um ponteiro para seu próximo elemento e um ponteiro para seu
elemento anterior.
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Tecnologia da Informação |
Q2175402
Algoritmos e Estrutura de Dados
Sobre a utilização de estruturas de repetição em algoritmos, assinale a alternativa
que apresenta estrutura que executa um conjunto de instruções pelo menos uma vez antes de verificar
a validade da condição estabelecida.
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Tecnologia da Informação |
Q2175401
Algoritmos e Estrutura de Dados
A Figura 1 abaixo apresenta um algoritmo escrito no software VisuAlg 3.0:

Figura 1 – Algoritmo escrito no software VisuAlg 3.0
Qual será o valor da variável "tot" ao final da execução do algoritmo da Figura 1?
Ano: 2023
Banca:
FUNDATEC
Órgão:
IF Farroupilha - RS
Prova:
FUNDATEC - 2023 - IF Farroupilha - RS - Técnico de Tecnologia da Informação |
Q2175400
Algoritmos e Estrutura de Dados
Qual das técnicas abaixo pode ser utilizada para testar a lógica de um algoritmo
quando não se tem disponível uma ferramenta automatizada de depuração?
Ano: 2023
Banca:
FUNDATEC
Órgão:
PROCERGS
Prova:
FUNDATEC - 2023 - PROCERGS - ANC - Analista em Computação - Ênfase em Desenvolvimento Front-End |
Q2172175
Algoritmos e Estrutura de Dados
Uma _________ é uma estrutura de dados linear que apresenta uma série de nós,
cada um contendo um elemento de dados, uma referência para o nó anterior e outra referência para
o próximo nó, permitindo, assim, a manipulação de elementos em ambas as direções.
Assinale a alternativa que preenche corretamente a lacuna do trecho acima.
Assinale a alternativa que preenche corretamente a lacuna do trecho acima.
Ano: 2023
Banca:
IF-MG
Órgão:
IF-MG
Prova:
IF-MG - 2023 - IF-MG - Professor EBTT Área/Disciplina: Controle e Automação |
Q2171372
Algoritmos e Estrutura de Dados
Considere que na entrada do algoritmo PID foi aplicada o sinal 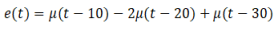 ,
onde
,
onde 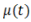 é a função degrau unitário. Sabendo que a equação do algoritmo é
é a função degrau unitário. Sabendo que a equação do algoritmo é
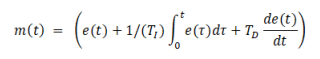
e que a saída do algoritmo é mostrada na figura abaixo (onde o peso dos impulsos corresponde ao seu
tamanho na escala vertical),
do algoritmo é mostrada na figura abaixo (onde o peso dos impulsos corresponde ao seu
tamanho na escala vertical),
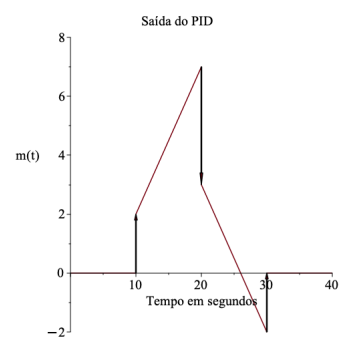
analise as seguintes alternativas:
I. Da figura é possível determinar apenas os valores Kp e Ti .
II. O algoritmo empregado é o PID ISA ou PID ideal, com parâmetros Kp = 2, Ti = 4 e Td = 1 .
III. O algoritmo empregado é o PID paralelo ou clássico, com parâmetros Kp = 2, Ti = 4 e Td = 2.
IV. Da figura é possível determinar os valores Kp, Ti e Td .
V. O algoritmo empregado é o PID ISA ou PID ideal, com parâmetros Kp = 2, Ti = 4 e Td indeterminado.
É(são) correta(s) a(s) afirmativa(s):
,
onde é a função degrau unitário. Sabendo que a equação do algoritmo é e que a saída
do algoritmo é mostrada na figura abaixo (onde o peso dos impulsos corresponde ao seu
tamanho na escala vertical), analise as seguintes alternativas:
I. Da figura é possível determinar apenas os valores Kp e Ti .
II. O algoritmo empregado é o PID ISA ou PID ideal, com parâmetros Kp = 2, Ti = 4 e Td = 1 .
III. O algoritmo empregado é o PID paralelo ou clássico, com parâmetros Kp = 2, Ti = 4 e Td = 2.
IV. Da figura é possível determinar os valores Kp, Ti e Td .
V. O algoritmo empregado é o PID ISA ou PID ideal, com parâmetros Kp = 2, Ti = 4 e Td indeterminado.
É(são) correta(s) a(s) afirmativa(s):
Ano: 2023
Banca:
FUNDATEC
Órgão:
Prefeitura de São João da Urtiga - RS
Prova:
FUNDATEC - 2023 - Prefeitura de São João da Urtiga - RS - Técnico em Informática |
Q2170716
Algoritmos e Estrutura de Dados
O VisuAlg 2.0 prevê quatro tipos de dados. Assinale a alternativa que NÃO representa
um tipo de dados do programa em questão.
Ano: 2023
Banca:
FUNDATEC
Órgão:
Prefeitura de São João da Urtiga - RS
Prova:
FUNDATEC - 2023 - Prefeitura de São João da Urtiga - RS - Técnico em Informática |
Q2170715
Algoritmos e Estrutura de Dados
O VisuAlg é um programa que permite criar, editar, interpretar e que também executa
os algoritmos em portugol (estruturado português) como se fosse um “programa” normal de
computador. Visto isso, interprete o código abaixo e assinale a alternativa que retorna o valor da
variável “A”.
Ano: 2023
Banca:
FGV
Órgão:
PGM - Niterói
Prova:
FGV - 2023 - PGM - Niterói - Analista de Tecnologia da Informação |
Q2167095
Algoritmos e Estrutura de Dados
A analista Carla implementou uma solução algorítmica que
classifica os novos processos submetidos à PGM de Niterói em
níveis de indício de fraude. Para atingir este objetivo, Carla se
baseou no algoritmo de machine learning para classificação que
atribui, necessariamente, um valor no intervalo numérico de 0 a 1
para cada entrada.
Carla utilizou como base o algoritmo de machine learning:
Ano: 2023
Banca:
FGV
Órgão:
PGM - Niterói
Prova:
FGV - 2023 - PGM - Niterói - Analista de Tecnologia da Informação |
Q2167067
Algoritmos e Estrutura de Dados
No contexto da construção de compiladores para linguagens de
programação, o uso da notação polonesa posfixa é comum
quando é necessário representar expressões aritméticas, como a
que segue.
A*(B+C)/D-E
A expressão correta na referida notação é:
A*(B+C)/D-E
A expressão correta na referida notação é:
Ano: 2023
Banca:
FGV
Órgão:
PGM - Niterói
Prova:
FGV - 2023 - PGM - Niterói - Analista de Tecnologia da Informação |
Q2167066
Algoritmos e Estrutura de Dados
No contexto das estruturas de índices do tipo árvores
balanceadas (B-Trees), analise as afirmativas a seguir.
I. Qualquer operação de inserção de uma nova chave implica uma divisão (split) de algum nó. II. Qualquer operação de remoção de uma chave implica uma divisão (split) de algum nó. III. Qualquer operação de remoção de uma chave implica uma concatenação de dois ou mais nós em um.
Está correto o que se afirma em:
I. Qualquer operação de inserção de uma nova chave implica uma divisão (split) de algum nó. II. Qualquer operação de remoção de uma chave implica uma divisão (split) de algum nó. III. Qualquer operação de remoção de uma chave implica uma concatenação de dois ou mais nós em um.
Está correto o que se afirma em:
Ano: 2023
Banca:
FGV
Órgão:
PGM - Niterói
Prova:
FGV - 2023 - PGM - Niterói - Analista de Tecnologia da Informação |
Q2167065
Algoritmos e Estrutura de Dados
João está trabalhando com uma base de dados que contém
centenas de milhares de registros de pessoas, na qual a chave de
busca é o CPF.
Nesse contexto, o algoritmo/método de busca que, corretamente
empregado, oferece a melhor complexidade é: