Questões de Concurso Comentadas sobre banco de dados
Foram encontradas 13.224 questões
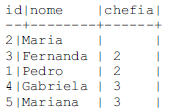
Considere a tabela de colaboradores e o script SQL a seguir.

Nesse caso, executando-se a expressão SQL, tem-se o seguinte resultado.
Julgue o item seguinte, em relação aos conceitos de mapeamento lógico relacional.
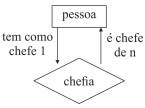
O diagrama de entidade relacionamento a seguir representa a relação entre colaboradores e sua chefia, em que cada chefe pode ter n colaboradores e cada colaborador pode ter muitos chefes.
Julgue o item a seguir, a respeito dos conceitos de modelo entidade-relacionamento.
Um modelo entidade e relacionamento (ER) é formal,
preciso, não ambíguo e pode ser usado como entrada a uma
ferramenta CASE (Computer Aided Software Engineering)
na geração de um banco de dados relacional.
A respeito das técnicas de manipulação e tratamento de dados, julgue o item seguinte.
Normalização linear, também conhecida como normalização
max- min, consiste em estabelecer uma nova base numérica
de referência, obtida a partir do valor de máximo e mínimo
global do conjunto utilizado, para cada dado de um conjunto
de dados.
Em relação aos métodos de visualizações de dados, julgue o item que se segue.
Um dos princípios fundamentais das técnicas de visualização
de dados é o impacto visual, em que as informações com
maior relevância devem ser facilmente distinguidas das
informações de menor relevância.
Em relação aos métodos de visualizações de dados, julgue o item que se segue.
A técnica de comparação controlada (controlled comparison)
de uma visualização de dados é utilizada em visualizações de
dados reduzidos e simples.
(1) criptografia dos dados.
(2) autenticação de dois fatores.
(3) replicação de bancos de dados.
Da relação apresentada:
( ) Os índices nunca utilizam o recurso da busca binária na pesquisa no arquivo de dados.
( ) O índice possui tamanho muito maior do que o tamanho do arquivo de dados.
( ) A existência de índices não afeta a localização física dos registros dos arquivos de dados.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
DROP TABLE ....I... TRTContatos; CREATE TABLE TRTContatos ( cod serial PRIMARY KEY, orgao VARCHAR(255) NOT NULL, email VARCHAR(255) NOT NULL, descricao VARCHAR(255)
);
INSERT INTO TRTContatos (orgao, email)
VALUES ('Ouvidoria','[email protected]:'), ('Escola Judicial','[email protected]'), ('Corregedoria','[email protected]')
....II....;
É correto afirmar que
CodCidade Jurisdicao 32 Picos 11 Teresina 21 Parnaíba 17 Teresina 33 Picos 25 Parnaíba
Para que as cidades cujos CodCidade comecem com 2 tenham a Jurisdicao alterada de Parnaíba para Teresina, deve-se utilizar o seguinte comando PL/SQL:
I. Positivo corretamente sobre o total que de fato era positivo. II. Negativo corretamente sobre o total que de fato era negativo. III. Positivo sobre o total que de fato era negativo. IV. Negativo sobre o total que de fato era positivo.
Os itens de I a IV correspondem, correta e respectivamente, a
I. valores menores que Q3 + 1, 5 ∗ (Q3 − Q1);
II. valores maiores que Q3 + 1, 5 ∗ (Q3 − Q1);
III. valores maiores que Q1 - 1, 5 ∗ (Q3 − Q1);
IV. valores menores que Q1 - 1, 5 ∗ (Q3 − Q1).
Dos itens, verifica-se que está(ão) correto(s) apenas
A linguagem SQL é um meio para se comunicar com o banco de dados, a fim de executar uma determinada operação como incluir registros ou extrair informações. Os comandos SQL podem ser agrupados em categorias de acordo com sua funcionalidade. Considerando os respectivos tipos de categoria de comandos da linguagem SQL, relacione adequadamente as colunas a seguir.
1. DDL (Data Definition Language).
2. DML (Data Manipulation Language).
3. DQL (Data Query Language).
4. DCL (Data Control Language).
( ) Responsável pelo controle de autorização (acesso) dos dados.
( ) Manipulação da estrutura do banco de dados como, por exemplo, criação e alteração de tabelas.
( ) Permite a pesquisa de dados, ou seja, possibilita a consulta de dados por meio do comando SELECT composto por várias cláusulas e opções.
( ) Permite a manutenção dos dados como, por exemplo, inclusão e alteração dos registros de uma tabela.
A sequência está correta em
As principais características de um SGBD são: